AI 101
Hva er Overfitting?
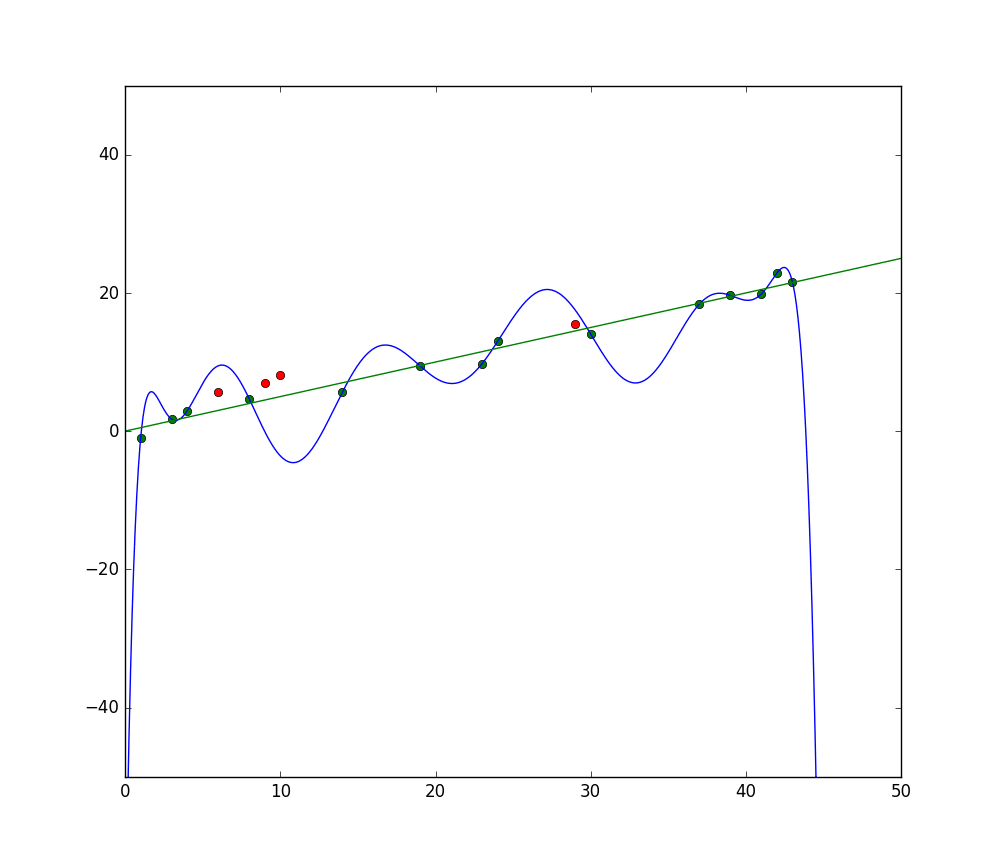
Hva er Overfitting?
Når du trener et neuralt nettverk, må du unngå overfitting. Overfitting er et problem innen maskinlæring og statistikk der en modell lærer mønsterene i en treningsdataset for godt, og perfekt forklarer treningsdataene, men mislykkes i å generalisere sin prediktive kraft til andre datasett.
For å si det på en annen måte, i tilfelle av en overfitting-modell, vil den ofte vise ekstremt høy nøyaktighet på treningsdatasettet, men lav nøyaktighet på data som er samlet inn og kjørt gjennom modellen i fremtiden. Dette er en rask definisjon av overfitting, men la oss gå gjennom konseptet om overfitting i mer detalj. La oss se på hvordan overfitting skjer og hvordan det kan unngås.
Forstå “Fit” og Underfitting
Det er nyttig å se på konseptet om underfitting og “fit” generelt når vi diskuterer overfitting. Når vi trener en modell, prøver vi å utvikle en ramme som er i stand til å forutsi naturen, eller klassen, av elementer i en datasett, basert på egenskapene som beskriver disse elementene. En modell bør være i stand til å forklare et mønster i en datasett og forutsi klassene til fremtidige datapunkter basert på dette mønsteret. Jo bedre modellen forklarer forholdet mellom egenskapene i treningssettet, jo mer “fit” er vår modell.

Blå linje representerer forutsigelser fra en modell som underfitter, mens den grønne linjen representerer en bedre fit-modell. Foto: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)








