
AI 101 m
Kas yra matmenų mažinimas?
Kas yra matmenų mažinimas?
Matmenų mažinimas yra procesas, naudojamas sumažinti duomenų rinkinio matmenis, paimant daug funkcijų ir pateikiant jas kaip mažiau funkcijų. Pavyzdžiui, matmenų mažinimas gali būti naudojamas dvidešimties funkcijų duomenų rinkiniui sumažinti iki kelių funkcijų. Matmenų mažinimas dažniausiai naudojamas neprižiūrimas mokymasis užduotis, kad automatiškai sukurtumėte klases iš daugelio funkcijų. Kad geriau suprastum kodėl ir kaip naudojamas matmenų mažinimas, apžvelgsime problemas, susijusias su didelių matmenų duomenimis, ir populiariausius matmenų mažinimo būdus.
Dėl didesnių matmenų permontuojama
Matmenys reiškia funkcijų / stulpelių skaičių duomenų rinkinyje.
Dažnai manoma, kad mašininio mokymosi metu daugiau funkcijų yra geresnės, nes sukuriamas tikslesnis modelis. Tačiau daugiau funkcijų nebūtinai reiškia geresnį modelį.
Duomenų rinkinio funkcijos gali labai skirtis atsižvelgiant į tai, kiek jos yra naudingos modeliui, o daugelis funkcijų yra mažai svarbios. Be to, kuo daugiau funkcijų yra duomenų rinkinyje, tuo daugiau pavyzdžių reikia, kad būtų užtikrinta, jog skirtingi funkcijų deriniai būtų tinkamai pateikti duomenyse. Todėl pavyzdžių skaičius didėja proporcingai funkcijų skaičiui. Daugiau pavyzdžių ir daugiau funkcijų reiškia, kad modelis turi būti sudėtingesnis, o modeliams tampant sudėtingesniems, jie tampa jautresni permontavimui. Modelis per gerai įsisavina mokymo duomenų šablonus ir nesugeba apibendrinti, kad nebūtų imties duomenų.
Duomenų rinkinio matmenų sumažinimas turi keletą privalumų. Kaip minėta, paprastesni modeliai yra mažiau linkę permontuoti, nes modelis turi daryti mažiau prielaidų, kaip funkcijos yra susijusios viena su kita. Be to, mažesni matmenys reiškia, kad norint išmokyti algoritmus reikia mažesnės skaičiavimo galios. Panašiai reikia mažiau vietos duomenų rinkiniui, kurio matmenys yra mažesni. Sumažinus duomenų rinkinio matmenis, taip pat galite naudoti algoritmus, kurie netinka duomenų rinkiniams su daugybe funkcijų.
Bendrieji matmenų mažinimo metodai
Matmenų mažinimas gali būti atliekamas pasirenkant elementą arba elemento inžineriją. Funkcijų pasirinkimas yra vieta, kur inžinierius nustato svarbiausias duomenų rinkinio ypatybes funkcijų inžinerija yra naujų funkcijų kūrimo procesas, derinant arba transformuojant kitas savybes.
Funkcijų pasirinkimas ir inžinerija gali būti atliekama programiškai arba rankiniu būdu. Rankiniu būdu pasirenkant ir projektuojant funkcijas, įprasta vizualizuoti duomenis, kad būtų galima nustatyti sąsajas tarp funkcijų ir klasių. Matmenų mažinimas tokiu būdu gali užtrukti daug laiko, todėl kai kurie iš labiausiai paplitusių matmenų mažinimo būdų apima algoritmų, esančių bibliotekose, pvz., Scikit-learn for Python, naudojimą. Šie bendri matmenų mažinimo algoritmai apima: pagrindinių komponentų analizę (PCA), vienetinės vertės skaidymą (SVD) ir linijinę diskriminacinę analizę (LDA).
Neprižiūrimų mokymosi užduočių matmenų mažinimui naudojami algoritmai paprastai yra PCA ir SVD, o prižiūrimo mokymosi matmenų mažinimo algoritmai paprastai yra LDA ir PCA. Prižiūrimų mokymosi modelių atveju naujai sukurtos funkcijos tiesiog įvedamos į mašininio mokymosi klasifikatorių. Atminkite, kad čia aprašyti naudojimo atvejai yra tik bendri naudojimo atvejai, o ne vienintelės sąlygos, kuriomis šie metodai gali būti naudojami. Pirmiau aprašyti matmenų mažinimo algoritmai yra tik statistiniai metodai ir jie naudojami ne mašininio mokymosi modeliuose.
Pagrindinių komponentų analizė

Nuotrauka: Matrica su pagrindiniais komponentais
Pagrindinių komponentų analizė (PCA) yra statistinis metodas, analizuojantis duomenų rinkinio charakteristikas/ypatybes ir apibendrinantis tas savybes, kurios turi didžiausią įtaką. Duomenų rinkinio ypatybės yra sujungtos į reprezentacijas, kurios išlaiko daugumą duomenų savybių, bet yra paskirstytos mažiau aspektų. Galite manyti, kad tai yra duomenų „nuleidimas“ nuo aukštesnio matmens atvaizdavimo iki tik kelių matmenų.
Kaip pavyzdį, kai PCA gali būti naudinga, pagalvokite apie įvairius vyno apibūdinimo būdus. Nors galima apibūdinti vyną naudojant daug specifinių savybių, pvz., CO2 lygį, aeracijos lygį ir kt., tokios specifinės savybės gali būti gana nenaudingos, kai bandoma identifikuoti konkrečią vyno rūšį. Vietoj to, būtų protingiau nustatyti tipą pagal bendresnius požymius, pvz., skonį, spalvą ir amžių. PCA gali būti naudojamas norint sujungti konkretesnes funkcijas ir sukurti funkcijas, kurios yra bendresnės, naudingesnės ir mažiau gali sukelti permontavimą.
PCA atliekama nustatant, kaip įvesties ypatybės skiriasi nuo vidurkio viena kitos atžvilgiu, nustatant, ar tarp savybių yra kokių nors ryšių. Tam sukuriama kovariantinė matrica, sudaryta iš kovariacijų, susijusių su galimomis duomenų rinkinio ypatybių poromis. Tai naudojama koreliacijai tarp kintamųjų nustatyti, kai neigiama kovariacija rodo atvirkštinę koreliaciją, o teigiama koreliacija rodo teigiamą koreliaciją.
Pagrindiniai (įtakingiausi) duomenų rinkinio komponentai sukuriami kuriant tiesines pradinių kintamųjų kombinacijas, kurios atliekamos naudojant tiesinės algebros sąvokas, vadinamas savąsias reikšmes ir savuosius vektorius. Deriniai kuriami taip, kad pagrindiniai komponentai nebūtų tarpusavyje susiję. Didžioji dalis informacijos, esančios pradiniuose kintamuosiuose, yra suspausta į keletą pirmųjų pagrindinių komponentų, o tai reiškia, kad buvo sukurtos naujos funkcijos (pagrindiniai komponentai), kuriose yra informacija iš pradinio duomenų rinkinio mažesnėje erdvėje.
Vienaskaitos reikšmės skaidymas
Nuotrauka: Cmglee – nuosavas darbas, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
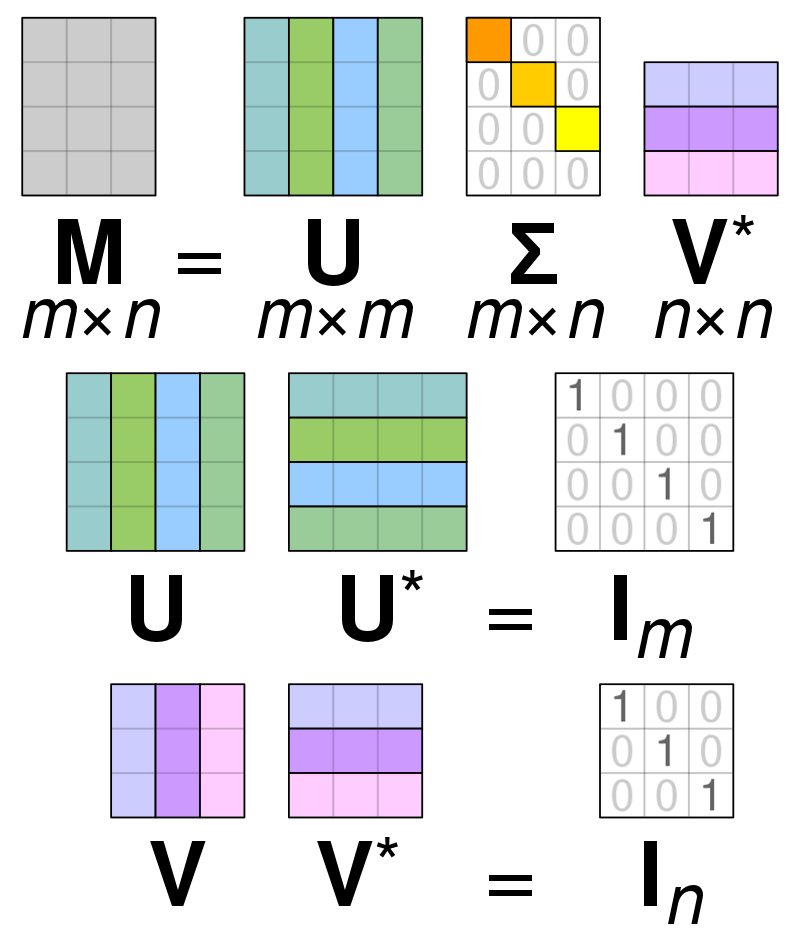
Vienaskaitos reikšmės skaidymas (SVD) is naudojamas matricos reikšmėms supaprastinti, sumažinant matricą iki jos sudedamųjų dalių ir palengvinant skaičiavimus su ta matrica. SVD gali būti naudojamas tiek tikrosioms, tiek sudėtingoms matricoms, tačiau šio paaiškinimo tikslais bus nagrinėjama, kaip išskaidyti realių verčių matricą.
Tarkime, kad turime matricą, sudarytą iš realios vertės duomenų, o mūsų tikslas yra sumažinti stulpelių / funkcijų skaičių matricoje, panašiai kaip PCA tikslas. Kaip ir PCA, SVD suglaudins matricos matmenis, išsaugodamas kuo daugiau matricos kintamumo. Jei norime dirbti su matrica A, matricą A galime pavaizduoti kaip tris kitas matricas, vadinamas U, D ir V. Matricą A sudaro originalūs x * y elementai, o matricą U sudaro elementai X * X (tai yra ortogonalioji matrica). Matrica V yra skirtinga stačiakampė matrica, turinti y * y elementus. Matricoje D yra elementai x * y ir ji yra įstrižainė.
Norėdami išskaidyti matricos A reikšmes, turime konvertuoti pradines vienaskaitos matricos reikšmes į įstrižainės reikšmes, rastas naujoje matricoje. Dirbant su stačiakampėmis matricomis, jų savybės nesikeičia padauginus iš kitų skaičių. Todėl pasinaudodami šia savybe galime aproksimuoti matricą A. Kai padauginame stačiakampes matricas kartu su matricos V transponavimu, gaunama lygiavertė matrica mūsų pradinei A.
Kai matrica a suskaidoma į matricas U, D ir V, jose yra A matricoje rasti duomenys. Tačiau kairiausiose matricų stulpeliuose bus saugoma dauguma duomenų. Galime paimti tik šiuos pirmuosius kelis stulpelius ir turėti matricos A, kuri turi daug mažiau matmenų ir daugumą duomenų, vaizdą.
Tiesinė diskriminacinė analizė

Kairėje: matrica prieš LDA, dešinėje: ašis po LDA, dabar atskiriama
Linijinė diskriminacinė analizė (LDA) yra procesas, kuris paima duomenis iš daugiamačio grafiko ir perprojektuoja jį į tiesinį grafiką. Tai galite įsivaizduoti galvodami apie dvimatį grafiką, užpildytą duomenų taškais, priklausančiais dviem skirtingoms klasėms. Tarkime, kad taškai yra išsibarstę taip, kad nebūtų galima nubrėžti linijos, kuri tvarkingai atskirtų dvi skirtingas klases. Norint išspręsti šią situaciją, 2D diagramoje rasti taškai gali būti sumažinti iki 1D grafiko (linijos). Šioje eilutėje bus paskirstyti visi duomenų taškai, ir tikimasi, kad ją bus galima suskirstyti į dvi dalis, kurios atspindi geriausią įmanomą duomenų atskyrimą.
Vykdant LDA yra du pagrindiniai tikslai. Pirmasis tikslas yra sumažinti klasių dispersiją, o antrasis tikslas yra maksimaliai padidinti atstumą tarp dviejų klasių vidurkių. Šie tikslai pasiekiami sukuriant naują ašį, kuri bus 2D diagramoje. Naujai sukurta ašis atskiria dvi klases pagal anksčiau aprašytus tikslus. Sukūrus ašį, 2D grafike rasti taškai dedami išilgai ašies.
Norint perkelti pradinius taškus į naują vietą išilgai naujos ašies, reikia atlikti tris veiksmus. Pirmame žingsnyje klasių atskiriamumui apskaičiuoti naudojamas atstumo tarp atskirų klasių vidurkis (klasių dispersija). Antrame etape apskaičiuojama dispersija skirtingose klasėse, kuri atliekama nustatant atstumą tarp imties ir atitinkamos klasės vidurkio. Paskutiniame etape sukuriama žemesnių matmenų erdvė, kuri maksimaliai padidina klasių dispersiją.
LDA technika pasiekia geriausių rezultatų, kai tikslinėms klasėms skirtos priemonės yra toli viena nuo kitos. LDA negali efektyviai atskirti klasių tiesine ašimi, jei paskirstymo priemonės sutampa.










