
AI 101
Mi az a túlillesztés?
Mi az a túlillesztés?
Amikor egy neurális hálózatot tanít, el kell kerülnie a túlillesztést. Túlfeszítés Ez a probléma a gépi tanulásban és a statisztikákban, ahol a modell túl jól megtanulja a betanítási adatkészlet mintáit, tökéletesen magyarázza a betanítási adatkészletet, de nem tudja általánosítani annak prediktív erejét más adatkészletekre.
Másképpen fogalmazva, egy túlillesztési modell esetén gyakran rendkívül nagy pontosságot mutat a betanítási adatkészleten, de alacsony pontosságot az összegyűjtött és a modellen átfutó adatokon a jövőben. Ez a túlillesztés gyors meghatározása, de nézzük meg részletesebben a túlillesztés fogalmát. Nézzük meg, hogyan fordul elő a túlillesztés, és hogyan kerülhető el.
Az „Illeszkedés” és az Alulfitting megértése
Hasznos egy pillantást vetni az alulillesztés fogalmára és „megfelelő” általában, amikor a túlszerelésről beszélünk. Amikor egy modellt betanítunk, olyan keretrendszert próbálunk kifejleszteni, amely képes előre jelezni az adatkészleten belüli elemek természetét vagy osztályát, az ezeket leíró jellemzők alapján. A modellnek képesnek kell lennie arra, hogy megmagyarázzon egy mintát egy adatkészleten belül, és ennek alapján megjósolja a jövőbeli adatpontok osztályait. Minél jobban magyarázza a modell az edzéskészlet jellemzői közötti kapcsolatot, annál „fittabb” a modellünk.
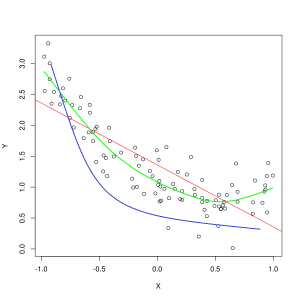
A kék vonal a nem megfelelő modell előrejelzéseit jelöli, míg a zöld vonal a jobban illeszkedő modellt. Fotó: Pep Roca a Wikimedia Commonsból, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Az a modell, amely rosszul magyarázza a képzési adatok jellemzői közötti kapcsolatot, és így nem tudja pontosan osztályozni a jövőbeli adatpéldákat, alulszerelés az edzés adatait. Ha egy alulillesztési modell előrejelzett kapcsolatát ábrázolná a jellemzők és címkék tényleges metszéspontjával, az előrejelzések eltérnének a céltól. Ha lenne egy grafikonunk, amelyen egy képzési halmaz valós értékei vannak felcímkézve, egy súlyosan alulillesztõ modell drasztikusan kihagyná a legtöbb adatpontot. Egy jobban illeszkedő modell átvághat egy utat az adatpontok közepén, és az egyes adatpontok csak kis mértékben térnek el az előre jelzett értékektől.
Alulillesztés gyakran előfordulhat, ha nem áll rendelkezésre elegendő adat egy pontos modell létrehozásához, vagy ha nemlineáris adatokkal próbálunk lineáris modellt tervezni. Több edzésadat vagy több funkció gyakran segít csökkenteni az alulfittságot.
Tehát miért ne hoznánk létre egy olyan modellt, amely tökéletesen megmagyarázza a képzési adatok minden pontját? Biztosan kívánatos a tökéletes pontosság? Egy olyan modell létrehozása, amely túl jól megtanulta a képzési adatok mintáit, az okozza a túlillesztést. A modellen futtatott betanítási adatkészlet és más, jövőbeli adatkészletek nem lesznek pontosan ugyanazok. Valószínűleg sok tekintetben nagyon hasonlóak lesznek, de alapvetően különböznek is egymástól. Ezért egy olyan modell megtervezése, amely tökéletesen magyarázza a betanítási adatkészletet, azt jelenti, hogy egy olyan elmélethez jutunk a jellemzők közötti kapcsolatról, amely nem általánosítható jól más adatkészletekre.
A túlillesztés megértése
Túlillesztésről akkor beszélünk, ha a modell túl jól megtanulja a betanítási adatkészlet részleteit, ami a modellnek megsínyli a külső adatokra vonatkozó előrejelzéseket. Ez akkor fordulhat elő, ha a modell nemcsak az adathalmaz jellemzőit tanulja meg, hanem véletlenszerű ingadozásokat, ill. zaj az adatkészleten belül, jelentőséget tulajdonítva ezeknek a véletlenszerű/nem fontos eseményeknek.
A túlillesztés nagyobb valószínűséggel fordul elő nemlineáris modellek használatakor, mivel ezek rugalmasabbak az adatszolgáltatások megtanulásakor. A nem paraméteres gépi tanulási algoritmusok gyakran különféle paraméterekkel és technikákkal rendelkeznek, amelyek segítségével korlátozható a modell adatérzékenysége, és ezáltal csökkenthető a túlillesztés. Mint például, döntési fa modellek nagyon érzékenyek a túlillesztésre, de a metszésnek nevezett technikával véletlenszerűen eltávolíthatók a modell által megtanult részletek.
Ha grafikonon ábrázolná a modell előrejelzéseit az X és Y tengelyeken, akkor egy előre-hátra cikázó előrejelzési vonalat kapna, ami azt tükrözi, hogy a modell túlságosan igyekezett az adatkészlet összes pontját beleilleszteni. annak magyarázata.
A túlillesztés szabályozása
Amikor egy modellt betanítunk, ideális esetben azt szeretnénk, hogy a modell ne hibázzon. Amikor a modell teljesítménye a képzési adathalmaz összes adatpontján történő helyes előrejelzések felé közelít, az illeszkedés egyre jobb. Egy jól illeszkedő modell túlillesztés nélkül képes megmagyarázni szinte az összes képzési adatkészletet.
Ahogy egy modell edz, teljesítménye idővel javul. A modell hibaaránya csökkenni fog a képzési idő múlásával, de csak egy bizonyos pontig csökken. Az a pont, ahol a modell teljesítménye a tesztkészleten ismét emelkedni kezd, általában az a pont, ahol túlillesztés történik. Annak érdekében, hogy a modellhez a legjobb illeszkedést kapjuk, le szeretnénk állítani a modell képzését a képzési halmaz legalacsonyabb veszteségének pontján, mielőtt a hiba ismét növekedni kezd. Az optimális megállási pontot úgy határozhatjuk meg, hogy a modell teljesítményét ábrázoljuk a teljes képzési idő alatt, és akkor állítjuk le az edzést, amikor a veszteség a legkisebb. Ezzel a túlillesztés-ellenőrzési módszerrel azonban az egyik kockázat az, hogy a betanítás végpontjának a tesztteljesítmény alapján történő megadása azt jelenti, hogy a tesztadatok valamelyest bekerülnek a betanítási eljárásba, és elveszítik tisztán „érintetlen” adat státuszát.
A túlszerelés leküzdésére több különböző módszer is létezik. A túlillesztés csökkentésének egyik módja az újramintavételezési taktika alkalmazása, amely a modell pontosságának becslésével működik. Használhatja a érvényesítés adatkészletet a tesztkészlet mellett, és ábrázolja a betanítási pontosságot az érvényesítési halmazhoz viszonyítva a tesztadatkészlet helyett. Ezzel a tesztadatkészlet nem látható. Egy népszerű újramintavételi módszer a K-redős keresztellenőrzés. Ez a technika lehetővé teszi, hogy az adatokat részhalmazokra ossza fel, amelyekre a modellt betanították, majd a modell teljesítményét elemzik az alhalmazokon, hogy megbecsüljék, hogyan fog teljesíteni a modell külső adatokon.
A keresztellenőrzés alkalmazása az egyik legjobb módja a modell pontosságának becslésének a nem látott adatokon, és az érvényesítési adatkészlettel kombinálva a túlillesztés gyakran minimálisra csökkenthető.










