Kunstig intelligens
Andrew Ng kritisere kulturen av overfitting i maskinlæring
Andrew Ng, en av de mest innflytelsesrike stemmene i maskinlæring de siste ti årene, uttrykker nå bekymring over i hvilken grad sektoren legger vekt på innovasjoner i modellarkitektur fremfor data – og spesielt, i hvilken grad den tillater ‘overfitte’ resultater å bli fremstilt som generaliserte løsninger eller fremgang.
Dette er sveipende kritikk av nåværende maskinlæringkultur, som kommer fra en av dens høyeste myndigheter, og har implikasjoner for tillit til en sektor som er preget av frykt for en tredje sammenbrudd av forretningsfortroende i AI-utvikling i løpet av seksti år.
Ng, en professor ved Stanford-universitetet, er også en av grunnleggerne av deeplearning.ai, og i mars publiserte han en skriv på organisasjonens nettsted som destillerte en nylig tale av ham ned til noen få kjerneanbefalinger:
Først og fremst, at forskningssamfunnet bør slutte å klage over at datarengjøring utgjør 80% av utfordringene i maskinlæring, og i stedet komme i gang med å utvikle robuste MLOps-metodologier og -praksiser.
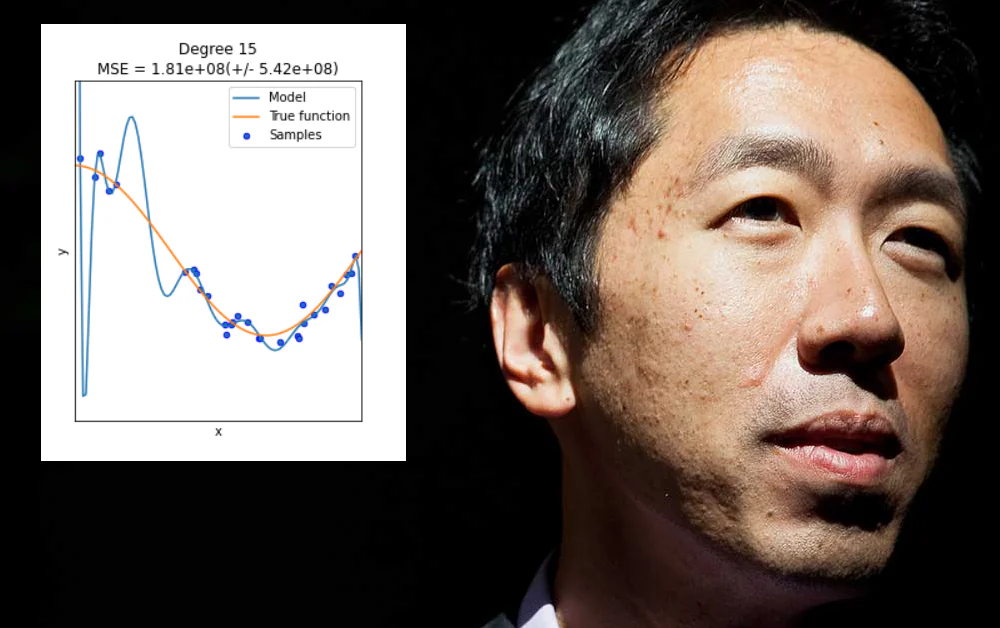
For det andre, at det bør flytte fokus bort fra de ‘lette seirene’ som kan oppnås ved å overfitte data til en maskinlæringsmodell, så den fungerer bra på den modellen, men svikter å generalisere eller å produsere en modell som kan deployes bredt.
Aktivt å møte utfordringen med dataarkitektur og -kurering
‘Min mening’, skrev Ng, ‘er at hvis 80 prosent av vårt arbeid er dataforberedelse, så er sikring av datakvalitet det viktige arbeidet til et maskinlæringslag.’
Han fortsatte:
‘I stedet for å regne med at ingeniører skal finne den beste måten å forbedre en datasett på, håper jeg vi kan utvikle MLOps-verktøy som hjelper å gjøre bygging av AI-systemer, inkludert bygging av høykvalitets datasett, mer gjentakende og systematisk.
‘MLOps er et nytt felt, og forskjellige mennesker definerer det forskjellig. Men jeg tror den viktigste organisatoriske prinsippet for MLOps-lag og -verktøy bør være å sikre en konsekvent og høykvalitets flyt av data gjennom alle fasene av et prosjekt. Dette vil hjelpe mange prosjekter å gå mer smidig.’
I en direktesendt Q&A-sesjon på Zoom i slutten av april, adresserte Ng applikasjonsmangelen i maskinlæringsanalyse-systemer for radiologi:
“Det viser seg at når vi samler inn data fra Stanford-sykehuset, så trener og tester vi på data fra samme sykehus, og vi kan publisere papirer som viser [algoritmene] er sammenlignbare med menneskelige radiologer når det gjelder å oppdage visse tilstander.
“…[Når] du tar samme modell, samme AI-system, til et eldre sykehus nedover gaten, med en eldre maskin, og teknikerne bruker en litt annerledes bildeprotokoll, så fører data-drift til at AI-systemets ytelse forringes betydelig. I motsetning til det, kan enhver menneskelig radiolog gå nedover gaten til det eldre sykehuset og gjøre det bra.”
Underspesifikasjon er ikke en løsning
Overfitting skjer når en maskinlæringsmodell er spesifikt designet for å tilpasse seg de eksentriske egenskapene til en bestemt datasett (eller måten data er formatert på). Dette kan innebære, for eksempel, å spesifisere vekter som vil produsere gode resultater fra den datasetten, men som ikke ‘generaliserer’ på andre data.
I mange tilfeller er slike parametre definert på ‘ikke-data’-aspekter av treningssettet, som for eksempel den spesifikke oppløsningen på den innhentede informasjonen, eller andre egenheter som ikke er garantert å gjenta seg over andre påfølgende datasett.
Til tross for at det ville være fint, er overfitting ikke et problem som kan løses ved å blindt utvide omfanget eller fleksibiliteten til dataarkitektur eller modell-design, når det som faktisk trengs, er vidt anvendelige og høyt relevante egenskaper som vil fungere bra over en rekke data-miljøer – en tornere utfordring.
I allminnelighet fører denne type ‘underspesifikasjon’ bare til de samme problemene som Ng nylig har beskrevet, hvor en maskinlæringsmodell feiler på usette data. Forskjellen i dette tilfelle er at modellen feiler ikke fordi data eller data-format er forskjellig fra den overfitte originale treningssettet, men fordi modellen er for fleksibel i stedet for for skjør.
Sent i 2020 kritiserte papiret Underspesifikasjon presenterer utfordringer for troverdighet i moderne maskinlæring denne praksisen, og bar navnene til ikke mindre enn førti maskinlæringsforskere og -vitenskapsmenn fra Google og MIT, blant andre institusjoner.
Papiret kritiserte ‘shortcut-læring’, og observerte måten underspesifiserte modeller kan ta av i ville retninger basert på den tilfeldige startpunktet modell-treningen begynner. Bidragsyterne observerer:
‘Vi har sett at underspesifikasjon er ubetydelig i praktiske maskinlærings-pipelines over mange domener. Faktisk, takket være underspesifikasjon, bestemmes substantielt viktige aspekter av beslutningene av tilfeldige valg som den tilfeldige seeden som brukes for parameterinitialisering.’
Økonomiske implikasjoner av å endre kulturen
Til tross for hans akademiske kvalifikasjoner, er Ng ingen luftig akademiker, men har dyp og høyt nivå industriell erfaring som medgrunnlegger av Google Brain og Coursera, som tidligere sjefsforsker for Big Data og AI hos Baidu, og som grunnlegger av Landing AI, som administrerer 175 millioner USD for nye startups i sektoren.
Når han sier “Hele AI, ikke bare helse, har en proof-of-concept-to-production gap”, er det ment som en vekker til en sektor hvis nåværende nivå av hype og flekket historie har stadig karakterisert det som en usikker langtidsforretningsinvestering, rammet av problemer med definisjon og omfang.
Likevel representerer proprietære maskinlærings-systemer som fungerer bra in-situ og feiler i andre miljøer den type markedstilgang som kunne belønne industri-investering. Fremstillingen av ‘overfitting-problemet’ i sammenheng med en yrkesmessig fare tilbyr en uærlig måte å monetisere bedriftsinvestering i åpen kilde-forskning, og å produsere (i praksis) proprietære systemer hvor replikasjon av konkurrenter er mulig, men problematisk.
Hvorvidt denne tilnærmingen vil fungere på lang sikt, avhenger av i hvilken grad ekte gjennombrudd i maskinlæring fortsatt krever større og større investeringer, og hvorvidt eller ikke alle produktive initiativer uunngåelig vil migrere til FAANG til en viss grad, på grunn av de kolossale ressursene som er nødvendige for hosting og operasjoner.












