AI 101
Vad är RNN och LSTM i djupinlärning?
Många av de mest imponerande framstegen inom naturlig språkbehandling och AI-chattbotar drivs av Recurrenta Neurala Nätverk (RNN) och Long Short-Term Memory (LSTM)-nätverk. RNN och LSTM är specialiserade neurala nätverksarkitekturer som kan bearbeta sekventiell data, data där kronologisk ordning spelar roll. LSTM är i princip förbättrade versioner av RNN, kapabla att tolka längre sekvenser av data. Låt oss ta en titt på hur RNN och LSTM är strukturerade och hur de möjliggör skapandet av sofistikerade system för naturlig språkbehandling.
Vad är Feed-Forward Neurala Nätverk?
Så innan vi pratar om hur Long Short-Term Memory (LSTM) och Convolutional Neural Networks (CNN) fungerar, bör vi diskutera formatet på ett neuralt nätverk i allmänhet.
Ett neuralt nätverk är avsett att undersöka data och lära sig relevanta mönster, så att dessa mönster kan tillämpas på annan data och ny data kan klassificeras. Neurala nätverk är indelade i tre sektioner: en inmatningslager, ett dolt lager (eller flera dolda lager) och ett utmatningslager.
Inmatningslagret är vad som tar in data i det neurala nätverket, medan de dolda lagren är vad som lär sig mönster i data. De dolda lagren i datasetet är anslutna till inmatnings- och utmatningslagren genom “vikter” och “bias” som är antaganden om hur datapunkterna är relaterade till varandra. Dessa vikter justeras under träning. När nätverket tränas, jämförs modellens gissningar om träningsdata (utmatningsvärdena) mot de faktiska träningsetiketterna. Under träningsförloppet bör nätverket (hoppas) bli mer exakt i att förutsäga relationer mellan datapunkter, så att det kan klassificera ny data med stor noggrannhet. Djupa neurala nätverk är nätverk som har fler lager i mitten/fler dolda lager. Ju fler dolda lager och neuroner/noder modellen har, desto bättre kan modellen känna igen mönster i data.
Reguljära, feed-forward neurala nätverk, som de jag beskrivit ovan, kallas ofta “täta neurala nätverk”. Dessa täta neurala nätverk kombineras med olika nätverksarkitekturer som specialiserar sig på att tolka olika typer av data.
Vad är RNN (Recurrent Neural Networks)?

Recurrenta Neurala Nätverk tar den allmänna principen för feed-forward neurala nätverk och möjliggör för dem att hantera sekventiell data genom att ge modellen en intern minnesfunktion. Den “Recurrent” delen av RNN-namnet kommer från det faktum att in- och utmatningarna loopas. När utmatningen från nätverket produceras, kopieras utmatningen och returneras till nätverket som inmatning. När ett beslut fattas, analyseras inte bara den aktuella inmatningen och utmatningen, utan även den tidigare inmatningen. För att uttrycka det på ett annat sätt, om den initiala inmatningen för nätverket är X och utmatningen är H, matas både H och X1 (nästa inmatning i datasekvensen) in i nätverket för nästa omgång av lärande. På detta sätt bevaras kontexten i data (tidigare inmatningar) medan nätverket tränas.
Resultatet av denna arkitektur är att RNN kan hantera sekventiell data. Men RNN lider av ett par problem. RNN lider av försvinnande gradient och exploderande gradient problem.
Längden på sekvenser som en RNN kan tolka är ganska begränsad, särskilt i jämförelse med LSTM.
Vad är LSTM (Long Short-Term Memory-nätverk)?
Long Short-Term Memory-nätverk kan betraktas som utvidgningar av RNN, återigen applicerande konceptet att bevara kontexten i inmatningar. Men LSTM har modifierats på flera viktiga sätt som tillåter dem att tolka tidigare data med överlägsna metoder. Ändringarna som gjorts i LSTM hanterar försvinnande gradientproblemet och möjliggör för LSTM att överväga mycket längre inmatningssekvenser.

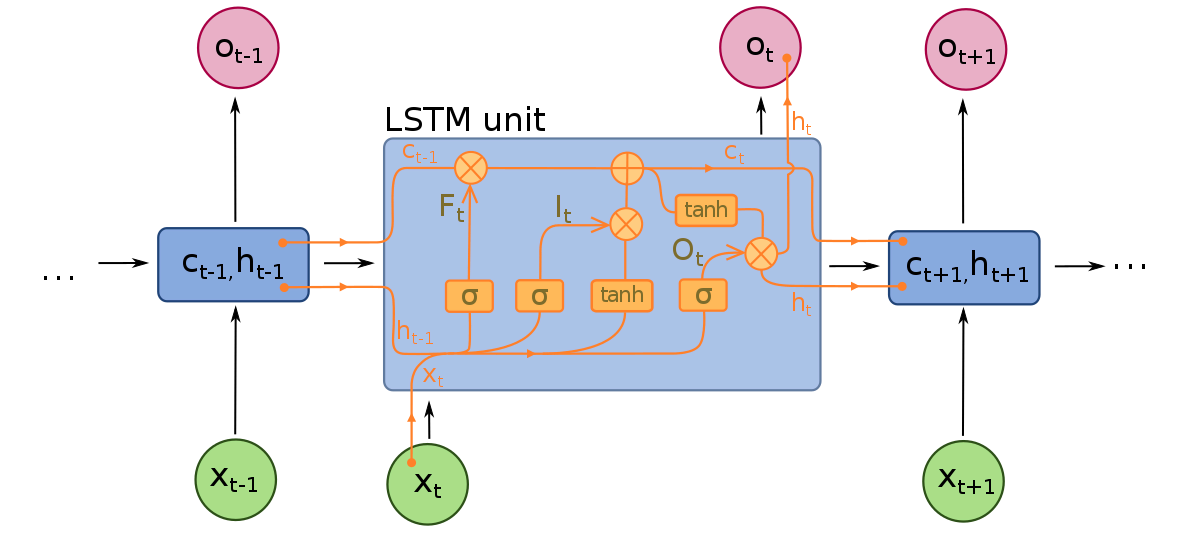
LSTM-modeller består av tre olika komponenter, eller grindar. Det finns en inmatningsgrind, en utmatningsgrind och en glömskegrind. Liksom RNN, tar LSTM inmatningar från den tidigare tidssteget i beaktande när de modifierar modellens minnes- och inmatningsvikter. Inmatningsgrinden fattar beslut om vilka värden som är viktiga och bör släppas igenom modellen. En sigmoidfunktion används i inmatningsgrinden, som fattar beslut om vilka värden som ska skickas vidare genom det rekurrenta nätverket. Noll släpper värden, medan 1 bevarar dem. En TanH-funktion används också här, som bestämmer hur viktiga inmatningsvärdena är för modellen, med värden från -1 till 1.
Efter att nuvarande inmatningar och minnestillstånd har beaktats, bestämmer utmatningsgrinden vilka värden som ska skickas till nästa tidssteg. I utmatningsgrinden analyseras värdena och tilldelas en viktighet som sträcker sig från -1 till 1. Detta reglerar data innan den skickas vidare till nästa tidsstegsberäkning. Slutligen är glömskegrindens uppgift att släppa information som modellen anser är onödig för att fatta ett beslut om inmatningsvärdenas natur. Glömskegrinden använder en sigmoidfunktion på värdena, med utdata mellan 0 (glöm det) och 1 (bevara det).
Ett LSTM-neuralt nätverk består av både specialiserade LSTM-lager som kan tolka sekventiell orddata och tätt anslutna lager som de som beskrivits ovan. När data flyttar genom LSTM-lagren, fortsätter den till de tätt anslutna lagren.








