ИИ 101
Что такое Переобучение?
Что такое Переобучение?
Когда вы обучаете нейронную сеть, вы должны избегать переобучения. Переобучение – это проблема в машинном обучении и статистике, когда модель слишком хорошо учится на обучающем наборе данных, идеально объясняя обучающий набор данных, но не в состоянии обобщить свою прогностическую силу на другие наборы данных.
Иными словами, в случае модели с переобучением она часто показывает очень высокую точность на обучающем наборе данных, но низкую точность на данных, собранных и запущенных через модель в будущем. Это быстрое определение переобучения, но давайте рассмотрим концепцию переобучения более подробно. Давайте посмотрим, как происходит переобучение и как его можно избежать.
Понимание “Фита” и Недообучения
Бывает полезно взглянуть на концепцию недообучения и “фита” вообще, когда мы обсуждаем переобучение. Когда мы обучаем модель, мы пытаемся разработать框架, который способен предсказать природу или класс предметов в наборе данных на основе характеристик, которые описывают эти предметы. Модель должна быть в состоянии объяснить закономерность в наборе данных и предсказать классы будущих данных на основе этой закономерности. Чем лучше модель объясняет связь между характеристиками обучающего набора, тем “лучше” наш модель.

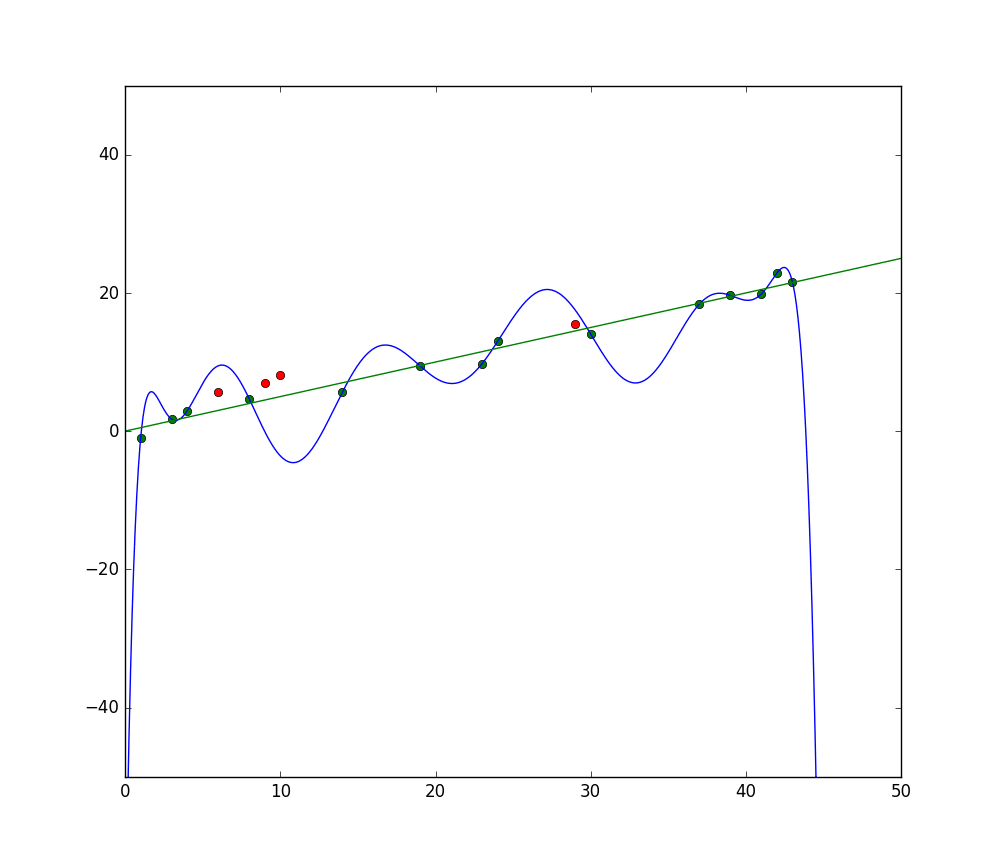
Синяя линия представляет прогнозы модели, которая недообучается, а зеленая линия представляет модель с лучшим фитом. Фото: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Модель, которая плохо объясняет связь между характеристиками обучающих данных и, следовательно, не в состоянии точно классифицировать будущие данные, недообучает обучающие данные. Если бы вы построили график предсказанной связи модели против фактического пересечения характеристик и меток, прогнозы отклонились бы от метки. Если бы у нас был график с фактическими значениями обучающего набора, модель с сильным недообучением сильно отклонилась бы от большинства данных. Модель с лучшим фитом могла бы пройти через центр данных, с отдельными данными, отклоняющимися от предсказанных значений только немного.
Недообучение может часто возникать, когда недостаточно данных для создания точной модели или когда пытаются разработать линейную модель с нелинейными данными. Больше данных или больше характеристик часто помогают уменьшить недообучение.
Итак, почему бы мы не создали модель, которая объясняет каждый пункт в обучающем наборе данных идеально? Разве идеальная точность не является желательной? Создание модели, которая слишком хорошо учится на обучающих данных, – это то, что вызывает переобучение. Обучающий набор данных и другие, будущие наборы данных, которые вы запускаете через модель, не будут идентичны. Они, скорее всего, будут очень похожи во многих отношениях, но они также будут отличаться по ключевым аспектам. Следовательно, разработка модели, которая объясняет обучающий набор данных идеально, означает, что вы в конечном итоге получите теорию о связи между характеристиками, которая не обобщается хорошо на другие наборы данных.
Понимание Переобучения
Переобучение происходит, когда модель слишком хорошо учится на деталях в обучающем наборе данных, что приводит к тому, что модель страдает, когда делаются прогнозы на внешних данных. Это может произойти, когда модель не только учится характеристикам набора данных, но также учится случайным колебаниям или шуму в наборе данных, придавая значение этим случайным/незначительным явлениям.
Переобучение более вероятно произойдет, когда используются нелинейные модели, поскольку они более гибкие при обучении на данных. Непараметрические алгоритмы машинного обучения часто имеют различные параметры и методы, которые можно применить для ограничения чувствительности модели к данным и, следовательно, уменьшить переобучение. Например, модели решающих деревьев очень чувствительны к переобучению, но метод, называемый обрезкой, можно использовать для случайного удаления некоторых деталей, которые модель выучила.
Если бы вы построили график прогнозов модели на оси X и Y, у вас была бы линия прогноза, которая извивается туда и обратно, что отражает тот факт, что модель слишком сильно попыталась приспособить все точки в наборе данных к своему объяснению.
Контроль Переобучения
Когда мы обучаем модель, мы идеально хотим, чтобы модель не совершала ошибок. Когда производительность модели сходится к тому, чтобы делать правильные прогнозы на всех данных в обучающем наборе, фит становится лучше. Модель с хорошим фитом способна объяснить почти весь обучающий набор данных без переобучения.
По мере того, как модель тренируется, ее производительность улучшается со временем. Ставка ошибок модели уменьшается со временем обучения, но она уменьшается только до определенной точки. Точка, в которой производительность модели на тестовом наборе начинает снова увеличиваться, обычно является точкой, в которой происходит переобучение. Чтобы получить лучший фит для модели, мы хотим остановить обучение модели в точке наименьших потерь на обучающем наборе, до того, как ошибка начнет снова увеличиваться. Оптимальная точка остановки можно определить, построив график производительности модели во время обучения и остановив обучение, когда потери минимальны. Однако один риск этого метода контроля за переобучением заключается в том, что указание конечной точки для обучения на основе тестовой производительности означает, что тестовые данные становятся немного включенными в процедуру обучения и теряют свой статус чисто “не тронутых” данных.
Существует несколько способов борьбы с переобучением. Одним из методов уменьшения переобучения является использование тактики ресэмплирования, которая работает путем оценки точности модели. Вы также можете использовать валидационный набор данных в дополнение к тестовому набору и построить график точности обучения против валидационного набора вместо тестового набора. Это сохраняет ваш тестовый набор данных незримым. Популярным методом ресэмплирования является кросс-валидация с несколькими складками. Этот метод позволяет вам разделить данные на подмножества, на которых обучается модель, а затем анализирует производительность модели на этих подмножествах, чтобы оценить, как модель будет работать на внешних данных.
Использование кросс-валидации – один из лучших способов оценить точность модели на незримых данных, и когда его сочетают с валидационным набором данных, переобучение можно часто свести к минимуму.








