ผู้นำทางความคิด
3 วิธีในการรักษาความสดใหม่ของข้อเท็จจริงที่เก่าไปในโมเดลภาษาขนาดใหญ่
โมเดลภาษาขนาดใหญ่ (LLM) เช่น GPT3, ChatGPT และ BARD เป็นที่นิยมอย่างมากในปัจจุบัน ทุกคนมีความคิดเห็นเกี่ยวกับวิธีการที่เครื่องมือเหล่านี้ดีหรือไม่ดีสำหรับสังคมและสิ่งที่พวกเขาหมายถึงสำหรับอนาคตของ AI Google ได้รับการวิพากษ์วิจารณ์อย่างมากเกี่ยวกับโมเดลใหม่ของ BARD ที่ตอบคำถามที่ซับซ้อนผิด (เล็กน้อย) เมื่อถาม “คุณสามารถบอกเรื่องราวใหม่ๆ จากกล้องโทรทรรศน์อวกาศเจมส์ เว็บให้เด็กอายุ 9 ขวบได้หรือไม่” – ชัตบอทให้คำตอบ 3 ข้อ โดย 2 ข้อถูกต้องและ 1 ข้อผิด คำตอบที่ผิดคือว่า “ภาพแรกของดาวเคราะห์นอกระบบ” ถูกถ่ายโดย JWST ซึ่งไม่ถูกต้อง ดังนั้น โมเดลจึงมีข้อเท็จจริงที่ไม่ถูกต้องที่เก็บไว้ในฐานความรู้ของมัน สำหรับโมเดลภาษาขนาดใหญ่ให้มีประสิทธิภาพ เราต้องการวิธีการในการอัปเดตข้อเท็จจริงเหล่านี้หรือเพิ่มความรู้ใหม่ให้กับข้อเท็จจริงเหล่านั้น
มา看看กันว่าข้อเท็จจริงถูกเก็บไว้ภายในโมเดลภาษาขนาดใหญ่ (LLM) อย่างไร โมเดลภาษาขนาดใหญ่ไม่ได้เก็บข้อมูลและข้อเท็จจริงในลักษณะแบบดั้งเดิม เช่น ฐานข้อมูลหรือไฟล์ แต่พวกมันได้รับการฝึกอบรมจากข้อมูลข้อความจำนวนมากและได้เรียนรู้รูปแบบและความสัมพันธ์ในข้อมูลนั้น ซึ่งช่วยให้พวกมันสามารถสร้างคำตอบที่เหมือนมนุษย์ต่อคำถาม แต่พวกมันไม่มีที่เก็บข้อมูลเฉพาะสำหรับข้อมูลที่ได้เรียนรู้ เมื่อตอบคำถาม โมเดลจะใช้การฝึกอบรมของมันในการสร้างคำตอบตามข้อมูลที่ได้รับ ข้อมูลและความรู้ที่โมเดลภาษามีคือผลมาจากรูปแบบที่พวกมันเรียนรู้ในข้อมูลที่พวกมันถูกฝึกอบรม ไม่ใช่ผลมาจากการที่พวกมันถูกเก็บไว้ในหน่วยความจำของโมเดลโดยเฉพาะ สถาปัตยกรรม Transformer ซึ่งเป็นพื้นฐานของโมเดลภาษาขนาดใหญ่สมัยใหม่ส่วนใหญ่มีการเข้ารหัสข้อเท็จจริงภายในที่ใช้สำหรับการตอบคำถามที่ถามในพรอมต์

ดังนั้น หากข้อเท็จจริงภายในหน่วยความจำของ LLM ไม่ถูกต้องหรือเก่าไป ข้อมูลใหม่จะต้องถูกให้มาผ่านพรอมต์ พรอมต์คือข้อความที่ส่งไปยัง LLM พร้อมกับคำถามและหลักฐานสนับสนุนที่สามารถเป็นข้อเท็จจริงใหม่หรือข้อเท็จจริงที่ถูกต้องได้ มี 3 วิธีในการเข้าใกล้สิ่งนี้
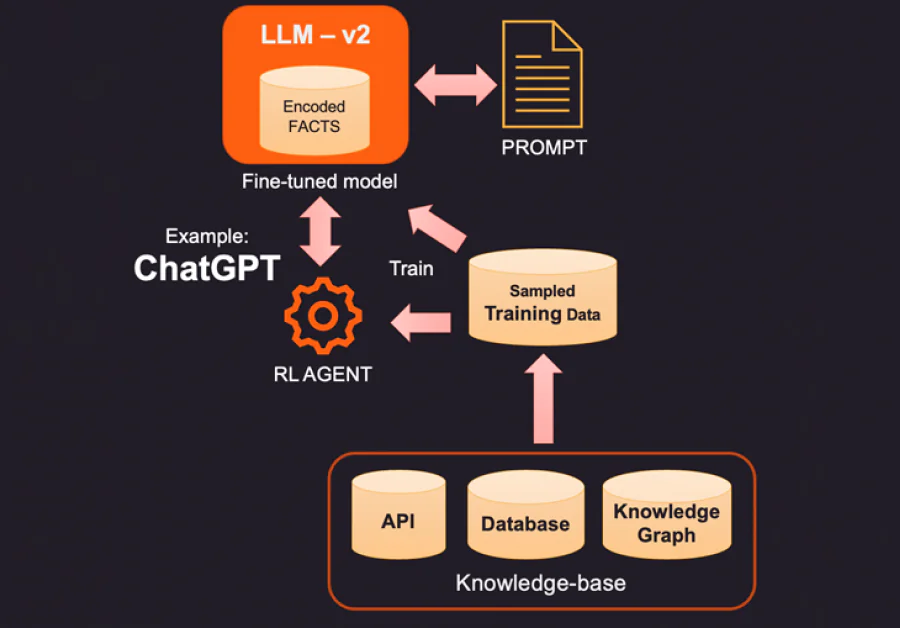
1. วิธีหนึ่งในการแก้ไขข้อเท็จจริงที่ถูกเข้ารหัสของ LLM คือการให้ข้อเท็จจริงใหม่ที่เกี่ยวข้องกับบริบทโดยใช้ฐานความรู้ภายนอก ฐานความรู้นี้อาจเป็น API ที่เรียกเพื่อรับข้อมูลที่เกี่ยวข้องหรือการค้นหาในฐานข้อมูล SQL, No-SQL หรือ Vector ฐานข้อมูลที่มีขั้นสูงสามารถถูกดึงออกมาจากกราฟความรู้ที่เก็บข้อมูลและความสัมพันธ์ระหว่างข้อมูลเหล่านั้น ขึ้นอยู่กับข้อมูลที่ผู้ใช้กำลังถาม ข้อมูลบริบทที่เกี่ยวข้องสามารถถูกดึงออกมาและให้เป็นข้อเท็จจริงเพิ่มเติมให้กับ LLM ข้อเท็จจริงเหล่านี้อาจถูกจัดรูปแบบให้ดูเหมือนตัวอย่างการฝึกอบรมเพื่อปรับปรุงกระบวนการเรียนรู้ ตัวอย่างเช่น คุณสามารถส่งคู่คำถามและคำตอบจำนวนมากให้กับโมเดลเพื่อเรียนรู้วิธีการให้คำตอบ

2. วิธีที่สร้างสรรค์ (และแพง) มากขึ้นในการเพิ่ม LLM คือการปรับให้เหมาะสมโดยใช้ข้อมูลฝึกอบรม ดังนั้น แทนที่จะค้นหาข้อมูลจากฐานความรู้สำหรับข้อเท็จจริงเฉพาะ เราสร้างชุดข้อมูลฝึกอบรมโดยการ取 mẫuจากฐานความรู้ โดยใช้เทคนิคการเรียนรู้แบบมีคำแนะนำ เช่น การปรับให้เหมาะสม เราสามารถสร้างเวอร์ชันใหม่ของ LLM ที่ฝึกอบรมด้วยความรู้เพิ่มเติมได้ กระบวนการนี้มักจะแพงและอาจมีค่าใช้จ่ายหลายพันเหรียญสหรัฐในการสร้างและบำรุงรักษาโมเดลที่ปรับให้เหมาะสมใน OpenAI แน่นอนว่าค่าใช้จ่ายนี้คาดว่าจะลดลงเมื่อเวลาผ่านไป
3. ตัวเลือกอื่นคือการใช้วิธีการเรียนรู้แบบเสริม (RL) เพื่อฝึกตัวแทนโดยใช้คำติชมจากมนุษย์และเรียนรู้นโยบายเกี่ยวกับวิธีการตอบคำถาม วิธีนี้ได้ผลดีในการสร้างโมเดลขนาดเล็กที่ดีในการทำงานเฉพาะ ตัวอย่างเช่น ChatGPT ที่มีชื่อเสียงที่สุดของ OpenAI ถูกฝึกอบรมด้วยการเรียนรู้แบบมีคำแนะนำและ RL โดยมีคำติชมจากมนุษย์

สรุปแล้ว สิ่งนี้เป็นพื้นที่ที่กำลังพัฒนาอย่างรวดเร็ว โดยทุกบริษัทใหญ่ต้องการเข้าร่วมและแสดงความแตกต่าง เราจะเห็นเครื่องมือ LLM ที่สำคัญในหลายพื้นที่ เช่น การค้าปลีก การดูแลสุขภาพ และการธนาคาร ที่สามารถตอบกลับในลักษณะที่เหมือนมนุษย์ โดยเข้าใจถึงความแตกต่างของภาษา เครื่องมือ LLM เหล่านี้ที่รวมกับข้อมูลขององค์กรสามารถทำให้การเข้าถึงและทำให้ข้อมูลที่ถูกต้องพร้อมใช้งานสำหรับคนถูกต้องในเวลาที่เหมาะสมได้












