AI 101
O que são CNNs (Convolutional Neural Networks)?
Talvez você esteja se perguntando como o Facebook ou o Instagram são capazes de reconhecer automaticamente rostos em uma imagem, ou como o Google permite que você pesquise fotos semelhantes na web apenas enviando uma foto sua. Esses recursos são exemplos de visão computacional e são alimentados por Redes neurais convolucionais (CNNs). No entanto, o que exatamente são redes neurais convolucionais? Vamos mergulhar fundo na arquitetura de uma CNN e entender como ela funciona.
O que são redes neurais?
Antes de começarmos a falar sobre redes neurais convolucionais, vamos dedicar um momento para definir rede neural regular. Há outro artigo sobre o tema das redes neurais disponíveis, então não vamos nos aprofundar muito nelas aqui. No entanto, para defini-los brevemente, eles são modelos computacionais inspirados no cérebro humano. Uma rede neural opera recebendo dados e manipulando os dados ajustando “pesos”, que são suposições sobre como os recursos de entrada estão relacionados entre si e com a classe do objeto. À medida que a rede é treinada, os valores dos pesos são ajustados e, espera-se, convergirão para pesos que capturam com precisão as relações entre os recursos.
É assim que uma rede neural feed-forward opera, e as CNNs são compostas de duas metades: uma rede neural feed-forward e um grupo de camadas convolucionais.
O que são redes neurais de convolução (CNNs)?
Quais são as “convoluções” que acontecem em uma rede neural convolucional? Uma convolução é uma operação matemática que cria um conjunto de pesos, criando essencialmente uma representação de partes da imagem. Este conjunto de pesos é denominado um kernel ou filtro. O filtro criado é menor do que toda a imagem de entrada, cobrindo apenas uma subseção da imagem. Os valores no filtro são multiplicados pelos valores na imagem. O filtro é então movido para formar uma representação de uma nova parte da imagem, e o processo é repetido até que toda a imagem tenha sido coberta.
Outra maneira de pensar sobre isso é imaginar uma parede de tijolos, com os tijolos representando os pixels na imagem de entrada. Uma “janela” está sendo deslizada para frente e para trás ao longo da parede, que é o filtro. Os tijolos visíveis pela janela são os pixels com seu valor multiplicado pelos valores dentro do filtro. Por esse motivo, esse método de criação de pesos com um filtro costuma ser chamado de técnica de “janelas deslizantes”.
A saída dos filtros sendo movidos ao redor de toda a imagem de entrada é uma matriz bidimensional representando a imagem inteira. Essa matriz é chamada de “mapa de características”.
Por que as convoluções são essenciais
Afinal, qual é o propósito de criar convoluções? As convoluções são necessárias porque uma rede neural deve ser capaz de interpretar os pixels em uma imagem como valores numéricos. A função das camadas convolucionais é converter a imagem em valores numéricos que a rede neural possa interpretar e, em seguida, extrair padrões relevantes. O trabalho dos filtros na rede convolucional é criar uma matriz bidimensional de valores que podem ser passados para as camadas posteriores de uma rede neural, aquelas que aprenderão os padrões da imagem.
Filtros e Canais
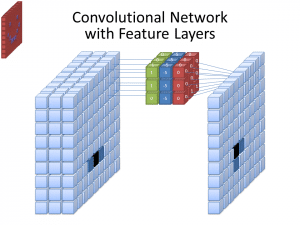
Foto: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNNs não usam apenas um filtro para aprender padrões das imagens de entrada. Vários filtros são usados, pois as diferentes matrizes criadas pelos diferentes filtros levam a uma representação mais complexa e rica da imagem de entrada. Números comuns de filtros para CNNs são 32, 64, 128 e 512. Quanto mais filtros houver, mais oportunidades a CNN terá de examinar os dados de entrada e aprender com eles.
Uma CNN analisa as diferenças nos valores de pixel para determinar as bordas dos objetos. Em uma imagem em escala de cinza, a CNN só olharia para as diferenças em termos de preto e branco, claro para escuro. Quando as imagens são coloridas, a CNN não apenas leva em consideração o escuro e a luz, mas também os três canais de cores diferentes – vermelho, verde e azul. Neste caso, os filtros possuem 3 canais, assim como a própria imagem. O número de canais que um filtro possui é referido como sua profundidade, e o número de canais no filtro deve corresponder ao número de canais na imagem.
Rede Neural Convolucional (CNN) Plataforma
Vamos dar uma olhada na arquitetura completa de uma rede neural convolucional. Uma camada convolucional é encontrada no início de cada rede convolucional, pois é necessária para transformar os dados da imagem em matrizes numéricas. No entanto, camadas convolucionais também podem vir depois de outras camadas convolucionais, o que significa que essas camadas podem ser empilhadas umas sobre as outras. Ter várias camadas convolucionais significa que as saídas de uma camada podem passar por mais convoluções e ser agrupadas em padrões relevantes. Na prática, isso significa que, à medida que os dados da imagem passam pelas camadas convolucionais, a rede começa a "reconhecer" características mais complexas da imagem.
As primeiras camadas de um ConvNet são responsáveis por extrair os recursos de baixo nível, como os pixels que compõem linhas simples. Camadas posteriores do ConvNet unirão essas linhas em formas. Esse processo de passar da análise de nível superficial para a análise de nível profundo continua até que o ConvNet reconheça formas complexas como animais, rostos humanos e carros.
Depois que os dados passaram por todas as camadas convolucionais, eles seguem para a parte densamente conectada da CNN. As camadas densamente conectadas são a aparência de uma rede neural feed-forward tradicional, uma série de nós organizados em camadas conectadas umas às outras. Os dados prosseguem por essas camadas densamente conectadas, que aprendem os padrões que foram extraídos pelas camadas convolucionais e, ao fazer isso, a rede se torna capaz de reconhecer objetos.










