IA 101
Ce sunt RNN și LSTMs în Deep Learning?
Multe dintre cele mai impresionante avansuri în procesarea limbajului natural și chatbot-urile AI sunt conduse de Recurrent Neural Networks (RNNs) și Long Short-Term Memory (LSTM) networks. RNNs și LSTMs sunt arhitecturi speciale de rețele neuronale care pot procesa date secvențiale, date unde ordinea cronologică contează. LSTMs sunt esențialmente versiuni îmbunătățite ale RNNs, capabile să interpreteze secvențe mai lungi de date. Să aruncăm o privire la modul în care RNNs și LSTMS sunt structurate și cum permit crearea unor sisteme avansate de procesare a limbajului natural.
Ce sunt Feed-Forward Neural Networks?
Înainte de a discuta despre modul în care funcționează Long Short-Term Memory (LSTM) și Convolutional Neural Networks (CNN), ar trebui să discutăm despre formatul unei rețele neuronale în general.
O rețea neuronală este destinată să examineze datele și să învețe modele relevante, astfel încât aceste modele să poată fi aplicate altor date și noi date să poată fi clasificate. Rețelele neuronale sunt împărțite în trei secțiuni: o strat de intrare, un strat ascuns (sau multiple straturi ascunse) și un strat de ieșire.
Stratul de intrare este ceea ce primește datele în rețeaua neuronală, în timp ce straturile ascunse sunt cele care învață modelele din date. Straturile ascunse din setul de date sunt conectate la straturile de intrare și ieșire prin “greutăți” și “sesizori” care sunt doar ipoteze despre modul în care punctele de date sunt legate între ele. Aceste greutăți sunt ajustate în timpul antrenamentului. Pe măsură ce rețeaua se antrenează, ipotezele modelului despre datele de antrenament (valorile de ieșire) sunt comparate cu etichetele reale de antrenament. În timpul antrenamentului, rețeaua ar trebui (sperăm) să devină mai precisă în a recunoaște relațiile dintre punctele de date, astfel încât să poată clasifica corect noi puncte de date. Rețelele neuronale profunde sunt rețele care au mai multe straturi în mijloc / mai multe straturi ascunse. Cu cât modelul are mai multe straturi ascunse și mai multe neuroni / noduri, cu atât mai bine poate recunoaște modelele din date.
Rețelele neuronale feed-forward regulate, precum cele pe care le-am descris mai sus, sunt adesea numite “rețele neuronale dense”. Aceste rețele neuronale dense sunt combinate cu diferite arhitecturi de rețele care se specializează în interpretarea diferitelor tipuri de date.
Ce sunt RNNs (Recurrent Neural Networks)?

Recurrent Neural Networks iau principiul general al rețelelor neuronale feed-forward și le permit să gestioneze date secvențiale prin acordarea modelului unei memorii interne. Partea “Recurrent” a numelui RNN provine din faptul că intrările și ieșirile se buclă. Odată ce ieșirea rețelei este produsă, ieșirea este copiată și returnată în rețea ca intrare. Atunci când se ia o decizie, nu numai intrarea și ieșirea curentă sunt analizate, ci și intrarea anterioară este luată în considerare. Pentru a spune asta în alt fel, dacă intrarea inițială pentru rețea este X și ieșirea este H, atât H, cât și X1 (următoarea intrare în secvența de date) sunt introduse în rețea pentru următoarea rundă de învățare. În acest fel, contextul datelor (intrările anterioare) este păstrat pe măsură ce rețeaua se antrenează.
Rezultatul acestei arhitecturi este că RNNs sunt capabile să gestioneze date secvențiale. Cu toate acestea, RNNs suferă de câteva probleme. RNNs suferă de problemele de gradient care dispar și explodează.
Lungimea secvențelor pe care o rețea RNN o poate interpreta este destul de limitată, în special în comparație cu LSTMs.
Ce sunt LSTMs (Long Short-Term Memory Networks)?
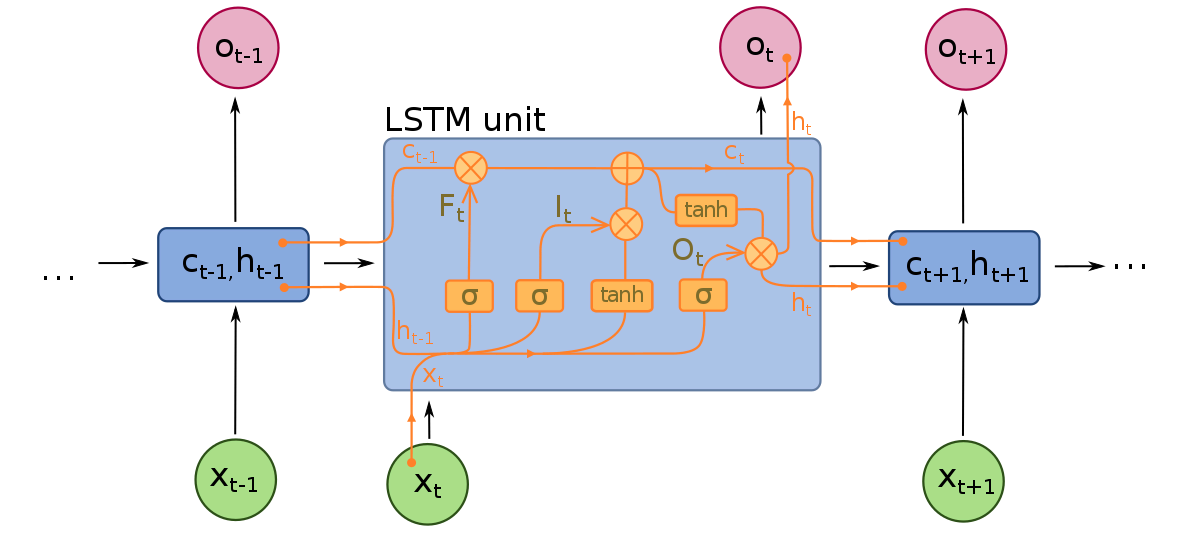
Long Short-Term Memory networks pot fi considerate extensii ale RNNs, aplicând din nou conceptul de păstrare a contextului intrărilor. Cu toate acestea, LSTMs au fost modificate în mai multe moduri importante care le permit să interpreteze datele trecute cu metode superioare. Modificările aduse LSTMs se referă la problema gradientului care dispare și permit LSTMs să ia în considerare secvențe de intrare mult mai lungi.

Modelele LSTMs sunt alcătuite din trei componente diferite, sau porți. Există o poartă de intrare, o poartă de ieșire și o poartă de uitare. La fel ca RNNs, LSTMs iau în considerare intrările de la timpul anterior atunci când modifică memoria modelului și greutățile de intrare. Poarta de intrare ia decizii despre care valori sunt importante și ar trebui să fie lăsate să treacă prin model. O funcție sigmoid este utilizată în poarta de intrare, care ia decizii despre care valori să le treacă prin rețeaua recurentă. Zero elimină valoarea, în timp ce 1 o păstrează. O funcție TanH este utilizată aici, care decide cât de importante sunt valorile de intrare pentru model, variind de la -1 la 1.
După ce intrările și starea de memorie curentă sunt luate în considerare, poarta de ieșire decide care valori să le treacă la următorul pas de timp. În poarta de ieșire, valorile sunt analizate și li se atribuie o importanță variind de la -1 la 1. Acest lucru reglementează datele înainte de a fi transmise la următoarea operațiune de timp. În final, sarcina porții de uitare este de a elimina informațiile pe care modelul le consideră inutile pentru a lua o decizie despre natura valorilor de intrare. Poarta de uitare utilizează o funcție sigmoid pe valorile, furnizând numere între 0 (uită) și 1 (păstrează).
O rețea neuronală LSTM este alcătuită atât din straturi speciale LSTM care pot interpreta date secvențiale, cât și din straturi dens conectate, precum cele descrise mai sus. Odată ce datele trec prin straturile LSTM, ele trec în straturile dens conectate.








