ИИ 101
Что такое обучение с подкреплением?
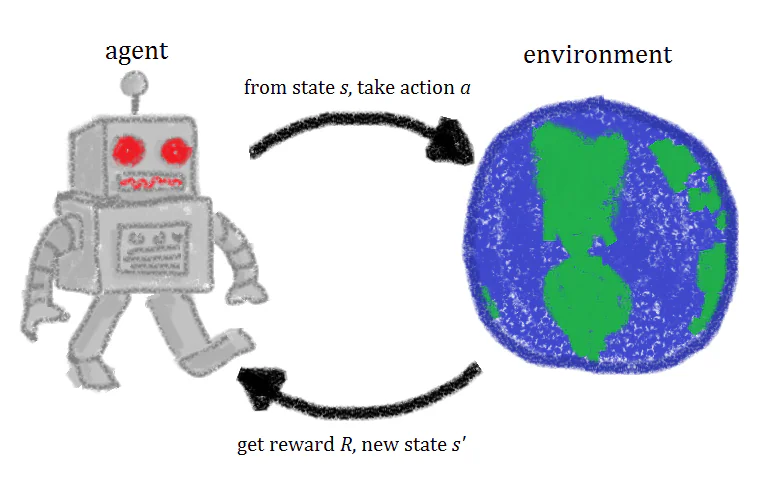
Что такое обучение с подкреплением?
Обучение с подкреплением – это техника машинного обучения, которая включает в себя обучение искусственного интеллекта через повторение действий и связанных с ними наград. Агент обучения с подкреплением экспериментирует в окружающей среде, совершает действия и получает награды, когда совершает правильные действия. Со временем агент учится совершать действия, которые максимизируют его награду. Это быстрое определение обучения с подкреплением, но более близкий взгляд на концепции, лежащие в основе обучения с подкреплением, поможет вам получить лучшее, более интуитивное понимание.
Термин “обучение с подкреплением” заимствован из концепции подкрепления в психологии. По этой причине давайте возьмем момент, чтобы понять психологическую концепцию подкрепления. В психологическом смысле термин подкрепление относится к чему-то, что увеличивает вероятность того, что определенный ответ/действие произойдет. Эта концепция подкрепления является центральной идеей теории оперантного условного рефлекса, впервые предложенной психологом Б.Ф. Скиннером. В этом контексте подкрепление – это все, что вызывает увеличение частоты определенного поведения. Если мы подумаем о возможном подкреплении для людей, это могут быть такие вещи, как похвала, повышение на работе, конфеты и веселые занятия.
В традиционном, психологическом смысле существуют два типа подкрепления. Существует положительное подкрепление и отрицательное подкрепление. Положительное подкрепление – это добавление чего-то, чтобы увеличить поведение, как давать собаке угощение, когда она хорошо себя ведет. Отрицательное подкрепление включает в себя удаление стимула, чтобы вызвать поведение, как выключение громких звуков, чтобы выманить застенчивую кошку.
Положительное и отрицательное подкрепление
Положительное подкрепление увеличивает частоту поведения, в то время как отрицательное подкрепление уменьшает частоту. В целом, положительное подкрепление – это наиболее часто используемый тип подкрепления, используемый в обучении с подкреплением, поскольку оно помогает моделям максимизировать производительность на заданной задаче. Не только это, но и положительное подкрепление приводит модель к более устойчивым изменениям, изменениям, которые могут стать постоянными закономерностями и сохраняться в течение длительного времени.
Напротив, хотя отрицательное подкрепление также делает поведение более вероятным, оно используется для поддержания минимального стандарта производительности, а не для достижения максимальной производительности модели. Отрицательное подкрепление в обучении с подкреплением может помочь обеспечить, чтобы модель была удержана от нежелательных действий, но оно не может заставить модель исследовать желаемые действия.
Обучение агента с подкреплением
Когда агент обучения с подкреплением обучается, существуют четыре разных ингредиента или состояния, используемые в обучении: начальные состояния (Состояние 0), новое состояние (Состояние 1), действия и награды.
Представьте, что мы обучаем агент с подкреплением играть в платформенную видеоигру, где цель ИИ – добраться до конца уровня, перемещаясь вправо по экрану. Начальное состояние игры извлекается из окружающей среды, то есть первый кадр игры анализируется и передается модели. На основе этой информации модель должна решить, какое действие совершить.
В течение начальных фаз обучения эти действия случайны, но по мере того, как модель подкрепляется, определенные действия становятся более распространенными. После совершения действия окружающая среда игры обновляется, и создается новое состояние или кадр. Если действие, совершенное агентом, привело к желаемому результату, скажем, в этом случае агент все еще жив и не был поражен врагом, агенту предоставляется некоторая награда, и он становится более вероятным, что совершит то же действие в будущем.
Эта базовая система постоянно повторяется, снова и снова, и каждый раз агент пытается научиться немного больше и максимизировать свою награду.
Эпизодические и непрерывные задачи
Задачи обучения с подкреплением обычно можно разделить на две разные категории: эпизодические задачи и непрерывные задачи.
Эпизодические задачи будут выполнять цикл обучения/тренировки и улучшать свою производительность до тех пор, пока не будут выполнены определенные критерии окончания, и обучение будет прекращено. В игре это может быть достижение конца уровня или падение в опасность, такую как шипы. Напротив, непрерывные задачи не имеют критериев окончания, по сути, продолжая обучаться бесконечно, пока инженер не решит прекратить обучение.
Монте-Карло и временная разница
Существуют два основных способа обучения, или тренировки, агента с подкреплением. В подходе Монте-Карло награды предоставляются агенту (его счет обновляется) только в конце эпизода обучения. Другими словами, только когда условие окончания достигнуто, модель учится, насколько хорошо она выполнила свою задачу. Затем она может использовать эту информацию, чтобы обновить свою производительность, и когда начнется следующий раунд обучения, она будет реагировать в соответствии с новой информацией.
Метод временной разницы отличается от метода Монте-Карло тем, что оценка значения, или оценка счета, обновляется в течение эпизода обучения. Как только модель переходит к следующему шагу времени, значения обновляются.
Изучение и эксплуатация
Обучение агента с подкреплением – это балансирование акта, включающего баланс двух разных метрик: изучения и эксплуатации.
Изучение – это акт сбора большего количества информации об окружающей среде, в то время как эксплуатация – это использование уже известной информации об окружающей среде, чтобы заработать награды. Если агент только изучает и никогда не эксплуатирует окружающую среду, желаемые действия никогда не будут выполнены. С другой стороны, если агент только эксплуатирует и никогда не изучает, агент будет учиться выполнять только одно действие и не откроет других возможных стратегий заработка наград. Следовательно, балансирование изучения и эксплуатации имеет решающее значение при создании агента с подкреплением.
Применения обучения с подкреплением
Обучение с подкреплением может быть использовано в широком диапазоне ролей и лучше всего подходит для приложений, где задачи требуют автоматизации.
Автоматизация задач, выполняемых промышленными роботами, – это одна из областей, где обучение с подкреплением доказало свою полезность. Обучение с подкреплением также может быть использовано для задач, таких как текстовая обработка, создание моделей, которые могут суммировать большие объемы текста. Исследователи также экспериментируют с использованием обучения с подкреплением в области здравоохранения, где агенты с подкреплением выполняют задачи, такие как оптимизация политики лечения. Обучение с подкреплением также может быть использовано для адаптации образовательных материалов для студентов.
Сводка обучения с подкреплением
Обучение с подкреплением – это мощный метод создания агентов ИИ, который может привести к впечатляющим и иногда удивительным результатам. Обучение агента через обучение с подкреплением может быть сложным и трудным, поскольку оно требует многих итераций обучения и тонкого баланса акта изучения и эксплуатации. Однако, если успешно, агент, созданный с помощью обучения с подкреплением, может выполнять сложные задачи в широком диапазоне различных окружающих сред.








