AI 101
Co to są RNN i LSTM w głębokim uczeniu?
Wiele z najbardziej imponujących postępów w przetwarzaniu języka naturalnego i chatbotach AI jest napędzanych przez sieci neuronowe rekurencyjne (RNN) i sieci pamięci krótkotrwałej (LSTM). RNN i LSTM są specjalnymi architekturami sieci neuronowych, które są w stanie przetwarzać sekwencyjne dane, dane, gdzie chronologiczny porządek ma znaczenie. LSTM są podstawowo ulepszonymi wersjami RNN, zdolnymi do interpretowania dłuższych sekwencji danych. Zobaczmy, jak RNN i LSTM są zbudowane i jak umożliwiają tworzenie zaawansowanych systemów przetwarzania języka naturalnego.
Co to są sieci neuronowe feed-forward?
Przed omówieniem, jak działają sieci pamięci krótkotrwałej (LSTM) i sieci neuronowe konwolucyjne (CNN), powinniśmy omówić format sieci neuronowej w ogóle.
Sieć neuronowa jest przeznaczona do badania danych i uczenia się istotnych wzorców, aby te wzorce mogły być zastosowane do innych danych i nowe dane mogły być sklasyfikowane. Sieci neuronowe są podzielone na trzy sekcje: warstwę wejściową, warstwę ukrytą (lub wiele warstw ukrytych) i warstwę wyjściową.
Warstwa wejściowa jest tym, co wprowadza dane do sieci neuronowej, podczas gdy warstwy ukryte są tym, co uczy się wzorców w danych. Warstwy ukryte w zestawie danych są połączone z warstwami wejściowymi i wyjściowymi za pomocą “wag” i “przesunięć”, które są po prostu założeniami, jak punkty danych są ze sobą powiązane. Te wagi są dostosowywane podczas treningu. Podczas treningu sieci, zgadywania modelu dotyczące danych treningowych (wartości wyjściowe) są porównywane z rzeczywistymi etykietami treningowymi. W trakcie treningu sieć powinna (mogłaby) stać się bardziej dokładna w przewidywaniu relacji między punktami danych, aby mogła dokładnie klasyfikować nowe punkty danych. Głębokie sieci neuronowe są sieciami, które mają więcej warstw w środku/więcej warstw ukrytych. Im więcej warstw ukrytych i węzłów model ma, tym lepiej model może rozpoznać wzorce w danych.
Zwykłe sieci neuronowe feed-forward, takie jak te, które opisałem powyżej, są często nazywane “gęstymi sieciami neuronowymi”. Te gęste sieci neuronowe są łączone z różnymi architekturami sieci, które specjalizują się w interpretowaniu różnych rodzajów danych.
Co to są RNN (sieci neuronowe rekurencyjne)?

Sieci neuronowe rekurencyjne przyjmują ogólny принцип sieci neuronowych feed-forward i umożliwiają im obsługę sekwencyjnych danych, nadając modelowi wewnętrzną pamięć. “Rekurencyjna” część nazwy RNN pochodzi z faktu, że dane wejściowe i wyjściowe tworzą pętle. Gdy dane wyjściowe sieci są wyprodukowane, dane wyjściowe są kopiowane i zwracane do sieci jako dane wejściowe. Podczas podejmowania decyzji, nie tylko bieżące dane wejściowe i wyjściowe są analizowane, ale także poprzednie dane wejściowe są brane pod uwagę. Innymi słowy, jeśli początkowe dane wejściowe dla sieci są X, a dane wyjściowe są H, zarówno H, jak i X1 (następne dane wejściowe w sekwencji danych) są wprowadzane do sieci w następnym cyklu uczenia. W ten sposób kontekst danych (poprzednie dane wejściowe) jest zachowany podczas treningu sieci.
Wynikiem tej architektury jest to, że RNN są w stanie obsługiwać sekwencyjne dane. Jednak RNN cierpią z powodu kilku problemów. RNN cierpią z powodu zjawiska znikającego i eksplodującego gradientu.
Długość sekwencji, które RNN mogą interpretować, jest dość ograniczona, zwłaszcza w porównaniu z LSTM.
Co to są LSTM (sieci pamięci krótkotrwałej)?
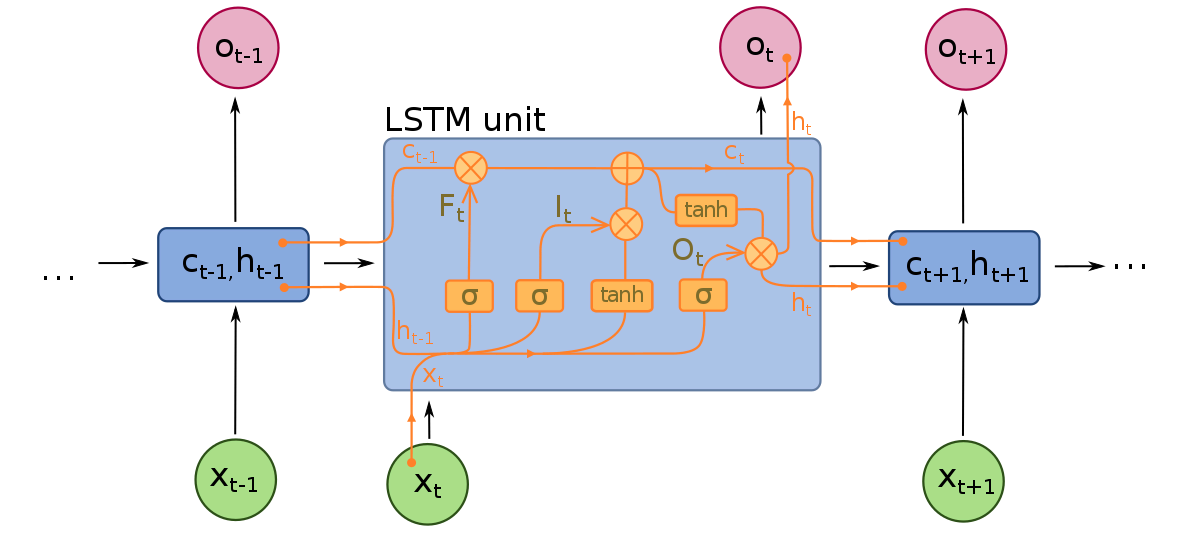
Sieci pamięci krótkotrwałej mogą być uważane za rozszerzenia RNN, ponownie stosując pojęcie zachowania kontekstu danych wejściowych. Jednak LSTM zostały zmodyfikowane w kilku ważnych punktach, co pozwala im na lepsze interpretowanie danych z przeszłości. Modyfikacje wprowadzone do LSTM dotyczą problemu znikającego gradientu i umożliwiają LSTM branie pod uwagę znacznie dłuższych sekwencji danych.

Modele LSTM składają się z trzech różnych składników, lub bramek. Jest bramka wejściowa, bramka wyjściowa i bramka zapomnienia. Podobnie jak RNN, LSTM biorą pod uwagę dane wejściowe z poprzedniej jednostki czasu przy modyfikowaniu pamięci modelu i wag wejściowych. Bramka wejściowa podejmuje decyzje o tym, które wartości są ważne i powinny być przepuszczane przez model. Funkcja sigmoidalna jest używana w bramce wejściowej, która podejmuje decyzje o tym, które wartości przekazać przez sieć rekurencyjną. Zero powoduje, że wartość jest odrzucana, podczas gdy 1 ją zachowuje. Funkcja TanH jest również używana tutaj, która decyduje o tym, jak ważne są wartości wejściowe dla modelu, w zakresie od -1 do 1.
Po uwzględnieniu bieżących danych wejściowych i stanu pamięci, bramka wyjściowa decyduje, które wartości powinny być przekazane do następnego kroku czasowego. W bramce wyjściowej wartości są analizowane i przypisuje się im wagę od -1 do 1. To reguluje dane przed ich przekazaniem do następnego kroku obliczeń. Wreszcie, zadaniem bramki zapomnienia jest odrzucenie informacji, które model uważa za niepotrzebne do podjęcia decyzji o charakterze danych wejściowych. Bramka zapomnienia używa funkcji sigmoidalnej na wartościach, zwracając liczby między 0 (zapomnij) a 1 (zachowaj).
Sieć neuronowa LSTM składa się z specjalnych warstw LSTM, które mogą interpretować sekwencyjne dane słów, oraz gęsto połączonych warstw, takich jak te opisane powyżej. Po przepuszczeniu danych przez warstwy LSTM, przechodzą one do gęsto połączonych warstw.








