
AI 101
Ce este supraajustarea?
Ce este supraajustarea?
Când antrenezi o rețea neuronală, trebuie să eviți supraadaptarea. Suprapunere este o problemă în cadrul învățării automate și al statisticilor în care un model învață prea bine tiparele unui set de date de antrenament, explicând perfect setul de date de antrenament, dar nereușind să își generalizeze puterea predictivă la alte seturi de date.
Cu alte cuvinte, în cazul unui model de supraadaptare, acesta va prezenta adesea o acuratețe extrem de mare pe setul de date de antrenament, dar o acuratețe scăzută pe datele colectate și rulate prin model în viitor. Aceasta este o definiție rapidă a supraajustării, dar să trecem peste conceptul de supraadaptare mai detaliat. Să aruncăm o privire la modul în care apare supraadaptarea și cum poate fi evitată.
Înțelegerea „Fit” și Underfitting
Este util să aruncăm o privire asupra conceptului de underfitting și „potrivi” în general când se discută despre supraadaptare. Când antrenăm un model, încercăm să dezvoltăm un cadru care este capabil să prezică natura sau clasa elementelor dintr-un set de date, pe baza caracteristicilor care descriu acele elemente. Un model ar trebui să fie capabil să explice un model într-un set de date și să prezică clasele de puncte de date viitoare pe baza acestui model. Cu cât modelul explică mai bine relația dintre caracteristicile setului de antrenament, cu atât modelul nostru este mai „potrivit”.
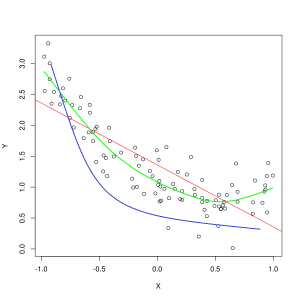
Linia albastră reprezintă predicțiile unui model care nu se potrivește, în timp ce linia verde reprezintă un model mai potrivit. Foto: Pep Roca prin Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Un model care explică prost relația dintre caracteristicile datelor de antrenament și, prin urmare, nu reușește să clasifice cu exactitate exemplele de date viitoare este sub-amenajare datele de antrenament. Dacă ar fi să reprezentați grafic relația prezisă a unui model nepotrivit față de intersecția reală a caracteristicilor și etichetelor, predicțiile s-ar devia. Dacă am avea etichetat un grafic cu valorile reale ale unui set de antrenament, un model extrem de subadaptat ar pierde drastic majoritatea punctelor de date. Un model cu o potrivire mai bună ar putea tăia o cale prin centrul punctelor de date, punctele de date individuale fiind departe de valorile prezise doar puțin.
Ajustarea insuficientă poate apărea adesea atunci când există date insuficiente pentru a crea un model precis sau când se încearcă proiectarea unui model liniar cu date neliniare. Mai multe date de antrenament sau mai multe caracteristici vor ajuta adesea la reducerea subadaptarii.
Deci, de ce nu am crea un model care explică perfect fiecare punct din datele de antrenament? Cu siguranță este de dorit o precizie perfectă? Crearea unui model care a învățat prea bine tiparele datelor de antrenament este ceea ce cauzează supraadaptarea. Setul de date de antrenament și alte seturi de date viitoare pe care le rulați prin model nu vor fi exact aceleași. Probabil că vor fi foarte asemănătoare în multe privințe, dar vor diferi și în moduri cheie. Prin urmare, proiectarea unui model care explică perfect setul de date de antrenament înseamnă că ajungeți cu o teorie despre relația dintre caracteristici care nu se generalizează bine la alte seturi de date.
Înțelegerea supraajustării
Supraadaptarea are loc atunci când un model învață prea bine detaliile din setul de date de antrenament, ceea ce face ca modelul să sufere atunci când se fac predicții pe date externe. Acest lucru poate apărea atunci când modelul nu numai că învață caracteristicile setului de date, ci învață și fluctuații aleatorii sau zgomot în setul de date, acordând importanță acestor apariții aleatoare/neimportante.
Supraadaptarea este mai probabil să apară atunci când sunt utilizate modele neliniare, deoarece acestea sunt mai flexibile atunci când învață caracteristicile datelor. Algoritmii neparametrici de învățare automată au adesea diferiți parametri și tehnici care pot fi aplicate pentru a limita sensibilitatea modelului la date și, prin urmare, a reduce supraadaptarea. Ca exemplu, modele de arbore de decizie sunt foarte sensibili la supraajustare, dar o tehnică numită tăiere poate fi folosită pentru a elimina aleatoriu unele dintre detaliile pe care modelul le-a învățat.
Dacă ar fi să reprezentați grafic predicțiile modelului pe axele X și Y, ați avea o linie de predicție care merge în zig-zag înainte și înapoi, ceea ce reflectă faptul că modelul a încercat prea mult să încadreze toate punctele din setul de date în explicația ei.
Controlul supraajustării
Când antrenăm un model, în mod ideal dorim ca modelul să nu facă erori. Când performanța modelului converge către realizarea de predicții corecte asupra tuturor punctelor de date din setul de date de antrenament, potrivirea devine din ce în ce mai bună. Un model cu o potrivire bună este capabil să explice aproape tot setul de date de antrenament fără o supraadaptare.
Pe măsură ce un model se antrenează, performanța sa se îmbunătățește în timp. Rata de eroare a modelului va scădea pe măsură ce trece timpul de antrenament, dar scade doar până la un anumit punct. Punctul în care performanța modelului pe setul de testare începe să crească din nou este de obicei punctul în care are loc supraajustarea. Pentru a obține cea mai bună potrivire pentru un model, dorim să oprim antrenarea modelului în punctul cu cea mai mică pierdere din setul de antrenament, înainte ca eroarea să înceapă să crească din nou. Punctul optim de oprire poate fi stabilit prin reprezentarea grafică a performanței modelului pe tot parcursul antrenamentului și oprirea antrenamentului atunci când pierderea este cea mai mică. Cu toate acestea, un risc al acestei metode de control pentru supraadaptare este acela că specificarea punctului final pentru antrenament pe baza performanței testului înseamnă că datele testului devin oarecum incluse în procedura de antrenament și își pierd statutul de date pur „neatinse”.
Există câteva moduri diferite prin care se poate combate supraadaptarea. O metodă de reducere a supraajustării este utilizarea unei tactici de reeșantionare, care operează prin estimarea acurateței modelului. De asemenea, puteți utiliza a validare setul de date în plus față de setul de testare și reprezentați grafic acuratețea antrenamentului în raport cu setul de validare în loc de setul de date de testare. Acest lucru păstrează setul de date de testare nevăzut. O metodă populară de reeșantionare este validarea încrucișată cu pliuri K. Această tehnică vă permite să vă împărțiți datele în subseturi pe care modelul este antrenat, iar apoi performanța modelului pe subseturi este analizată pentru a estima modul în care modelul va funcționa pe datele externe.
Utilizarea validării încrucișate este una dintre cele mai bune modalități de a estima acuratețea unui model pe date nevăzute și, atunci când este combinată cu un set de date de validare, supraadaptarea poate fi adesea redusă la minimum.










