IA 101
Ce este regresia liniară?
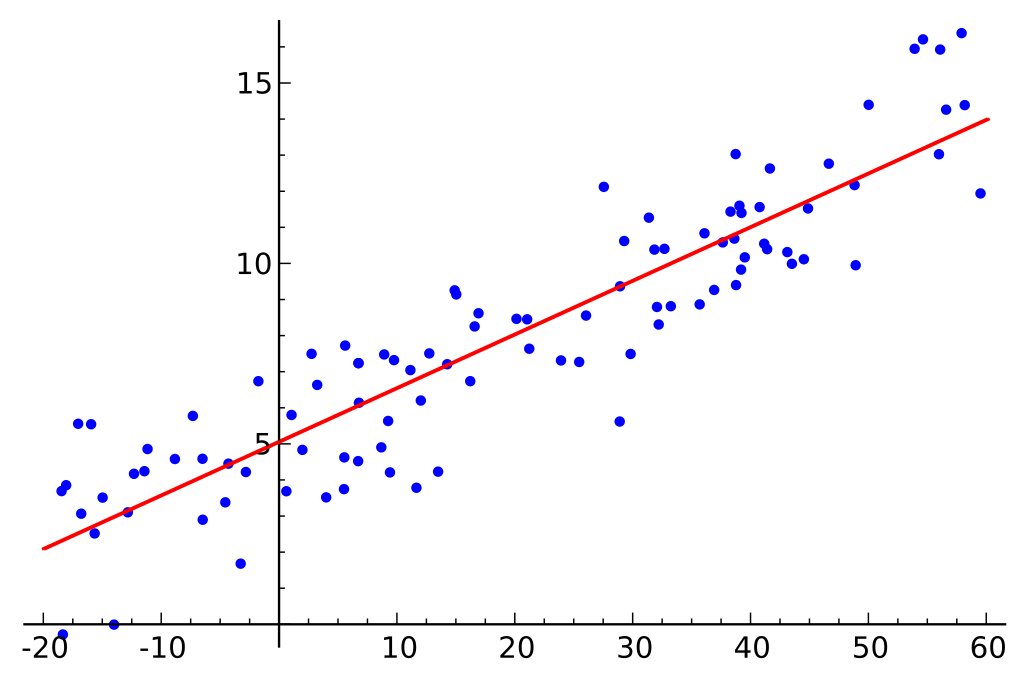
Ce este regresia liniară?
Regresia liniară este un algoritm utilizat pentru a prezice sau pentru a vizualiza o relație între două caracteristici/variabile diferite. În sarcinile de regresie liniară, există două tipuri de variabile examinate: variabila dependentă și variabila independentă. Variabila independentă este variabila care stă singură, nefiind afectată de cealaltă variabilă. Pe măsură ce variabila independentă este ajustată, nivelurile variabilei dependente vor fluctua. Variabila dependentă este variabila care este studiată și este ceea ce modelul de regresie încearcă să rezolve sau să prevadă. În sarcinile de regresie liniară, fiecare observație/instanță este alcătuită atât din valoarea variabilei dependente, cât și din valoarea variabilei independente.
Acesta a fost un scurt rezumat al regresiei liniare, dar să ne asigurăm că ajungem la o înțelegere mai bună a regresiei liniare, examinând un exemplu și formula pe care o utilizează.
Înțelegerea regresiei liniare
Să presupunem că avem un set de date care acoperă dimensiunile hard-discurilor și costul acestor hard-discuri.
Să presupunem că setul de date pe care îl avem este alcătuit din două caracteristici diferite: cantitatea de memorie și cost. Cu cât cumpărăm mai multă memorie pentru un computer, cu atât crește costul achiziției. Dacă am reprezenta punctele de date individuale pe un grafic de dispersie, am putea obține un grafic care arată ceva de genul acesta:

Raportul exact dintre memorie și cost poate varia între producători și modele de hard-discuri, dar în general, tendința datelor este una care începe în colțul din stânga jos (unde hard-discurile sunt atât mai ieftine, cât și au o capacitate mai mică) și se deplasează spre dreapta sus (unde discurile sunt mai scumpe și au o capacitate mai mare).
Dacă am avea cantitatea de memorie pe axa X și costul pe axa Y, o linie care captează relația dintre variabilele X și Y ar începe în colțul din stânga jos și s-ar deplasa spre dreapta sus.

Funcția unui model de regresie este de a determina o funcție liniară între variabilele X și Y care descrie cel mai bine relația dintre cele două variabile. În regresia liniară, se presupune că Y poate fi calculat dintr-o combinație a variabilelor de intrare. Relația dintre variabilele de intrare (X) și variabilele țintă (Y) poate fi reprezentată prin desenarea unei linii prin punctele din grafic. Linia reprezintă funcția care descrie cel mai bine relația dintre X și Y (de exemplu, pentru fiecare dată când X crește cu 3, Y crește cu 2). Scopul este de a găsi o “linie de regresie” optimă, sau linia/funcia care se potrivește cel mai bine datelor.
Liniile sunt de obicei reprezentate de ecuația: Y = m*X + b. X se referă la variabila dependentă, în timp ce Y este variabila independentă. În timp ce m este panta liniei, definită de “creștere” peste “alergare”. Practicienii de învățare automată reprezintă ecuația faimoasă a liniei cu o pantă puțin diferit, utilizând ecuația:
y(x) = w0 + w1 * x
În ecuația de mai sus, y este variabila țintă, în timp ce “w” este parametrul modelului și intrarea este “x”. Deci, ecuația se citește astfel: “Funcția care dă Y, în funcție de X, este egală cu parametrii modelului multiplicați cu caracteristicile”. Parametrii modelului sunt ajustați în timpul antrenamentului pentru a obține linia de regresie care se potrivește cel mai bine.
Regresia liniară multiplă

Foto: Cbaf via Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Procesul descris mai sus se aplică regresiei liniare simple, sau regresiei pe seturi de date în care există doar o singură caracteristică/variabilă independentă. Cu toate acestea, o regresie poate fi efectuată și cu multiple caracteristici. În cazul “regresiei liniare multiple“, ecuația este extinsă prin numărul de variabile găsite în setul de date. Cu alte cuvinte, în timp ce ecuația pentru regresia liniară obișnuită este y(x) = w0 + w1 * x, ecuația pentru regresia liniară multiplă ar fi y(x) = w0 + w1x1 plus greutățile și intrările pentru diferitele caracteristici. Dacă reprezentăm numărul total de greutăți și caracteristici ca w(n)x(n), atunci am putea reprezenta formula astfel:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
După stabilirea formulei pentru regresia liniară, modelul de învățare automată va utiliza diferite valori pentru greutăți, desenând diferite linii de potrivire. Îți amintești că scopul este de a găsi linia care se potrivește cel mai bine datelor pentru a determina care dintre combinațiile posibile de greutăți (și, prin urmare, care dintre liniile posibile) se potrivește cel mai bine datelor și explică relația dintre variabile.
O funcție de cost este utilizată pentru a măsura cât de aproape sunt valorile presupuse Y de valorile reale Y atunci când se utilizează o anumită valoare a greutății. Funcția de cost pentru regresia liniară este eroarea medie pătratică, care ia pur și simplu media (pătrată) a erorii dintre valoarea prezisă și valoarea reală pentru toate punctele de date din setul de date. Funcția de cost este utilizată pentru a calcula un cost, care captează diferența dintre valoarea țintă prezisă și valoarea țintă reală. Dacă linia de potrivire este departe de punctele de date, costul va fi mai mare, în timp ce costul va deveni mai mic pe măsură ce linia se apropie de capturarea relațiilor reale dintre variabile. Greutățile modelului sunt apoi ajustate până când se găsește configurația de greutate care produce cea mai mică cantitate de eroare.








