
AI 101 m
Kas yra persirengimas?
Kas yra persirengimas?
Kai treniruojate neuroninį tinklą, turite vengti per didelio pritaikymo. Perteklinis yra mašininio mokymosi ir statistikos problema, kai modelis per gerai išmoksta mokymo duomenų rinkinio modelius, puikiai paaiškindamas mokymo duomenų rinkinį, bet nesugebėdamas apibendrinti jo nuspėjimo galios kitiems duomenų rinkiniams.
Kitaip tariant, per daug pritaikyto modelio atveju jis dažnai parodys ypač didelį mokymo duomenų rinkinio tikslumą, bet žemą duomenų, surinktų ir paleidžiamų per modelį, tikslumą ateityje. Tai greitas permontavimo apibrėžimas, bet panagrinėkime per didelio pritaikymo sąvoką išsamiau. Pažiūrėkime, kaip atsiranda perteklius ir kaip to galima išvengti.
„Tinkimo“ ir nepakankamo pritaikymo supratimas
Naudinga pažvelgti į nepakankamo pritaikymo sąvoką ir „pritaikyti“, kai kalbama apie perdėtą pritaikymą. Kai treniruojame modelį, bandome sukurti sistemą, kuri galėtų numatyti duomenų rinkinio elementų pobūdį arba klasę, remiantis tuos elementus apibūdinančiomis ypatybėmis. Modelis turėtų sugebėti paaiškinti duomenų rinkinio modelį ir pagal šį modelį numatyti būsimų duomenų taškų klases. Kuo geriau modelis paaiškina ryšį tarp treniruočių rinkinio ypatybių, tuo mūsų modelis yra „tinkamesnis“.
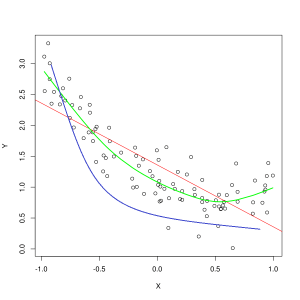
Mėlyna linija rodo netinkamo modelio prognozes, o žalia linija rodo geriau pritaikytą modelį. Nuotrauka: Pep Roca per Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Modelis, kuris prastai paaiškina ryšį tarp mokymo duomenų ypatybių ir todėl nesugeba tiksliai klasifikuoti būsimų duomenų pavyzdžių. nepakankamas pritaikymas treniruočių duomenis. Jei nubrėžtumėte numatytą netinkamo modelio santykį su faktine funkcijų ir etikečių sankirta, prognozės nukryptų nuo žymės. Jei turėtume grafiką su faktinėmis treniruočių rinkinio vertėmis, labai netinkamas modelis smarkiai praleistų daugumą duomenų taškų. Geriau tinkantis modelis gali nupjauti kelią per duomenų taškų centrą, o atskiri duomenų taškai nukrypsta nuo numatytų verčių tik šiek tiek.
Netinkamas pritaikymas dažnai gali atsirasti, kai nepakanka duomenų tiksliam modeliui sukurti arba bandant sukurti linijinį modelį su nelinijiniais duomenimis. Daugiau treniruočių duomenų ar daugiau funkcijų dažnai padės sumažinti netinkamą pritaikymą.
Taigi kodėl gi nesukūrus modelio, kuris puikiai paaiškintų kiekvieną mokymo duomenų tašką? Tikrai tobulas tikslumas yra pageidautinas? Sukūrus modelį, kuris per gerai išmoko treniruočių duomenų šablonus, sukelia perteklinį pritaikymą. Mokymo duomenų rinkinys ir kiti būsimi duomenų rinkiniai, kuriuos paleisite naudodami modelį, nebus visiškai tokie patys. Tikėtina, kad jie bus labai panašūs daugeliu atžvilgių, tačiau taip pat skirsis pagrindiniais būdais. Todėl modelio, kuris puikiai paaiškina mokymo duomenų rinkinį, sukūrimas reiškia, kad jūs gaunate teoriją apie savybių ryšį, kuri nėra gerai apibendrinta kitiems duomenų rinkiniams.
Overfitting supratimas
Pernelyg pritaikymas įvyksta, kai modelis per gerai išmoksta mokymo duomenų rinkinio detales, todėl modelis nukenčia, kai prognozės daromos remiantis išoriniais duomenimis. Taip gali nutikti, kai modelis ne tik sužino duomenų rinkinio ypatybes, bet ir sužino apie atsitiktinius svyravimus arba triukšmas duomenų rinkinyje, suteikdami svarbą šiems atsitiktiniams / nesvarbiems įvykiams.
Naudojant netiesinius modelius, labiau tikėtina, kad jie bus pritaikyti per daug, nes jie yra lankstesni mokantis duomenų funkcijų. Neparametriniai mašininio mokymosi algoritmai dažnai turi įvairius parametrus ir metodus, kurie gali būti taikomi siekiant apriboti modelio jautrumą duomenims ir taip sumažinti perteklinį pritaikymą. Pavyzdžiui, sprendimų medžio modeliai yra labai jautrūs permontavimui, tačiau naudojant metodą, vadinamą genėjimu, galima atsitiktinai pašalinti kai kurias detales, kurias išmoko modelis.
Jei modelio prognozes nubrėžtumėte X ir Y ašyse, gautumėte numatymo liniją, kuri svyruoja pirmyn ir atgal, o tai atspindi faktą, kad modelis per daug stengėsi suderinti visus duomenų rinkinio taškus. jo paaiškinimas.
Perdengimo valdymas
Kai apmokome modelį, idealiu atveju norime, kad modelis nepadarytų klaidų. Kai modelio našumas artėja prie teisingų visų mokymo duomenų rinkinio duomenų taškų numatymo, tinkamumas tampa geresnis. Tinkamas modelis gali paaiškinti beveik visą treniruočių duomenų rinkinį be perdėto pritaikymo.
Modeliui treniruojant jo našumas laikui bėgant gerėja. Modelio klaidų lygis mažės, kai praeis treniruočių laikas, tačiau jis mažėja tik iki tam tikro taško. Taškas, kai modelio našumas bandomajame rinkinyje vėl pradeda kilti, paprastai yra taškas, kai įvyksta permontavimas. Siekdami geriausiai pritaikyti modelį, norime sustabdyti modelio mokymą ties mažiausio praradimo tašku treniruočių rinkinyje, kol klaida vėl pradės didėti. Optimalų sustojimo tašką galima nustatyti nubraižant modelio našumą per visą treniruotės laiką ir sustabdant treniruotę, kai nuostoliai yra mažiausi. Tačiau viena rizika, susijusi su šiuo kontrolės, ar nėra permontavimo, metodo, yra ta, kad mokymo galutinio taško nurodymas remiantis testo atlikimu reiškia, kad bandymo duomenys šiek tiek įtraukiami į mokymo procedūrą ir praranda savo „nepaliestų“ duomenų statusą.
Yra keletas skirtingų būdų, kaip kovoti su pertekliumi. Vienas iš būdų, kaip sumažinti permontavimą, yra naudoti pakartotinio atrankos taktiką, kuri veikia įvertinant modelio tikslumą. Taip pat galite naudoti a patvirtinimas duomenų rinkinį, o ne bandomąjį duomenų rinkinį, ir pavaizduokite mokymo tikslumą pagal patvirtinimo rinkinį. Taip jūsų bandymo duomenų rinkinys nebus matomas. Populiarus pakartotinio atrankos metodas yra kryžminis K-lanksčių patvirtinimas. Šis metodas leidžia padalyti duomenis į poaibius, pagal kuriuos apmokomas modelis, o tada analizuojamas modelio našumas poaibiuose, siekiant įvertinti, kaip modelis veiks su išoriniais duomenimis.
Kryžminio patvirtinimo naudojimas yra vienas geriausių būdų įvertinti modelio tikslumą pagal neregėtus duomenis, o kartu su patvirtinimo duomenų rinkiniu dažnai galima sumažinti perteklinį pritaikymą.










