人工知能
ランダムノイズではなく実際の画像でコンピュータビジョンモデルをトレーニングする

MITコンピュータサイエンス&人工知能研究所(CSAIL)の研究者は、コンピュータビジョンデータセットでランダムノイズ画像を使用してコンピュータビジョンモデルをトレーニングすることを試み、予想に反してこの方法は驚くほど有効であることがわかった:

実験からの生成モデル、パフォーマンスで並べ替え。 ソース: https://openreview.net/pdf?id=RQUl8gZnN7O
人気のコンピュータビジョンアーキテクチャに明らかな「視覚的なごみ」を入力することは、このようなパフォーマンスをもたらすべきではない。上記の画像の右端、黒い列は、4つの「実際の」データセット(Imagenet-100)の精度スコアを表している。先行する「ランダムノイズ」データセット(色々な色で表現されている、上部左側のインデックスを参照)はそれに匹敵することができないが、ほとんどが精度の敬遠可能な上限と下限(赤い破線)の中にある。
この意味で「精度」とは、結果が必ずしも顔、教会、ピザ、または画像合成システム(たとえば、生成対抗ネットワークまたはエンコーダ/デコーダフレームワーク)を作成するために興味があるドメインのいずれかのように見えることを意味しない。
それよりも、CSAILモデルの「真実」を画像データから導き出したということである。そうでなければ、構造化されていない画像データから供給することができない。
多様性 vs. 自然さ
これらの結果は、過剰適合に帰することができない。Open Reviewでの著者とレビューアーの間の活発な議論は、視覚的に多様なデータセット(「枯れた葉」、「フラクタル」、「手続き的ノイズ」など、下の画像を参照)の異なるコンテンツをトレーニングデータセットに組み合わせると、実験で精度が向上することを示している。
これは、新しいタイプの「過少適合」を示唆しており、「多様性」が「自然さ」を上回る。
実験で使用されたさまざまなランダム画像データセットのプロジェクトページ。 ソース: https://mbaradad.github.io/learning_with_noise/
研究者によって得られた結果は、画像ベースのニューラルネットワークと、毎年驚くほど大量に投入される「現実の」画像との根本的な関係を疑問視し、画像データセットを取得、キュレーション、またはその他の方法で操作する必要性は最終的に冗長になる可能性があることを示唆している。著者は次のように述べている:
‘現在の視覚システムは巨大なデータセットでトレーニングされており、これらのデータセットにはコストが伴う:キュレーションは高価であり、人間の偏見を継承し、プライバシーと使用権に関する懸念がある。こうしたコストに対抗するために、安価なデータソース(例えば、ラベル付けされていない画像)から学ぶことに興味が高まっている。
‘この論文では、実際の画像データセットを完全に排除し、手続き的ノイズプロセスから学ぶことができるかどうかを疑問にしている.’
研究者は、現在の機械学習アーキテクチャが、予想よりもはるかに基本的(または、少なくとも予想外)なものを画像から推測している可能性があり、そして「無意味」な画像が、たとえアドホックな合成データを使用していても、より安価に多くの知識を提供できる可能性があると示唆している。
‘視覚システムをトレーニングするための合成データに適した2つの重要な特性を特定した:1)自然さ、2)多様性。興味深いことに、最も自然なデータが常に最良のものではなく、自然さは多様性のコストで来ることがある。
‘自然なデータが役立つことは驚くことではないが、実際には、大規模な実データには価値があることを示唆している。ただし、私たちが発見したのは、データが「実際の」ものである必要はないが、「自然な」ものでなければならない、つまり、実際のデータの構造的な特性を捉えなければならないということである。
‘これらの特性の多くは、シンプルなノイズモデルで捉えることができる.’

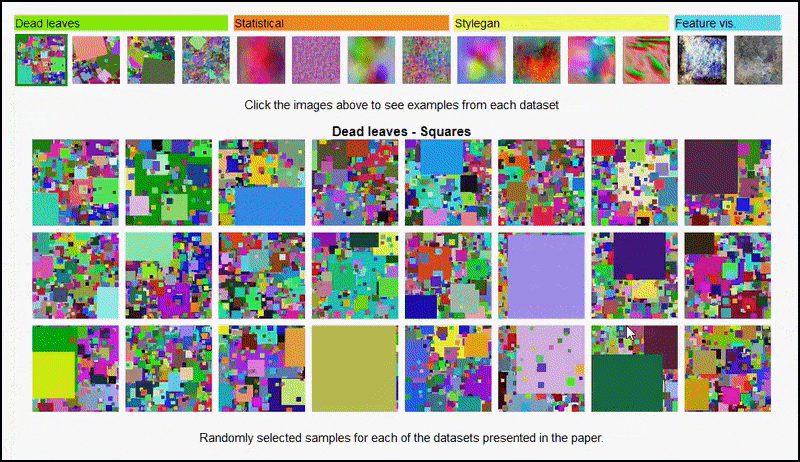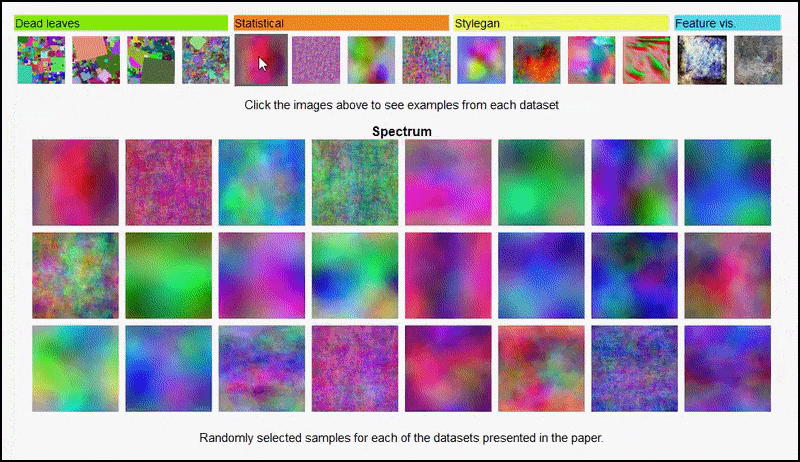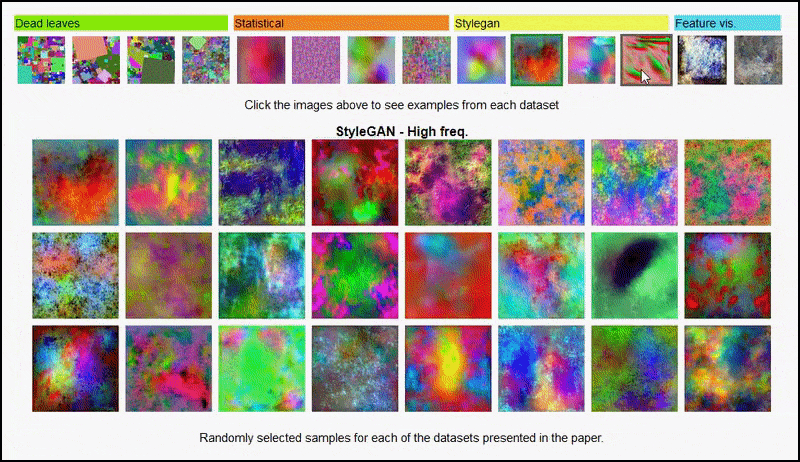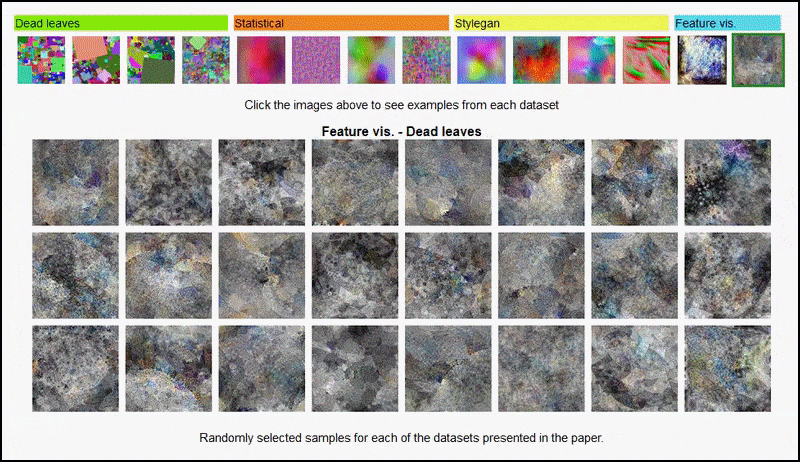
実験で使用されたさまざまな「ランダム画像」データセットの特徴の視覚化、アレックスネット由来のエンコーダー、3番目と5番目(最終)の畳み込み層をカバー。ここで使用される方法は、2017年のGoogle AIの研究に従っている。
論文は、シドニーの第35回ニューラル情報処理システム会議(NeurIPS 2021)で発表され、CSAILの6人の研究者によって書かれ、同等の貢献がある。
この研究は、コンセンサスによってNeurIPS 2021のスポットライトセレクションに推薦され、ピアレビューアーはこの論文を「科学的なブレークスルー」と呼び、「研究の素晴らしい分野」を開拓したと評価している。
論文では、著者は次のように結論付けている:
‘過去の研究から得られた結果を使用して設計されたこれらのデータセットは、視覚的な表現を成功的にトレーニングすることができることを示した。私たちは、この論文が、構造化されたノイズを生成する新しい生成モデルを生み出す研究を刺激することを希望する。さらに高いパフォーマンスを達成できるような、さまざまな視覚タスクで使用することができる.’
‘ImageNetの事前トレーニングで得られるパフォーマンスに匹敵することは可能かもしれない。特定のタスクに特化した大規模なトレーニングセットがない場合、標準的な実データセット(たとえばImageNet)を使用するよりも、最適な事前トレーニングは、実際のデータセットを使用するのではなく、ランダムノイズを使用することかもしれない.’












