
ปัญญาประดิษฐ์
LipSync3D ของ Google ให้การซิงโครไนซ์การเคลื่อนไหวของปาก 'Deepfaked' ที่ได้รับการปรับปรุง

A การทำงานร่วมกัน ระหว่างนักวิจัย AI ของ Google และสถาบันเทคโนโลยีแห่งอินเดีย Kharagpur เสนอเฟรมเวิร์กใหม่เพื่อสังเคราะห์เสียงพูดคุยจากเนื้อหาเสียง โปรเจกต์นี้มีจุดมุ่งหมายเพื่อสร้างวิธีการที่เหมาะสมและใช้ทรัพยากรอย่างสมเหตุสมผลในการสร้างเนื้อหาวิดีโอ 'หัวพูด' จากเสียง เพื่อจุดประสงค์ในการประสานการเคลื่อนไหวของริมฝีปากเข้ากับเสียงพากย์หรือเสียงที่แปลโดยเครื่อง และสำหรับใช้ในอวตาร ในแอปพลิเคชันเชิงโต้ตอบ และอื่นๆ สภาพแวดล้อมตามเวลาจริง

ที่มา: https://www.youtube.com/watch?v=L1StbX9OznY
โมเดลแมชชีนเลิร์นนิงที่ได้รับการฝึกในกระบวนการนี้เรียกว่า LipSync3D ต้องการเพียงวิดีโอเดียวของการระบุใบหน้าเป้าหมายเป็นข้อมูลอินพุต ไปป์ไลน์การเตรียมข้อมูลแยกการแยกรูปทรงใบหน้าออกจากการประเมินแสงและแง่มุมอื่นๆ ของวิดีโออินพุต ทำให้การฝึกอบรมมีความเข้มข้นและประหยัดมากขึ้น
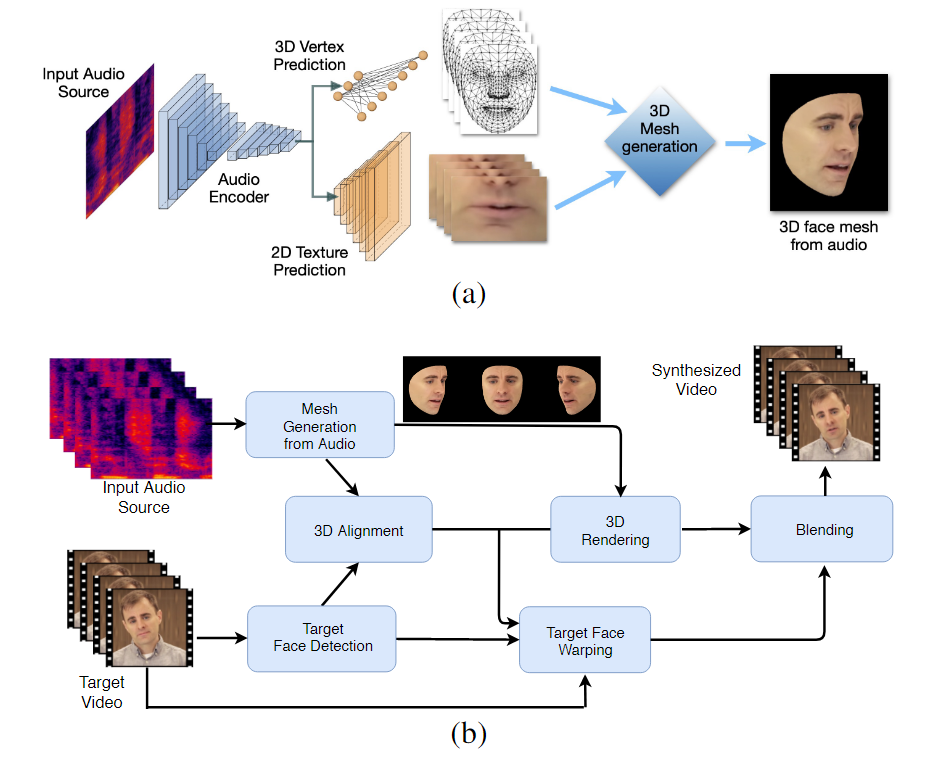
ขั้นตอนการทำงานสองขั้นตอนของ LipSync3D ด้านบน การสร้างใบหน้า 3 มิติที่มีพื้นผิวแบบไดนามิกจากเสียง 'เป้าหมาย'; ด้านล่างเป็นการแทรกตาข่ายที่สร้างขึ้นในวิดีโอเป้าหมาย
ในความเป็นจริง การมีส่วนร่วมที่โดดเด่นที่สุดของ LipSync3D ต่อความพยายามในการวิจัยในด้านนี้อาจเป็นอัลกอริธึมการปรับแสงให้เป็นมาตรฐาน ซึ่งแยกการฝึกอบรมและการอนุมานการส่องสว่างออกจากกัน

การแยกข้อมูลการส่องสว่างออกจากรูปทรงเรขาคณิตทั่วไปช่วยให้ LipSync3D สร้างเอาต์พุตการเคลื่อนไหวของริมฝีปากที่สมจริงยิ่งขึ้นภายใต้สภาวะที่ท้าทาย วิธีการอื่นๆ ในช่วงไม่กี่ปีที่ผ่านมาได้จำกัดตัวเองไว้ที่สภาพแสง 'คงที่' ซึ่งจะไม่เปิดเผยความสามารถที่จำกัดมากกว่านี้ในแง่นี้
ในระหว่างการประมวลผลเฟรมข้อมูลอินพุตล่วงหน้า ระบบจะต้องระบุและลบจุด specular ออก เนื่องจากเป็นจุดเฉพาะสำหรับสภาพแสงที่ใช้ถ่ายวิดีโอ และมิฉะนั้นจะรบกวนกระบวนการจัดแสงใหม่

ตามชื่อของมัน LipSync3D ไม่ได้ทำการวิเคราะห์พิกเซลบนใบหน้าที่ประเมินเท่านั้น แต่ใช้จุดสังเกตบนใบหน้าที่ระบุอย่างแข็งขันเพื่อสร้างตาข่ายสไตล์ CGI ที่เคลื่อนไหวได้ ร่วมกับพื้นผิว 'กางออก' ที่พันรอบพวกเขาด้วย CGI แบบดั้งเดิม ท่อส่ง

สร้างมาตรฐานใน LipSync3D ทางด้านซ้ายคือเฟรมอินพุตและคุณสมบัติที่ตรวจพบ ตรงกลาง จุดยอดปกติของการประเมินเมชที่สร้างขึ้น และด้านขวาคือแผนที่พื้นผิวที่สอดคล้องกัน ซึ่งให้ความจริงพื้นฐานสำหรับการทำนายพื้นผิว ที่มา: https://arxiv.org/pdf/2106.04185.pdf
นอกจากวิธีการจัดแสงใหม่แล้ว นักวิจัยยังอ้างว่า LipSync3D เสนอนวัตกรรมหลักสามประการในงานก่อนหน้านี้ ได้แก่ การแยกรูปทรงเรขาคณิต แสง ท่าทาง และพื้นผิวออกเป็นสตรีมข้อมูลแยกจากกันในพื้นที่ปกติ แบบจำลองการทำนายพื้นผิวถอยหลังอัตโนมัติที่ฝึกได้ง่ายซึ่งสร้างการสังเคราะห์วิดีโอที่สอดคล้องกันชั่วคราว และความสมจริงที่เพิ่มมากขึ้น โดยประเมินจากการประเมินโดยมนุษย์และตัวชี้วัดวัตถุประสงค์

การแยกแง่มุมต่างๆ ของภาพใบหน้าในวิดีโอออกทำให้สามารถควบคุมการสังเคราะห์วิดีโอได้ดียิ่งขึ้น
LipSync3D สามารถรับการเคลื่อนไหวทางเรขาคณิตของริมฝีปากที่เหมาะสมได้โดยตรงจากเสียงโดยการวิเคราะห์หน่วยเสียงและรูปแบบอื่นๆ ของคำพูด และแปลงเป็นท่าทางของกล้ามเนื้อรอบปากที่สอดคล้องกัน

กระบวนการนี้ใช้ไปป์ไลน์การทำนายร่วมกัน โดยที่รูปทรงเรขาคณิตและพื้นผิวที่อนุมานมีตัวเข้ารหัสเฉพาะในการตั้งค่าตัวเข้ารหัสอัตโนมัติ แต่ใช้ตัวเข้ารหัสเสียงร่วมกับเสียงพูดที่กำหนดให้ใช้กับโมเดล:

การสังเคราะห์การเคลื่อนไหวที่ไม่ซับซ้อนของ LipSync3D นั้นมีวัตถุประสงค์เพื่อขับเคลื่อนอวาตาร์ CGI ที่มีสไตล์ ซึ่งผลที่ได้คือข้อมูลตาข่ายและพื้นผิวประเภทเดียวกับภาพในโลกแห่งความเป็นจริงเท่านั้น:
อวาตาร์ 3 มิติที่มีสไตล์มีการเคลื่อนไหวของริมฝีปากที่ขับเคลื่อนแบบเรียลไทม์โดยวิดีโอลำโพงต้นทาง ในสถานการณ์ดังกล่าว ผลลัพธ์ที่ดีที่สุดจะได้รับจากการฝึกอบรมล่วงหน้าส่วนบุคคล
นักวิจัยยังคาดว่าการใช้อวตารด้วยความรู้สึกที่สมจริงขึ้นเล็กน้อย:
![]()
ตัวอย่างเวลาการฝึกสำหรับวิดีโออยู่ในช่วง 3-5 ชั่วโมงสำหรับวิดีโอ 2-5 นาที ในไปป์ไลน์ที่ใช้ TensorFlow, Python และ C++ บน GeForce GTX 1080 เซสชันการฝึกใช้ชุดขนาด 128 เฟรมมากกว่า 500-1000 ยุค โดยแต่ละยุคแสดงถึงการประเมินที่สมบูรณ์ของวิดีโอ

มุ่งสู่การซิงโครไนซ์ใหม่ของการเคลื่อนไหวของริมฝีปาก
สาขาการประสานริมฝีปากใหม่เพื่อรองรับแทร็กเสียงใหม่ ได้รับความสนใจอย่างมากในการวิจัยด้านคอมพิวเตอร์วิทัศน์ในช่วงไม่กี่ปีที่ผ่านมา (ดูด้านล่าง) ไม่น้อยเนื่องจากเป็นผลพลอยได้จากข้อขัดแย้ง เทคโนโลยี Deepfake.
ในปี 2017 มหาวิทยาลัยวอชิงตัน ได้นำเสนองานวิจัย สามารถเรียนรู้การลิปซิงค์จากเสียง ใช้เพื่อเปลี่ยนการเคลื่อนไหวของริมฝีปากของประธานาธิบดีโอบามาในขณะนั้น ในปี 2018; สถาบัน Max Planck for Informatics เป็นผู้นำ โครงการวิจัยอื่น เพื่อเปิดใช้งานข้อมูลระบุตัวตน>การถ่ายโอนวิดีโอระบุตัวตนด้วยลิปซิงค์ ผลพลอยได้จากกระบวนการ; และในเดือนพฤษภาคม ปี 2021 บริษัทสตาร์ทอัพด้าน AI FlawlessAI ได้เปิดเผย TrueSync เทคโนโลยีลิปซิงค์ที่เป็นกรรมสิทธิ์ของตนอย่างกว้างขวาง ที่ได้รับ ในสื่อในฐานะตัวเปิดใช้งานเทคโนโลยีการทำสำเนาที่ได้รับการปรับปรุงสำหรับภาพยนตร์หลักที่เผยแพร่ในภาษาต่างๆ
และแน่นอน การพัฒนาอย่างต่อเนื่องของแหล่งเก็บข้อมูลโอเพ่นซอร์ส Deepfake นั้นเป็นอีกสาขาหนึ่งของการวิจัยที่ผู้ใช้มีส่วนร่วมอย่างแข็งขันในแวดวงของการสังเคราะห์ภาพใบหน้านี้















