
AI 101
Mi az a dimenziócsökkentés?
Mi az a dimenziócsökkentés?
Dimenziócsökkentés egy folyamat, amelyet az adatkészlet dimenziójának csökkentésére használnak, sok jellemzőt vesz fel és kevesebb jellemzőként ábrázol. Például a dimenziócsökkentéssel egy húsz jellemzőből álló adatkészletet csak néhány jellemzőre lehetne redukálni. A dimenziócsökkentést általában használják felügyelet nélküli tanulás feladatokat, hogy automatikusan hozzon létre osztályokat számos szolgáltatásból. A jobb megértés érdekében miért és hogyan alkalmazzák a dimenziócsökkentést, áttekintjük a nagy dimenziós adatokkal kapcsolatos problémákat és a dimenziócsökkentés legnépszerűbb módszereit.
A több méret túlszereléshez vezet
A dimenzionalitás az adatkészleten belüli jellemzők/oszlopok számát jelenti.
Gyakran feltételezik, hogy a gépi tanulásban több funkció jobb, mivel pontosabb modellt hoz létre. A több funkció azonban nem feltétlenül jelent jobb modellt.
Az adatkészlet jellemzői nagymértékben változhatnak abból a szempontból, hogy mennyire hasznosak a modell számára, sok jellemző pedig csekély jelentőséggel bír. Ezenkívül minél több szolgáltatást tartalmaz az adatkészlet, annál több mintára van szükség annak biztosításához, hogy a jellemzők különböző kombinációi jól megjelenjenek az adatokon belül. Ezért a minták száma a jellemzők számával arányosan növekszik. Több minta és több funkció azt jelenti, hogy a modellnek összetettebbnek kell lennie, és ahogy a modellek bonyolultabbá válnak, érzékenyebbé válnak a túlillesztésre. A modell túl jól megtanulja a betanítási adatok mintáit, és nem tud általánosítani a mintaadatokon kívülre.
Az adatkészlet dimenziójának csökkentése számos előnnyel jár. Mint említettük, az egyszerűbb modellek kevésbé hajlamosak a túlillesztésre, mivel a modellnek kevesebb feltételezést kell tennie a funkciók egymáshoz való viszonyát illetően. Ezenkívül a kevesebb méret azt jelenti, hogy kevesebb számítási teljesítményre van szükség az algoritmusok betanításához. Hasonlóképpen kevesebb tárhelyre van szükség egy kisebb dimenziójú adatkészlethez. Az adatkészlet dimenziójának csökkentése olyan algoritmusok használatát is lehetővé teheti, amelyek nem megfelelőek a sok szolgáltatással rendelkező adatkészletekhez.
Gyakori dimenziócsökkentési módszerek
A dimenziócsökkentés történhet jellemző kiválasztásával vagy jellemző tervezéssel. A funkcióválasztás az, ahol a mérnök azonosítja az adatkészlet legrelevánsabb jellemzőit, miközben jellemző tervezés az új funkciók létrehozásának folyamata más jellemzők kombinálásával vagy átalakításával.
A funkciók kiválasztása és tervezése történhet programozottan vagy manuálisan. Jellemzők manuális kiválasztása és tervezése során jellemző az adatok vizualizálása a szolgáltatások és osztályok közötti összefüggések felfedezésére. A dimenziócsökkentés ilyen módon történő végrehajtása meglehetősen időigényes lehet, ezért a dimenziócsökkentés legáltalánosabb módjai közé tartozik a könyvtárakban elérhető algoritmusok használata, például a Scikit-learn for Python. Ezek a gyakori dimenziócsökkentő algoritmusok a következőket foglalják magukban: Főkomponens-elemzés (PCA), Singular Value Decomposition (SVD) és Lineáris diszkriminanciaelemzés (LDA).
A nem felügyelt tanulási feladatok dimenziócsökkentéséhez használt algoritmusok általában a PCA és az SVD, míg a felügyelt tanulási dimenziócsökkentéshez használt algoritmusok általában az LDA és a PCA. A felügyelt tanulási modellek esetében az újonnan generált funkciók csak bekerülnek a gépi tanulási osztályozóba. Vegye figyelembe, hogy az itt leírt felhasználások csak általános használati esetek, és nem az egyetlen feltételek, amelyek mellett ezek a technikák használhatók. A fent leírt dimenziócsökkentő algoritmusok egyszerűen statisztikai módszerek, és a gépi tanulási modelleken kívül használatosak.
Főkomponens analízis

Fotó: Mátrix a főbb komponensekkel
Fő komponens elemzés (PCA) egy statisztikai módszer, amely egy adathalmaz jellemzőit/tulajdonságait elemzi, és összefoglalja a leginkább befolyásoló jellemzőket. Az adatkészlet jellemzőit olyan reprezentációkba egyesítik, amelyek megtartják az adatok legtöbb jellemzőjét, de kevesebb dimenzióban vannak elosztva. Ezt úgy is felfoghatja, hogy az adatokat egy magasabb dimenziós ábrázolásból csak néhány dimenziós reprezentációra „lenyomja”.
Példaként arra a helyzetre, amikor a PCA hasznos lehet, gondoljon a bor leírására. Noha lehetséges a bor leírása számos rendkívül specifikus jellemzővel, például CO2-szinttel, levegőztetési szintekkel stb., az ilyen jellemzők viszonylag haszontalanok lehetnek egy adott bortípus azonosításakor. Ehelyett körültekintőbb lenne a típust olyan általánosabb jellemzők alapján azonosítani, mint az íz, a szín és az életkor. A PCA segítségével specifikusabb funkciókat lehet kombinálni, és olyan funkciókat lehet létrehozni, amelyek általánosabbak, hasznosabbak és kevésbé valószínű, hogy túlillesztést okoznak.
A PCA-t úgy hajtják végre, hogy meghatározzák, hogy a bemeneti jellemzők hogyan térnek el az átlagostól egymáshoz képest, és meghatározzák, hogy vannak-e összefüggések a jellemzők között. Ennek érdekében egy kovariáns mátrixot hozunk létre, amely az adatkészlet jellemzőinek lehetséges párjaira vonatkozó kovariancia mátrixot hoz létre. Ez a változók közötti összefüggések meghatározására szolgál, ahol a negatív kovariancia inverz, a pozitív korreláció pedig a pozitív korrelációt jelzi.
Az adathalmaz fő (leghatásosabb) komponensei a kezdeti változók lineáris kombinációinak létrehozásával jönnek létre, ami lineáris algebrai fogalmak, ún. sajátértékek és sajátvektorok. A kombinációk úgy jönnek létre, hogy a fő összetevők ne legyenek korrelációban egymással. A kezdeti változókban található információk nagy része az első néhány főkomponensbe tömörül, ami azt jelenti, hogy új jellemzők (a főkomponensek) jöttek létre, amelyek az eredeti adatkészletből származó információkat egy kisebb dimenziós térben tartalmazzák.
Szinguláris érték felbontás
Fotó: Cmglee – Saját munka, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
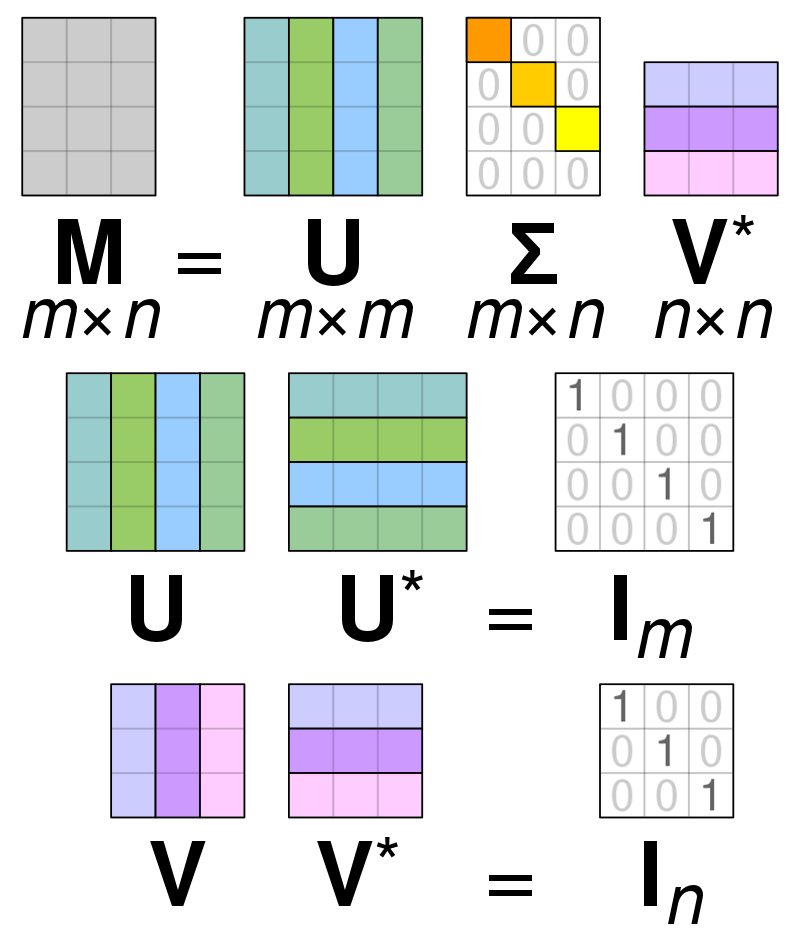
Singular Value Dekompozíció (SVD) is a mátrixon belüli értékek egyszerűsítésére szolgál, csökkenti a mátrixot alkotórészeire, és megkönnyíti a számításokat ezzel a mátrixszal. Az SVD használható valós értékű és összetett mátrixokhoz is, de ennek a magyarázatnak a céljaira megvizsgálja, hogyan lehet valós értékekből álló mátrixot felbontani.
Tegyük fel, hogy van egy valós értékű adatokból álló mátrixunk, és a célunk az oszlopok/jellemzők számának csökkentése a mátrixon belül, hasonlóan a PCA céljához. A PCA-hoz hasonlóan az SVD is tömöríti a mátrix dimenzióit, miközben a lehető legtöbbet megőrzi a mátrix variabilitását. Ha az A mátrixot akarjuk kezelni, akkor az A mátrixot három másik U, D és V mátrixként ábrázolhatjuk. Az A mátrix az eredeti x * y elemekből, míg az U mátrix X * X elemekből áll (ez ortogonális mátrix). A V mátrix egy másik ortogonális mátrix, amely y * y elemeket tartalmaz. A D mátrix az x * y elemeket tartalmazza, és egy átlós mátrix.
Az A mátrix értékeinek felbontásához az eredeti szinguláris mátrixértékeket át kell alakítanunk egy új mátrixban talált átlóértékekre. Ha ortogonális mátrixokkal dolgozunk, azok tulajdonságai nem változnak, ha más számokkal megszorozzuk. Ezért ennek a tulajdonságnak a kihasználásával közelíthetjük az A mátrixot. Ha az ortogonális mátrixokat megszorozzuk az V mátrix transzponálásával, az eredmény egy ekvivalens mátrix az eredeti A-val.
Amikor az a mátrixot U, D és V mátrixokra bontjuk, ezek tartalmazzák az A mátrixban található adatokat. Azonban a mátrixok bal szélső oszlopaiban az adatok többsége található. Csak ezt az első néhány oszlopot vehetjük át, és megkaphatjuk az A mátrix reprezentációját, amely sokkal kevesebb dimenzióval rendelkezik, és a legtöbb adat az A-n belül van.
Lineáris diszkriminancia analízis

Balra: Mátrix az LDA előtt, jobbra: Az LDA utáni tengely, most szétválasztható
Lineáris diszkriminancia analízis (LDA) olyan folyamat, amely többdimenziós gráfból vesz adatokat és újravetíti egy lineáris gráfra. Ezt úgy képzelheti el, ha egy kétdimenziós gráfra gondol, amely két különböző osztályba tartozó adatpontokkal van feltöltve. Tételezzük fel, hogy a pontok úgy vannak szétszórva, hogy nem lehet olyan vonalat húzni, amely szépen elválasztja a két különböző osztályt. Ennek a helyzetnek a kezelése érdekében a 2D grafikonon található pontokat le lehet redukálni egy 1D gráfra (egy vonalra). Ezen a vonalon az összes adatpont el van osztva, és remélhetőleg két részre osztható, amelyek az adatok lehető legjobb elkülönítését jelentik.
Az LDA végrehajtása során két elsődleges cél van. Az első cél az osztályok varianciájának minimalizálása, míg a második cél a két osztály átlagai közötti távolság maximalizálása. Ezeket a célokat egy új tengely létrehozásával érik el, amely a 2D-s grafikonon fog megjelenni. Az újonnan létrehozott tengely a két osztály szétválasztására szolgál a korábban leírt célok alapján. A tengely létrehozása után a 2D grafikonon talált pontok a tengely mentén helyezkednek el.
Három lépés szükséges ahhoz, hogy az eredeti pontokat az új tengely mentén új pozícióba helyezzük. Első lépésben az egyes osztályok közötti távolság átlagát (az osztályok közötti varianciát) használjuk az osztályok elválaszthatóságának kiszámításához. A második lépésben a különböző osztályokon belüli variancia kiszámítása történik, a minta és a kérdéses osztály átlaga közötti távolság meghatározásával. Az utolsó lépésben létrejön az alsó dimenziós tér, amely maximalizálja az osztályok közötti eltérést.
Az LDA technika akkor éri el a legjobb eredményeket, ha a célosztályok eszközei messze vannak egymástól. Az LDA nem tudja hatékonyan elválasztani az osztályokat lineáris tengellyel, ha az eloszlások átlagai átfedik egymást.










