
ปัญญาประดิษฐ์
ฝึกอบรมแบบจำลองการมองเห็นด้วยคอมพิวเตอร์บนสัญญาณรบกวนแบบสุ่มแทนภาพจริง

นักวิจัยจากห้องปฏิบัติการวิทยาการคอมพิวเตอร์และปัญญาประดิษฐ์ (CSAIL) ของ MIT ได้ทดลองใช้ภาพสัญญาณรบกวนแบบสุ่มในชุดข้อมูลคอมพิวเตอร์วิทัศน์เพื่อฝึกแบบจำลองคอมพิวเตอร์วิทัศน์ และพบว่า แทนที่จะสร้างขยะ วิธีการกลับได้ผลอย่างน่าประหลาดใจ:

แบบจำลองกำเนิดจากการทดลอง เรียงตามประสิทธิภาพ ที่มา: https://openreview.net/pdf?id=RQUl8gZnN7O
การป้อน 'ขยะภาพ' ที่ชัดเจนลงในสถาปัตยกรรมการมองเห็นของคอมพิวเตอร์ยอดนิยมไม่ควรส่งผลให้เกิดประสิทธิภาพในลักษณะนี้ ที่ด้านขวาสุดของภาพด้านบน คอลัมน์สีดำแสดงถึงคะแนนความแม่นยำ (บน อิมเมจเน็ต-100) สำหรับชุดข้อมูล 'จริง' สี่ชุด แม้ว่าชุดข้อมูล 'สัญญาณรบกวนแบบสุ่ม' ที่อยู่ก่อนหน้า (ภาพเป็นสีต่างๆ ดูที่ดัชนีบนซ้าย) ไม่สามารถจับคู่ได้ ชุดข้อมูลเหล่านี้เกือบทั้งหมดอยู่ในขอบเขตบนและล่างที่น่านับถือ (เส้นประสีแดง) เพื่อความแม่นยำ
ในแง่นี้ 'ความแม่นยำ' ไม่ได้หมายความว่าผลลัพธ์จำเป็นต้องมีลักษณะเหมือน a ใบหน้าที่ โบสถ์ที่ พิซซ่าหรือโดเมนเฉพาะอื่นใดที่คุณอาจสนใจสร้าง การสังเคราะห์ภาพ ระบบ เช่น Generative Adversarial Network หรือเฟรมเวิร์กตัวเข้ารหัส/ตัวถอดรหัส
แต่หมายความว่าโมเดล CSAIL ได้รับ 'ความจริง' กลางที่เกี่ยวข้องในวงกว้างจากข้อมูลรูปภาพ ดังนั้นเห็นได้ชัดว่าไม่มีโครงสร้างซึ่งไม่น่าจะสามารถจัดหาได้
ความหลากหลายเทียบกับ ธรรมชาตินิยม
ไม่สามารถระบุผลลัพธ์เหล่านี้ได้ เกินพอดี: มีชีวิตชีวา การสนทนา ระหว่างผู้เขียนและผู้ตรวจสอบที่ Open Review เผยให้เห็นว่าการผสมเนื้อหาต่างๆ จากชุดข้อมูลที่มองเห็นได้หลากหลาย (เช่น 'ใบไม้ที่ตายแล้ว' 'เศษส่วน' และ 'เสียงรบกวนจากขั้นตอน' – ดูภาพด้านล่าง) ลงในชุดข้อมูลการฝึกอบรม จริง ช่วยเพิ่ม ความถูกต้อง ในการทดลองเหล่านี้
สิ่งนี้ชี้ให้เห็น (และเป็นแนวคิดปฏิวัติเล็กน้อย) รูปแบบใหม่ของ 'ความพอดี' โดยที่ 'ความหลากหลาย' สำคัญกว่า 'ความเป็นธรรมชาติ'
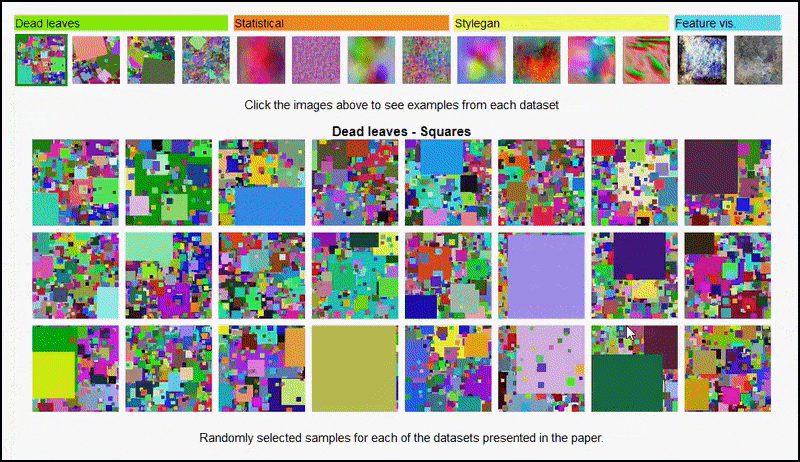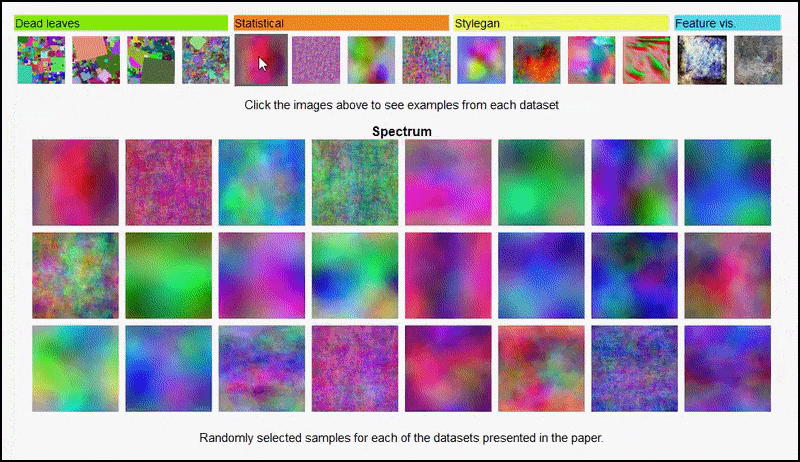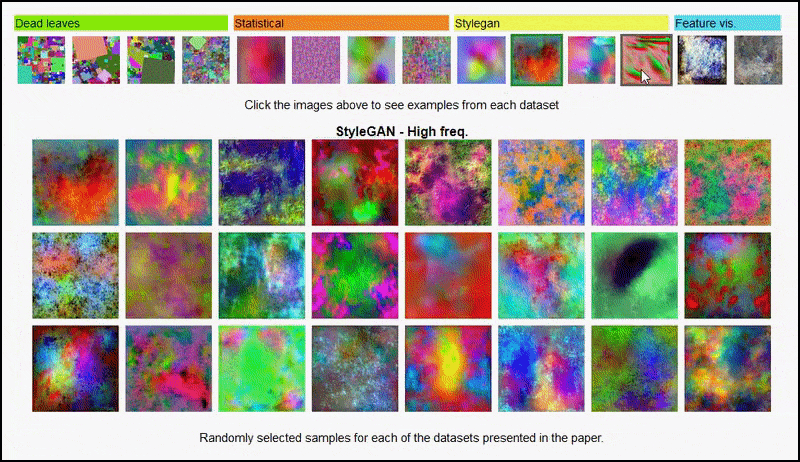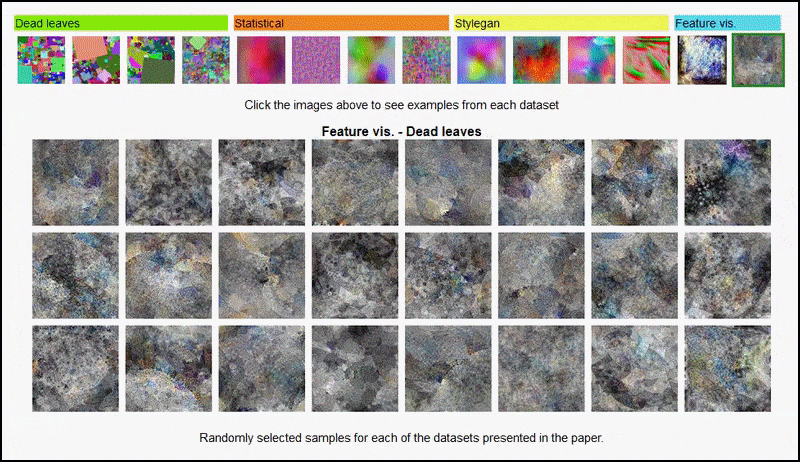
พื้นที่ หน้าโครงการ สำหรับความคิดริเริ่ม ให้คุณดูชุดข้อมูลรูปภาพแบบสุ่มประเภทต่างๆ ที่ใช้ในการทดสอบแบบโต้ตอบได้ ที่มา: https://mbaradad.github.io/learning_with_noise/
ผลลัพธ์ที่นักวิจัยได้รับทำให้เกิดคำถามเกี่ยวกับความสัมพันธ์พื้นฐานระหว่างโครงข่ายประสาทเทียมที่ใช้ภาพกับภาพ 'โลกแห่งความเป็นจริง' ที่ส่งเข้ามาอย่างตื่นตระหนก ปริมาณมากขึ้น ทุกปีและบอกเป็นนัยว่าจำเป็นต้องได้รับ จัดการ และโต้แย้งอย่างอื่น ชุดข้อมูลภาพไฮเปอร์สเกล อาจกลายเป็นความซ้ำซ้อนในที่สุด ผู้เขียนระบุ:
'ระบบวิชันซิสเต็มในปัจจุบันได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูลขนาดใหญ่ และชุดข้อมูลเหล่านี้มีค่าใช้จ่าย: การดูแลจัดการนั้นมีราคาแพง พวกมันสืบทอดอคติของมนุษย์ และมีความกังวลเกี่ยวกับความเป็นส่วนตัวและสิทธิ์การใช้งาน เพื่อลดค่าใช้จ่ายเหล่านี้ ความสนใจจึงพุ่งสูงขึ้นในการเรียนรู้จากแหล่งข้อมูลที่ถูกกว่า เช่น รูปภาพที่ไม่มีป้ายกำกับ
'ในเอกสารฉบับนี้ เราจะก้าวไปอีกขั้นและถามว่าเราสามารถกำจัดชุดข้อมูลภาพจริงทั้งหมดได้หรือไม่ โดยการเรียนรู้จากกระบวนการเสียงรบกวนตามขั้นตอน'
นักวิจัยแนะนำว่าสถาปัตยกรรมการเรียนรู้ของเครื่องจักรในปัจจุบันอาจอนุมานถึงบางสิ่งที่เป็นพื้นฐาน (หรืออย่างน้อยก็ไม่คาดคิด) จากรูปภาพมากกว่าที่คิดไว้ก่อนหน้านี้ และรูปภาพที่ 'ไร้สาระ' อาจให้ความรู้นี้ได้อีกมากมาย ราคาถูก แม้ว่าจะใช้ข้อมูลสังเคราะห์เฉพาะกิจที่เป็นไปได้ก็ตาม ผ่านสถาปัตยกรรมการสร้างชุดข้อมูลที่สร้างภาพแบบสุ่มในเวลาฝึกอบรม:
'เราระบุคุณสมบัติหลักสองประการที่สร้างจากข้อมูลสังเคราะห์ที่ดีสำหรับระบบการมองเห็นในการฝึกอบรม: 1) ความเป็นธรรมชาติ 2) ความหลากหลาย สิ่งที่น่าสนใจคือข้อมูลที่เป็นธรรมชาติที่สุดไม่ได้ดีที่สุดเสมอไป เนื่องจากความเป็นธรรมชาติสามารถแลกมาด้วยความหลากหลาย
'ความจริงที่ว่าข้อมูลที่เป็นธรรมชาติช่วยได้อาจไม่น่าแปลกใจ และมันชี้ให้เห็นว่าข้อมูลจริงจำนวนมากมีค่า อย่างไรก็ตาม เราพบว่าสิ่งที่สำคัญไม่ได้อยู่ที่ข้อมูล จริง แต่ก็นั่นแหละ เหมือนจริงคือต้องจับคุณสมบัติโครงสร้างบางอย่างของข้อมูลจริง
'คุณสมบัติหลายอย่างเหล่านี้สามารถบันทึกได้ในรูปแบบเสียงรบกวนอย่างง่าย'

การแสดงภาพคุณลักษณะที่เกิดจากตัวเข้ารหัสที่ได้มาจาก AlexNet ในชุดข้อมูล 'ภาพสุ่ม' ต่างๆ ที่ใช้โดยผู้เขียน ซึ่งครอบคลุมเลเยอร์ Convolutional ที่ 3 และ 5 (สุดท้าย) วิธีการที่ใช้ในที่นี้เป็นไปตามที่กำหนดไว้ใน การวิจัย AI ของ Google ในปี 2017.
พื้นที่ กระดาษซึ่งนำเสนอในการประชุมครั้งที่ 35 เกี่ยวกับระบบประมวลผลข้อมูลประสาท (NeurIPS 2021) ในซิดนีย์ มีชื่อว่า เรียนรู้ที่จะเห็นโดยมองไปที่เสียงและมาจากนักวิจัยหกคนที่ CSAIL โดยมีส่วนร่วมเท่ากัน
งานคือ แนะนำ โดยความเห็นพ้องต้องกันสำหรับการเลือกที่น่าสนใจในงาน NeurIPS 2021 โดยผู้แสดงความคิดเห็นได้กล่าวถึงบทความนี้ว่าเป็น 'ความก้าวหน้าทางวิทยาศาสตร์' ที่เปิด 'พื้นที่การศึกษาที่ยอดเยี่ยม' แม้ว่าจะมีการตั้งคำถามมากเท่าที่ต้องการคำตอบก็ตาม
ในบทความผู้เขียนสรุปว่า:
'เราได้แสดงให้เห็นว่า เมื่อออกแบบโดยใช้ผลการวิจัยที่ผ่านมาเกี่ยวกับสถิติภาพธรรมชาติ ชุดข้อมูลเหล่านี้สามารถฝึกฝนการแสดงภาพได้สำเร็จ เราหวังว่าเอกสารฉบับนี้จะกระตุ้นให้เกิดการศึกษาแบบจำลองการกำเนิดใหม่ที่สามารถสร้างสัญญาณรบกวนที่มีโครงสร้างและบรรลุประสิทธิภาพที่สูงขึ้นเมื่อใช้ในงานภาพที่หลากหลาย
'เป็นไปได้ไหมที่จะจับคู่ประสิทธิภาพที่ได้รับจาก ImageNet pretraining? บางทีในกรณีที่ไม่มีชุดการฝึกขนาดใหญ่ที่เจาะจงสำหรับงานเฉพาะ การฝึกล่วงหน้าที่ดีที่สุดอาจไม่ได้ใช้ชุดข้อมูลจริงมาตรฐาน เช่น ImageNet'















