Kąt Andersona
Dlaczego ataki na obrazy są nie do pozazdroszczenia
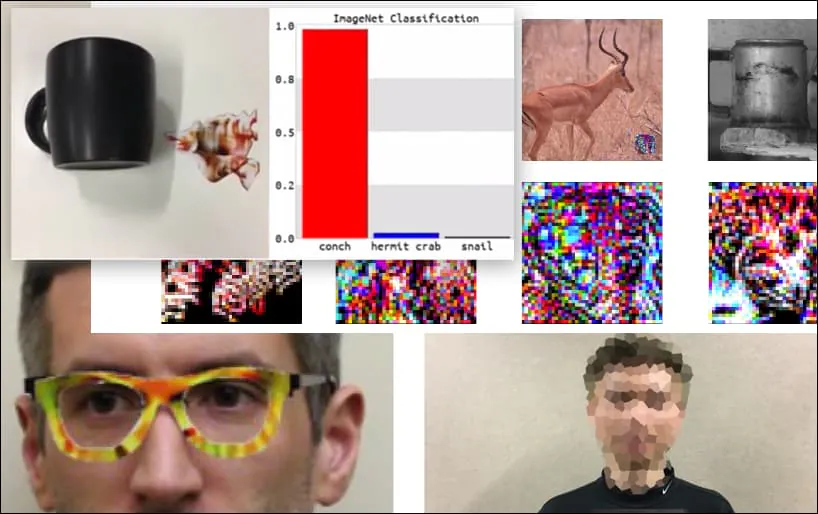
Atakowanie systemów rozpoznawania obrazów za pomocą starannie spreparowanych obrazów przeciwnych zostało uważane za zabawną, ale trywialną demonstrację możliwości przez ostatnie pięć lat. Jednak nowe badania z Australii sugerują, że swobodne używanie bardzo popularnych zbiorów danych obrazowych do komercyjnych projektów AI może stworzyć trwały nowy problem bezpieczeństwa.
Przez kilka lat grupa akademików z Uniwersytetu w Adelajdzie próbuje wyjaśnić coś bardzo ważnego na temat przyszłości systemów rozpoznawania obrazów opartych na AI.
To coś, co byłoby trudne (i bardzo drogie) do naprawienia teraz, i co byłoby nieuczciwie drogie do naprawienia, gdy trendy w badaniach nad rozpoznawaniem obrazów zostaną w pełni rozwinęte w komercyjne i przemysłowe wdrożenia w ciągu 5-10 lat.
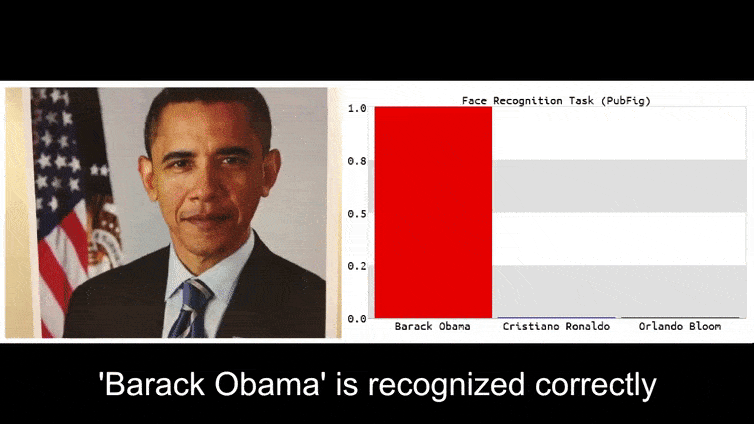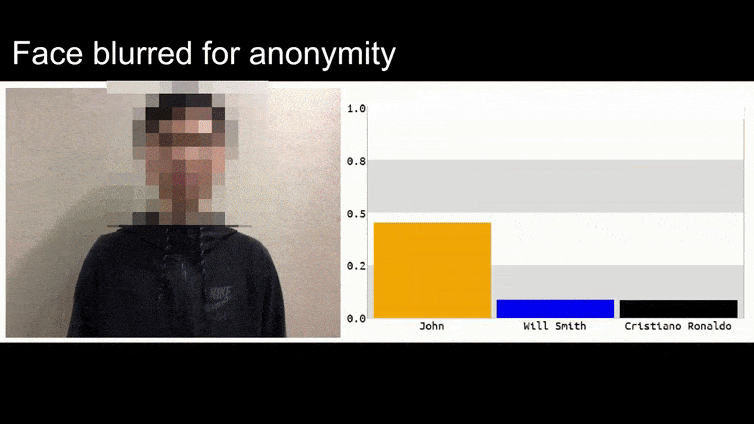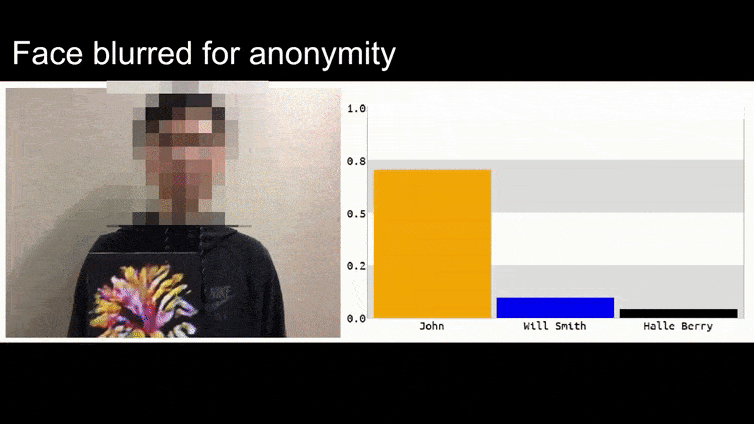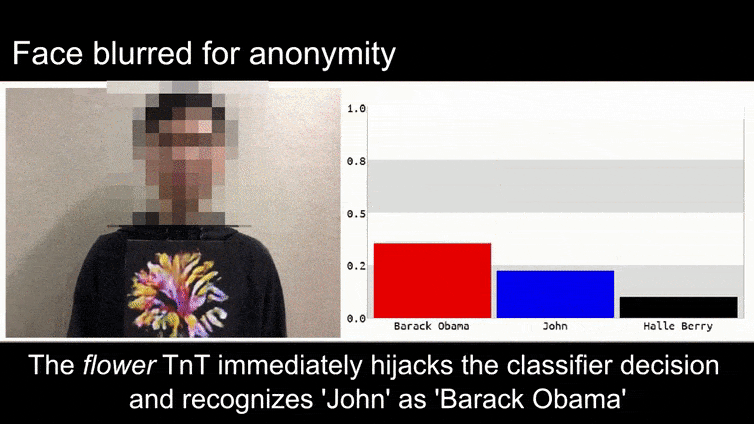
Przed tym, jak się tam dostaniemy, przyjrzyjmy się kwiatowi, który został sklasyfikowany jako prezydent Barack Obama, z jednego z sześciu filmów, które zespół opublikował na stronie projektu:
Źródło: https://www.youtube.com/watch?v=Klepca1Ny3c
Na powyższym obrazie system rozpoznawania twarzy, który wyraźnie wie, jak rozpoznać Baracka Obamę, został oszukany i jest 80% pewny, że anonimowy mężczyzna trzymający spreparowany, wydrukowany obraz przeciwny kwiatu jest również Barack Obama. System nie dba nawet o to, że “fałszywa twarz” jest na piersiach, zamiast na ramionach.
Chociaż jest imponujące, że badacze byli w stanie osiągnąć ten rodzaj przechwycenia tożsamości przez generowanie spójnego obrazu (kwiatu), zamiast zwykłego szumu losowego, wydaje się, że takie głupie eksploity pojawiają się dość regularnie w badaniach nad bezpieczeństwem komputerowego widzenia. Na przykład, te dziwnie wzorzyste okulary, które były w stanie oszukać rozpoznawanie twarzy w 2016 roku, lub specjalnie spreparowane obrazy przeciwnie, które próbują zmienić znaczenie znaków drogowych.
Jeśli jesteś zainteresowany, model sieci neuronowej (CNN) atakowany w powyższym przykładzie to VGGFace (VGG-16), wytrenowany na zbiorze danych PubFig z Uniwersytetu Kolumbii. Inne próbki ataków opracowane przez badaczy wykorzystywały różne zasoby w różnych kombinacjach.

Klawiatura została ponownie sklasyfikowana jako muszla, w modelu WideResNet50 na ImageNet. Badacze upewnili się również, że model nie ma skłonności do muszli. Zobacz pełny film, aby zobaczyć dodatkowe demonstracje na https://www.youtube.com/watch?v=dhTTjjrxIcU
Rozpoznawanie obrazów jako nowy wektor ataku
Wiele imponujących ataków, które badacze przedstawiają i ilustrują, nie są krytyką poszczególnych zbiorów danych lub konkretnych architektur uczenia maszynowego, które z nich korzystają. Nie mogą być one również łatwo obronione przez przełączenie zbiorów danych lub modeli, ponowne trenowanie modeli lub jakiekolwiek inne “łatwe” środki, które powodują, że praktycy ML szydzą z okazjonalnych demonstracji tego rodzaju sztuczek.
Raczej, eksploity zespołu z Adelajdy ilustrują centralną słabość w całej obecnej architekturze rozwoju AI do rozpoznawania obrazów; słabość, która mogłaby narazić wiele przyszłych systemów rozpoznawania obrazów na łatwą manipulację przez atakujących i umieścić wszelkie późniejsze środki obronne w defensywie.
Wyobraź sobie najnowsze obrazy przeciwnie ataków (takie jak kwiat powyżej) dodane jako “zero-day exploits” do systemów bezpieczeństwa przyszłości, tak jak obecne ramy antywirusowe i przeciwwirusowe aktualizują definicje wirusów każdego dnia.
Potencjał nowych ataków na obrazy przeciwnie byłby nieograniczony, ponieważ podstawowa architektura systemu nie przewidziała problemów, które mogą wystąpić w przyszłości, tak jak to miało miejsce z internetem, błędem tysiąclecia i przechylonym wieżą w Pizie.
W jaki sposób zatem ustawiamy scenę dla tego?
Pobieranie danych do ataku
Obrazy przeciwnie, takie jak przykład “kwiatu” powyżej, są generowane przez dostęp do zbiorów danych, które wytrenowały modele komputerowe. Nie potrzebujesz “przywilejowanego” dostępu do danych szkoleniowych (lub architektur modeli), ponieważ najpopularniejsze zbiory danych (i wiele wytrenowanych modeli) są powszechnie dostępne w silnym i stale aktualizowanym scenie torrentowym.
Na przykład, potężny ImageNet, jest dostępny w torrentach we wszystkich swoich wielu iteracjach, omijając jego zwyczajowe ograniczenia, i udostępniając kluczowe elementy wtórne, takie jak zbiory walidacyjne.

Źródło: https://academictorrents.com
Jeśli masz dane, możesz (jak zauważają badacze z Adelajdy) skutecznie “odwrócić” dowolny popularny zbiór danych, taki jak CityScapes, lub CIFAR.
W przypadku PubFig, zbioru danych, który umożliwił “kwiat Obamy” w poprzednim przykładzie, Uniwersytet Kolumbii rozwiązał rosnący trend w kwestiach praw autorskich związanych z redystrybucją zbiorów danych obrazowych, instruując badaczy, jak odtworzyć zbiór danych za pomocą wyselekcjonowanych linków, zamiast udostępniać kompilację bezpośrednio, obserwując ‘To wydaje się być sposobem, w jaki inne duże bazy danych internetowych ewoluują’.
W większości przypadków nie jest to konieczne: Kaggle szacuje, że dziesięć najpopularniejszych zbiorów danych obrazowych w komputerowym widzeniu to: CIFAR-10 i CIFAR-100 (oba bezpośrednio pobieralne); CALTECH-101 i 256 (oba dostępne, i oba dostępne jako torrenty); MNIST (oficjalnie dostępny, również w torrentach); ImageNet (patrz powyżej); Pascal VOC (dostępny, również w torrentach); MS COCO (dostępny, i w torrentach); Sports-1M (dostępny); i YouTube-8M (dostępny).
Dostępność ta jest również reprezentatywna dla szerszego zakresu dostępnych zbiorów danych komputerowego widzenia, ponieważ nieznane zbiory danych są śmiercią w kulturze rozwoju open source “publikuj lub zgiń”.
W jaki sposób zatem ustawiamy scenę dla tego?
Typowe krytyki metod ataków na obrazy przeciwnie
Najczęstsza i najbardziej uporczywa krytyka inżynierów uczenia maszynowego wobec skuteczności najnowszej techniki ataku na obrazy przeciwnie jest taka, że atak jest specyficzny dla konkretnego zbioru danych, konkretnego modelu lub obu; że nie jest “uogólnialny” do innych systemów; i, w związku z tym, reprezentuje tylko trywialne zagrożenie.
Druga najczęstsza skarga jest taka, że atak na obrazy przeciwnie jest ‘białą skrzynką’, co oznacza, że potrzebujesz bezpośredniego dostępu do środowiska szkoleniowego lub danych. Jest to rzeczywiście nieprawdopodobna sytuacja w większości przypadków – na przykład, jeśli chciałbyś wykorzystać proces szkolenia systemów rozpoznawania twarzy londyńskiej policji metropolitalnej, musiałbyś włamać się do NEC, albo za pomocą konsoli, albo za pomocą siekiery.
Długoterminowe “DNA” popularnych zbiorów danych komputerowego widzenia
Odnośnie do pierwszej krytyki, powinniśmy rozważyć nie tylko to, że garstka zbiorów danych komputerowego widzenia dominuje w branży rok w rok (tj. ImageNet dla wielu typów obiektów, CityScapes dla scen drogowych i FFHQ dla rozpoznawania twarzy); ale również to, że jako proste dane obrazowe z adnotacjami, są one “platformowo neutralne” i bardzo przenośne.
W zależności od ich możliwości, każda architektura szkolenia komputerowego znajdzie jakiś cech obiektów i klas w zbiorze danych ImageNet. Niektóre architektury mogą znaleźć więcej cech niż inne, lub utworzyć więcej pożytecznych połączeń niż inne, ale wszystkie powinny znaleźć co najmniej najwyższe cechy:

Dane ImageNet z minimalną liczbą poprawnych identyfikacji – ‘wyższe poziomy’ cech.
To są “wyższe poziomy” cech, które różnicują i “odciskają” zbiór danych, i które są niezawodnymi “hakami”, na których można powiesić długoterminową metodę ataku na obrazy przeciwnie, która może przenosić się między różnymi systemami i rozwijać się wraz z “starym” zbiorem danych, gdy ten jest kontynuowany w nowych badaniach i produktach.
Bardziej zaawansowana architektura wyprodukuje bardziej dokładne i szczegółowe identyfikacje, cechy i klasy:

Jednakże, im bardziej generator ataku na obrazy przeciwnie opiera się na tych niższych cechach (tj. “Młody mężczyzna kaukaski” zamiast “twarz”), tym mniej skuteczny będzie w przenoszeniu się na inne architektury, które wykorzystują inne wersje oryginalnego zbioru danych – takie jak podzbiór lub przefiltrowany zbiór, gdzie wiele oryginalnych obrazów z pełnego zbioru danych nie jest obecnych:

Ataki na obrazy przeciwnie na “wyczyszczonych”, wstępnie wytrenowanych modelach
Co z przypadkami, w których po prostu pobierasz wstępnie wytrenowany model, który został pierwotnie wytrenowany na bardzo popularnym zbiorze danych, i dajesz mu całkowicie nowe dane?
Model został już wytrenowany na (na przykład) ImageNet, i wszystko, co pozostaje, to wagi, które mogły zajmować tygodnie lub miesiące szkolenia, i są teraz gotowe pomóc ci zidentyfikować podobne obiekty do tych, które istniały w oryginalnych (teraz nieobecnych) danych.

Z oryginalnymi danymi usuniętymi z architektury szkolenia, pozostaje ‘predyspozycja’ modelu do klasyfikowania obiektów w sposób, w jaki pierwotnie nauczył się to robić, co w zasadzie spowoduje, że wiele oryginalnych ‘sygnatur’ zostanie ponownie utworzonych i stanie się ponownie podatnych na te same stare metody ataków na obrazy przeciwnie.
Te wagi są cenne. Bez danych lub wag, masz w zasadzie pustą architekturę bez danych. Będziesz musiał ją wytrenować od początku, przy ogromnym nakładzie czasu i zasobów obliczeniowych, tak jak pierwotni autorzy (prawdopodobnie na bardziej potężnym sprzęcie i z wyższym budżetem niż masz dostępny).
Kłopot w tym, że wagi są już dość dobrze ukształtowane i odporne. Chociaż będą się nieco adaptować w trakcie szkolenia, będą zachowywać się podobnie na nowych danych, jak na oryginalnych danych, wytwarzając sygnatury, na które system ataku na obrazy przeciwnie może się powiesić.
W długiej perspektywie, to również zachowuje “DNA” zbiorów danych komputerowego widzenia, które mają ponad dwanaście lat, i które mogły przejść przez znaczącą ewolucję od otwartych źródeł przez wdrożenia komercyjne – nawet w przypadku, gdy oryginalne dane szkoleniowe zostały całkowicie usunięte na początku projektu. Niektóre z tych wdrożeń komercyjnych mogą nie nastąpić przez kilka lat.
Brak potrzeby “białej skrzynki”
Odnośnie do drugiej powszechnej krytyki systemów ataków na obrazy przeciwnie, autorzy nowego artykułu odkryli, że ich zdolność do oszukiwania systemów rozpoznawania z pomocą spreparowanych obrazów kwiatów jest bardzo przenośna na wiele architektur.
Podczas obserwowania, że ich metoda “Universal NaTuralistic adversarial paTches” (TnT) jest pierwszą, która wykorzystuje rozpoznawalne obrazy (zamiast szumu losowego) do oszukiwania systemów rozpoznawania obrazów, autorzy stwierdzają również:
‘[TnTs] są skuteczne przeciwko wielu najnowocześniejszym klasyfikatorom, od szeroko stosowanych WideResNet50 w zadaniu rozpoznawania wizualnego ImageNet do modeli VGG-face w zadaniu rozpoznawania twarzy PubFig w obu celowych i niecelowych atakach.
‘TnTs mogą posiadać: i) naturalizm osiągalny [z] wyzwaniami stosowanymi w metodach ataków trojańskich; oraz ii) uogólnialność i przenośność przykładów przeciwnych do innych sieci.
‘To podnosi obawy dotyczące bezpieczeństwa i already wdrożonych DNN, a także przyszłych wdrożeń DNN, w których atakujący mogą używać niewidocznych, naturalnie wyglądających łat na oszukanie systemów neuronowych bez ingerencji w model i ryzyka odkrycia.’
Autorzy sugerują, że konwencjonalne środki obronne, takie jak pogorszenie dokładności sieci, mogłyby teoretycznie zapewnić pewną ochronę przed łatami TnT, ale że ‘TnTs nadal mogą pomyślnie ominąć te najnowocześniejsze metody obronne z większością systemów obronnych, osiągając 0% odporności’.
Możliwe rozwiązania obejmują federated learning, w którym pochodzenie danych jest chronione, oraz nowe podejścia, które mogą bezpośrednio “zaszyfrować” dane podczas szkolenia, takie jak niedawno zasugerowane przez Uniwersytet Aeronautyki i Astronautyki w Nanjing.
Nawet w tych przypadkach byłoby ważne, aby trenować na prawdziwie nowych danych obrazowych – teraz obrazy i powiązane adnotacje w małej grupie najpopularniejszych zbiorów danych CV są tak głęboko osadzone w cyklach rozwojowych na całym świecie, że przypominają raczej oprogramowanie niż dane; oprogramowanie, które często nie zostało znacząco zaktualizowane przez lata.
Wnioski
Ataki na obrazy przeciwnie są możliwe nie tylko dzięki praktykom open source w uczeniu maszynowym, ale również dzięki kulturze rozwoju AI, która jest motywowana do ponownego użycia dobrze ugruntowanych zbiorów danych komputerowego widzenia z kilku powodów: są one już skuteczne; są o wiele tańsze niż “rozpoczynanie od zera”; i są utrzymywane i aktualizowane przez wybitne umysły i organizacje w całej akademii i przemyśle, na poziomach finansowania i personelu, które byłoby trudne do replikowania przez pojedynczą firmę.
Ponadto, w wielu przypadkach, w których dane nie są oryginalne (inaczej niż CityScapes), obrazy zostały zebrane przed niedawnymi kontrowersjami wokół praktyk prywatności i gromadzenia danych, pozostawiając te starsze zbiory danych w pewnego rodzaju półprawnej próżni, która może wyglądać jak “bezpieczna przystań” z punktu widzenia firmy.
Ataki TnT! Powszechne, naturalistyczne łaty przeciwnie przeciwko głębokim sieciom neuronowym jest współautorem Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe z Uniwersytetu w Adelajdzie, wraz z Shiqing Ma z Wydziału Informatyki na Uniwersytecie Rutgers.
Zaktualizowano 1st grudzień 2021, 7:06am GMT+2 – corrected typo.












