人工知能
Enfabrica、Ethernetベースのメモリファブリックを発表 – 大規模AI推論を再定義する可能性
Enfabricaは、Nvidiaが支援するシリコンバレーのスタートアップで、大規模AIワークロードの展開とスケーリングの方法を大幅に変える可能性のあるブレークスルー製品を発表しました。同社の新しいElastic Memory Fabric System (EMFASYS)は、最初の商用利用可能なEthernetベースのメモリファブリックで、生成的なAI推論のコアボトルネックであるメモリアクセスに特に設計されています。
AIモデルがより複雑になり、コンテキストに応じて変化し、永続的なセッションを必要とするにつれて、1つのユーザーセッションあたりの大量のメモリが必要になります。EMFASYSは、メモリをコンピューティングから切り離すための新しいアプローチを提供し、AIデータセンターがパフォーマンスを大幅に改善し、コストを削減し、最も高価なリソースであるGPUの利用率を高めることができます。
メモリファブリックとは何か – そしてなぜ重要か?
従来、データセンター内のメモリは、サーバーまたはノードに密接に結び付けられてきました。各GPUまたはCPUには、直接接続された高帯域幅メモリ(通常はGPUのHBMまたはCPUのDRAM)しかアクセスできません。このアーキテクチャは、ワークロードが小さく予測可能な場合には機能します。しかし、生成的なAIはゲームを変えました。LLMには、大きなコンテキストウィンドウ、ユーザーの履歴、およびマルチエージェントメモリへのアクセスが必要です。すべてこれらは迅速に遅延なく処理する必要があります。これらのメモリ要求は、ローカルメモリの利用可能な容量を超えることが多く、ボトルネックが作成され、GPUコアがストランドされ、インフラストラクチャコストが増加します。
メモリファブリックは、これを解決するためにメモリを共有された分散リソースに変換します。クラスター内の任意のGPUまたはCPUがアクセスできるネットワーク接続型メモリプールのようです。データセンターのラック内に「メモリクラウド」を作成するという考え方です。サーバー全体にメモリを複製したり、高価なHBMを過負荷したりするのではなく、ファブリックはメモリを集約し、分離し、オンデマンドで高速ネットワーク経由でアクセスできるようにします。これにより、AI推論ワークロードは、単一ノードの物理メモリ制限に縛られることなく、より効率的にスケールできます。
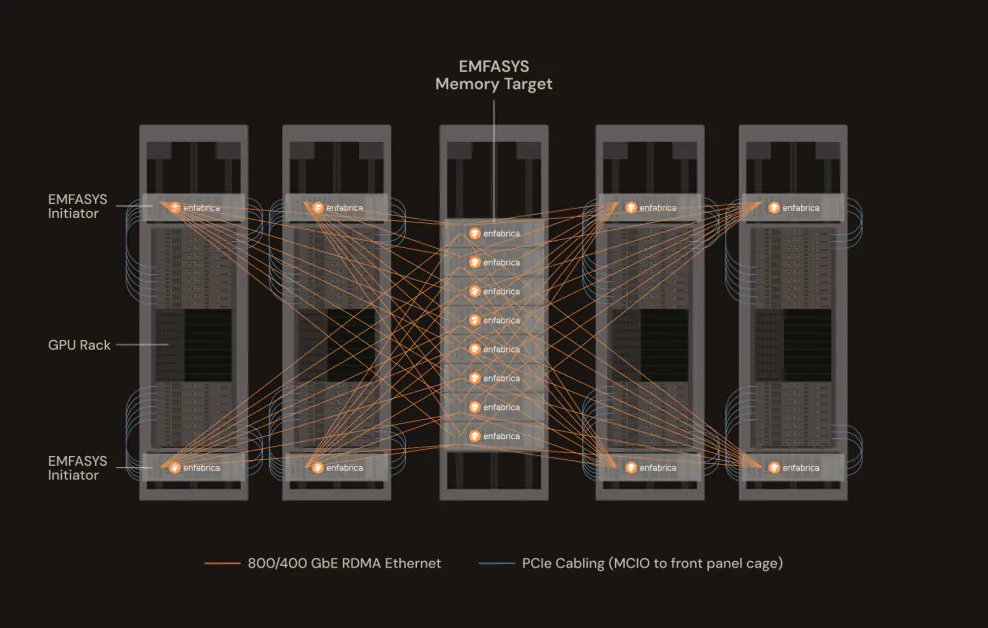
Enfabricaのアプローチ:EthernetとCXL、ついに一緒に
EMFASYSは、2つの強力なテクノロジー、RDMA over EthernetとCompute Express Link (CXL)を組み合わせて、ラックスケールのメモリアーキテクチャを実現します。前者は、標準のEthernetネットワーク上で超低遅延、高スループットのデータ転送を可能にします。後者は、メモリをCPUとGPUから切り離し、共有リソースとしてプール化し、高速のCXLリンク経由でアクセスできるようにします。
EMFASYSの核心は、EnfabricaのACF-Sチップです。これは、3.2テラビット/秒(Tbps)の「SuperNIC」で、ネットワーキングとメモリコントロールを1つのデバイスに融合させます。このチップにより、サーバーはラック全体に分散された大量のコモディティDDR5 DRAM(ノードあたり最大18テラバイト)とインターフェースすることができます。重要なのは、これが標準のEthernetポートを使用して行われるため、運用者は、独自のインターコネクトに投資することなく、既存のデータセンターインフラストラクチャを活用できることです。
EMFASYSが特に魅力的なのは、メモリバウンドワークロードを高価なGPU接続HBMからはるかに安価なDRAMに動的にオフロードし、同時にマイクロ秒レベルのアクセス遅延を維持できることです。EMFASYSのソフトウェアスタックには、遅延を隠し、システム上で実行されているLLMに透過的にメモリ移動をオーケストレートするインテリジェントキャッシングとロードバランシングメカニズムが含まれています。
AI業界への影響
これは、単に賢いハードウェアソリューションを超えて、AIインフラストラクチャが構築されスケールされる方法に哲学的な変化を表しています。生成的なAIが新奇さから必須に移行し、毎日数十億のユーザー照会が処理されるにつれて、これらのモデルを提供するコストは、多くの企業にとって持続不可能なものになりました。GPUは、コンピューティングの不足ではなく、メモリを待っているために、しばしば活用されていません。EMFASYSは、この不均衡を直接解決します。
Ethernet経由でアクセス可能なプール化されたファブリック接続メモリを提供することで、Enfabricaはデータセンター運用者に、継続的にGPUまたはHBMを購入するのではなく、モジュラーにメモリ容量を増やし、オフザシェルフのDRAMとインテリジェントなネットワーキングを使用して、全体的なフットプリントを削減し、AI推論の経済性を改善するための代替手段を提供します。
影響は、即時のコスト節約を超えています。このような分離アーキテクチャは、コンテキスト、履歴、およびエージェント状態が1つのセッションまたはサーバーを超えて永続化できるメモリとしてのサービスモデルへの道を開き、より賢くパーソナライズされたAIシステムへの道を開きます。また、メモリ制限が厳しくないAIクラウドのステージを設定し、ワークロードをラックまたはデータセンター全体に弾力的に分散できるようにします。
今後について
EnfabricaのEMFASYSは現在、選択された顧客とサンプリングされていますが、同社はこれらのパートナーが誰であるかについては明らかにしていません。ロイターの報道によると、大手AIクラウドプロバイダーはすでにこのシステムを試験しています。これにより、Enfabricaはコンポーネントサプライヤーではなく、次世代のAIインフラストラクチャの重要なエナブラーとして位置付けられます。
メモリをコンピューティングから切り離し、高速のコモディティEthernetネットワーク上で利用できるようにすることで、Enfabricaは、推論が妥協なくスケールできる、リソースがストランドされない、そして大規模言語モデルの展開の経済性が最終的に妥当になるような、AIアーキテクチャの新しい時代の基礎を築いています。
コンテキストに富んだマルチエージェントAIシステムで定義される世界では、メモリはもう二次的な役割ではありません。メモリは舞台です。Enfabricaは、AIのパフォーマンスを将来のために定義するのは、最も優れた舞台を構築する人であると賭けています。












