人工知能
ビデオ映像の感情をAIで操作する

ギリシャとイギリスの研究者は、ビデオ映像の中の人々の表情や感情を変更するための新しいディープラーニングアプローチを開発しました。これは、オリジナルのオーディオとの唇の動きの忠実性を維持しながら、以前の試みが達成できなかった方法で実現しています。

この記事の最後に埋め込まれている動画からの、俳優アル・パチーノの表情をNEDが微妙に変更した短いクリップ。個々の顔の表情を定義する高レベルのセマンティック概念とその関連する感情です。右側の「リファレンス駆動」方法は、ソースビデオの解釈された感情をビデオシーケンス全体に適用します。 ソース: https://www.youtube.com/watch?v=Li6W8pRDMJQ
この特定の分野は、デープフェイクされた感情の成長するカテゴリに分類されます。ここで、オリジナルのスピーカーのアイデンティティは維持されますが、表情やマイクロ表情は変更されます。このAI技術が成熟すると、映画やテレビ番組の制作で俳優の表情を微妙に変更する可能性が開けられます。また、感情を変更したビデオの新しいカテゴリも開けられます。
顔の変更
公人の顔の表情は、慎重にカリキュレーションされています。2016年、ヒラリー・クリントンの顔の表情は、メディアの厳しい注視の下にありました。彼女の選挙の可能性への潜在的な悪影響のために。顔の表情は、FBIの関心事でもあります。また、ジョブインタビューでは重要な指標です。遠い将来、ライブ「表情コントロール」フィルタの開発は、Zoomでのプレスクリーンに挑戦するジョブシーカーにとって望ましい開発となるでしょう。
2005年のイギリスの研究によると、顔の外見は投票の決定に影響を与えます。一方、2019年のワシントン・ポストの特集は、コンテキストのないビデオクリップの共有の使用を調査しました。これは、現在、フェイクニュースの支持者が実際に公人の行動、反応、または感情を変更することができる最も近いものです。
ニューラル表情操作への道
現在、顔の感情を操作する最先端の技術は、解離を扱う必要があるため、比較的初歩的な段階にあります。高いレベルの概念(例:悲しい、怒った、幸せ、笑った)を実際のビデオコンテンツから解離する必要があります。伝統的なデープフェイクアーキテクチャはこの解離をかなりうまく達成しているようですが、異なるアイデンティティ間で感情をミラーリングするには、2つのトレーニング顔セットが各アイデンティティに対して一致する表情を持っている必要があります。

ディープフェイクをトレーニングするために使用されるデータセットの典型的な顔画像の例。現在、人々の表情を操作する唯一の方法は、ディープフェイクニューラルネットワーク内でID固有の表情⇔表情のパスを作成することです。2017年のディープフェイクソフトウェアには、「笑顔」の固有のセマンティック理解がないため、2つの主体間の顔の幾何学的変化を単にマッピングして一致させます。
望ましいのは、主体B(例えば)が笑顔になる方法を認識し、主体Aの笑顔に相当する画像にマッピングする必要なく、「笑顔」スイッチをアーキテクチャに作成することです。
新しい論文は、ニューラル・エモーション・ディレクター:スピーチを保存した「野生」のビデオの顔の表情のセマンティック・コントロールというタイトルで、アテネ国立工科大学の電気・コンピューター工学部、ハラス財団のコンピューター科学研究所、イギリスのエクセター大学の工学・数学・物理科学部の研究者によって発表されました。
チームは、ニューラル・エモーション・ディレクター(NED)というフレームワークを開発しました。これには、3Dベースの感情変換ネットワーク、3Dベースの感情マニピュレーターが含まれています。
NEDは、受け取った表情パラメータのシーケンスをターゲットドメインに変換します。非対称データでトレーニングされるため、各アイデンティティに一致する顔の表情を持つデータセットでトレーニングする必要はありません。
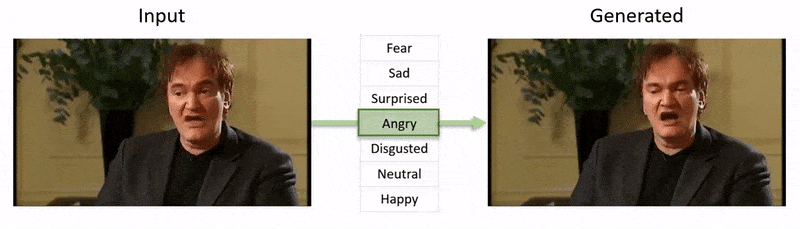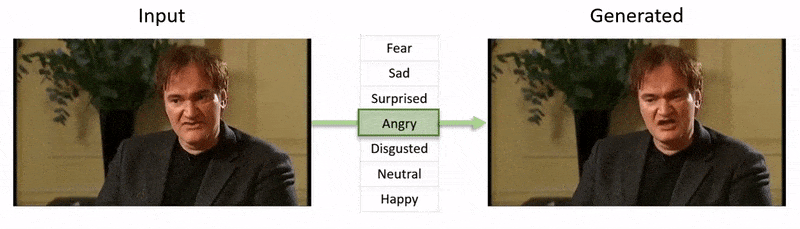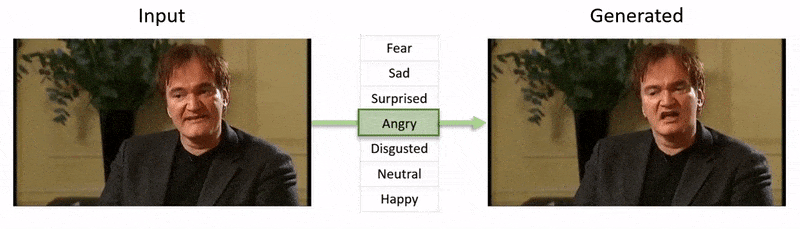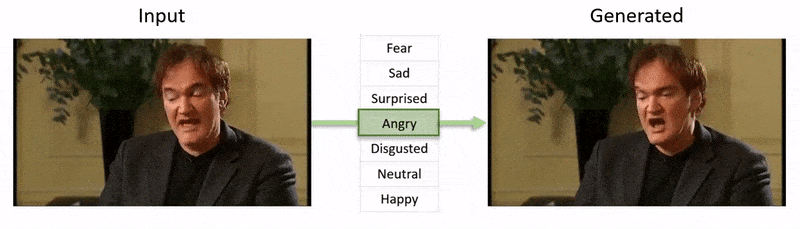
この記事の最後に表示される動画では、NEDがYouTubeデータセットのフッテージに明らかな感情状態を課す一連のテストが実行されます。
著者は、NEDがランダムで予測不可能な状況での俳優の「演出」を行うための最初のビデオベースの方法であると主張しています。コードは、NEDのプロジェクトページで利用可能です。
方法とアーキテクチャ
システムは、感情ラベルで注釈付けされた2つの大きなビデオデータセットでトレーニングされます。
出力は、伝統的な顔画像合成技術を使用して、ビデオで望ましい感情をレンダリングするビデオ顔レンダラーによって有効になります。これには、顔セグメンテーション、顔のランドマークの整列、ブレンドが含まれます。ここで、顔の領域のみが合成され、元のフッテージに重ねられます。

NEDのパイプラインのアーキテクチャ。 ソース: https://arxiv.org/pdf/2112.00585.pdf
初期段階では、システムは入力フレームの3D顔の回復と顔のランドマークの整列を取得して、表情を特定します。その後、これらの回復された表情パラメータは、3Dベースの感情マニピュレーターに渡され、セマンティックラベル(例:「幸せ」)またはリファレンスファイルを使用してスタイルベクトルが計算されます。
リファレンスファイルは、特定の認識された表情/感情を表すビデオクリップです。これは、ターゲットビデオ全体に適用され、元の表情と交換されます。

YouTubeビデオからサンプリングされたさまざまな俳優を特集した感情転送パイプラインの段階。
最終的に生成された3D顔の形状は、正規化された平均顔座標(NMFC)と目画像(上の画像の赤い点)と結合され、ニューラルレンダラーに渡され、最終的な操作を実行します。
結果
研究者は、NEDの有効性を評価するために、ユーザーと削除研究を含む包括的な研究を実施し、先行研究と比較して、ほとんどのカテゴリでNEDがこのサブセクターの現状を上回っていることを発見しました。

論文の著者は、この研究の後の実装と同様のツールが、主にテレビと映画産業で有用であると考えています。以下のように述べています:
「私たちの方法は、映画のポストプロダクション、ビデオゲーム、写真現実的な感情アバターやその他の有用なアプリケーションに、ニューラルレンダリング技術の新しい可能性の広がりを開けます。」
これはこの分野における初期の研究ですが、静止画像ではなくビデオで顔の再演を行う最初の試みの1つです。ビデオは本質的に非常に速い速度で連続して表示される静止画像ですが、時間的な考慮が、以前の感情転送の適用をより効果的には不了敵にします。この記事の最後に表示される動画や論文の例では、NEDの出力と他の比較可能な最近の方法の視覚的な比較が含まれています。

NEDのより詳細な比較と、さらに多くの例は、以下の完全なビデオで見つけることができます:
2021年12月3日 18:30 GMT+2 – 論文の1人の著者からの要望により、「リファレンスファイル」についての修正が行われました。これは、静止画像(実際にはビデオクリップ)であると誤って述べたためです。また、コンピューター科学研究所の名称についても修正しました。
2021年12月3日 20:50 GMT+2 – 上記の機関の名称についてさらに修正することを要望した論文の著者からの2回目のリクエスト。












