人工知能
MIT: マシンラーニングを用いた主要ニュース媒体のメディアバイアス測定

MITの研究では、米国およびその他の国を代表する約100の最大かつ最も影響力のあるニュース媒体、包括して83の最も影響力のある印刷ニュース出版物を対象に、マシンラーニング技術を用いて偏った表現を特定しました。これは、自動化システムが出版物の政治的性格を自動的に分類し、読者が情熱を傾けるトピックについて媒体の倫理的立場をより深く理解する道を示す研究努力です。
この研究は、特定の表現でトピックがどのように扱われるか、たとえば《不法滞在移民》《違法移民》、《胎児》《未生まれの赤ちゃん》、《デモ参加者》《無政府主義者》に焦点を当てています。
このプロジェクトでは、自然言語処理(NLP)技術を使用して、約100のニュース媒体から約300万件の記事を抽出し、左寄り・右寄りの偏りを明らかにする広範なマッピングを作成しました。これにより、調査対象の出版物の《偏り景観》をナビゲートできます。
Samantha D’AlonzoとMax TegmarkによるMIT物理学部の《paper》は、多くの「事実検証」イニシアチブが、数多くの「フェイクニュース」スキャンダルを受けて、特定の利益のために奉仕し、不誠実と解釈される可能性があると述べています。このプロジェクトは、ニュースコンテキストにおける偏り言語と「影響」言語の使用を研究するためのよりデータ駆動型のアプローチを提供することを目的としています。

《研究から導かれた、左から右へのフレーズのスペクトル。》 ソース: https://arxiv.org/pdf/2109.00024.pdf
NLP処理
研究のソースデータは、オープンソースの《Newspaper3Kデータベース》から取得され、100のメディアニュースソース、包括して83の新聞から約307万8624件の記事で構成されます。新聞は、そのリーチに基づいて選択され、オンラインメディアソースには、軍事ニュース分析サイト《Defense One》や《Science》からの記事も含まれます。

《研究で使用されたソース。》
論文では、ダウンロードされたテキストが「最小限」に前処理されたと報告されています。直接引用は除外されました。なぜなら、この研究はジャーナリストが選択した言語(引用の選択はそれ自体が《興味深い研究分野》である)に興味があるからです。
イギリス英語の綴りはアメリカ英語に変更され、全ての句読点は除去され、序数以外の数字も除去されました。初期の文の先頭の文字は小文字に変換されましたが、その他の大文字は保持されました。
最も一般的な100,000のフレーズが特定され、最終的にランク付け、精査、結合されて、約100のニュース媒体から約300万件の記事を網羅する広範なマッピングが作成され、ナビゲート可能な《偏り景観》が作成されました。
《paper》は、MIT物理学部のSamantha D’AlonzoとMax Tegmarkによるもので、最近の「事実検証」イニシアチブが、数多くの「フェイクニュース」スキャンダルを受けて、特定の利益のために奉仕し、不誠実と解釈される可能性があると述べています。このプロジェクトは、ニュースコンテキストにおける偏り言語と「影響」言語の使用を研究するためのよりデータ駆動型のアプローチを提供することを目的としています。
paperは、MITのSamantha D’AlonzoとMax Tegmarkによって書かれ、最近の「事実検証」イニシアチブが、数多くの「フェイクニュース」スキャンダルを受けて、特定の利益のために奉仕し、不誠実と解釈される可能性があると述べています。このプロジェクトは、ニュースコンテキストにおける偏り言語と「影響」言語の使用を研究するためのよりデータ駆動型のアプローチを提供することを目的としています。
ナットピッキング
初期テストは「Black lives matter」のトピックに焦点を当て、データ全体でフレーズバイアスと価値シノニムを判断することができました。
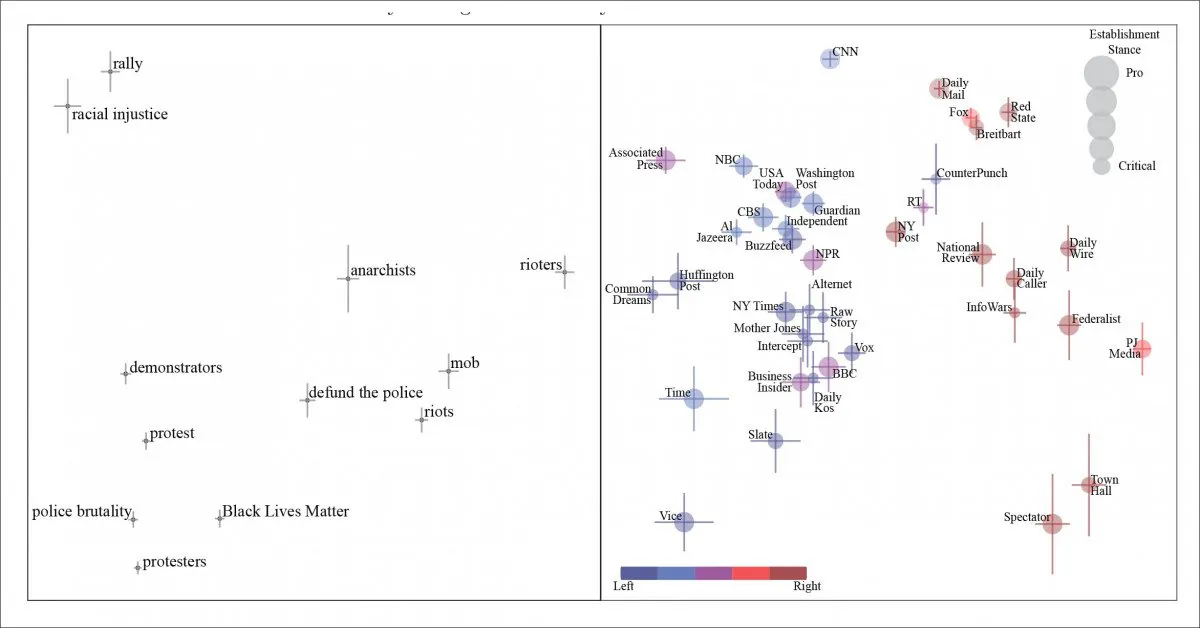
《Black Lives Matter(BLM)に関する記事の一般化された主成分。左から右に、デモ参加者、無政府主義者、そして最も右の端では「暴徒」として特徴付けられる市民的行動に参加する人々を示しています。右側のパネルには、フレーズの出典となる新聞が表示されています。》
「抗議者」は、媒体の政治的立場に沿って「無政府主義者」から「暴徒」へと移行しますが、論文では、NLP抽出と分析の立場が「ナットピッキング」の慣行によって妨げられることも指摘されています。ここで、「ナットピッキング」とは、媒体が異なる政治的セグメントの社会によって有効と見なされるフレーズを引用し、読者がそのフレーズを否定的に見ることを依存できることを意味します。論文では、「警察を解体する」というフレーズをこの例として挙げています。
趣味馬
ある特定の政治的立場を持つニュース媒体が予測可能な方法で分割されない、軍事支出のようなトピックがあります。論文では、左寄りのCNNが軍事支出のトピックで、右寄りのNational ReviewやFox Newsと並んでいたことを発見しました。
一般的には、政治的立場は他のフレーズによって判断できます。たとえば、「軍事産業複合体」と「防衛産業」のようなフレーズを使用することです。結果は、前者は《Canary》や《American Conservative》のような既成秩序批判的な媒体によって使用されるのに対し、後者はFoxやCNNによって使用されることを示しています。
研究では、既成秩序批判的な言語からプロ既成秩序言語へのいくつかの進歩が確立されています。たとえば、「銃殺された」と「殺害」、「受刑者」と「拘留者」、「石油生産者」と「大手石油会社」などです。

《既成秩序バイアスの価値シノニム、上から下へ。》
研究では、媒体がその基盤となる政治的立場から「スイングアウェイ」することがあることを認めています。たとえば、バイバレントフレーズの使用や、他の動機によるものです。たとえば、1828年に設立された英国右派出版物《The Spectator》は、一般的な政治的流れに反する左派の考え方の記事を頻繁に、目立つように特集しています。読者を保護するために、または読者の反応を引き出すために、どちらかが行われているかは、推測の問題です。機械学習システムが明確で一貫したトークンを探している場合、簡単な場合ではありません。
これらの特定の「趣味馬」と個々のニュース組織における「不協和な」視点の使用は、研究が最終的に提示する左から右へのマッピングを多少混乱させますが、政治的所属について広い示唆を提供します。

抑制された重要性
2021年9月2日に発表され、2021年8月末に公開されたこの論文は、比較的少ない注目を集めています。これは、主流メディアを対象とした批判的な研究が、主流メディアによって熱心に受け入れられない可能性があるためかもしれません。ただし、著者が、さまざまな問題についての有力で影響力のあるメディア出版物の立場を明確に階層化し、左寄りまたは右寄りに傾く程度の集約値を示さなかったためである可能性もあります。実際、著者は結果の潜在的な発炎性の影響を和らげる努力を払っています。
同様に、プロジェクトの《published data》は、単語の発生回数を示していますが、匿名化されているため、研究対象の媒体のバイアスを明確に理解することは困難です。プロジェクトを何らかの方法で運用化しない限り、論文に提示された例のみが残ります。
将来のこのような研究は、トピックの扱い方だけでなく、トピックが全く扱われていないかどうかも考慮することが役立つでしょう。なぜなら、《沈黙は多くを語る》、そしてその自体が、予算の制限やニュース選定を導くその他の実用的な要因よりも、はるかに多くの政治的性格を示唆するからです。
それでも、MITの研究は、これまでで最大のものであり、将来の分類システム、さらには読者が現在読んでいる出版物の政治的色合いを警告するブラウザープラグインのような二次的な技術のフレームワークを形成する可能性があります。
バブル、バイアス、反発
さらに、こうしたシステムが、アルゴリズム推奨システムの最も議論の多い側面の1つである、読者を、対立する、または挑戦的な見解を示さない環境に導く可能性があるかどうかを考慮する必要があります。これは、読者の立場をさらに強化し、コア問題に関する彼らの立場をさらに硬化させる可能性があります。
こうした《コンテンツバブル》が「安全な環境」であるか、知的成長の障害であるか、または部分的なプロパガンダに対する保護であるかは、価値判断であり、機械学習システムの機械的な、統計的な立場からアプローチするのは難しい哲学的な問題です。
さらに、MITの研究がデータによって結果を定義するように努めたように、フレーズの政治的価値の分類も、ある種の価値判断であり、言語が《有毒または論争的コンテンツを新しいフレーズに再コード化する》能力に簡単に対処できないものです。
このようなコード化が人気のオンラインシステムに埋め込まれる場合、主要なニュース媒体の倫理的、政治的温度をマッピングする継続的な努力が、バイアスを認識するAIの能力と、出版社が立場を表現するための進化するイディオムを常に上回るように設計されたものとの間の冷戦に発展する可能性があります。












