
Mesterséges Intelligencia
Andrew Ng bírálja a túlillesztés kultúráját a gépi tanulásban
Andrew Ng, a gépi tanulás egyik legbefolyásosabb hangadója az elmúlt évtizedben, jelenleg aggodalmának ad hangot amiatt, hogy az ágazat mennyire helyezi előtérbe a modellarchitektúra újításait az adatokkal szemben – és konkrétan, milyen mértékben teszi lehetővé a „túlillesztett” eredményeket. általánosított megoldásként vagy előrelépésként ábrázolható.
Ezek a jelenlegi gépi tanulási kultúra elsöprő kritikái, amelyek az egyik legfelsőbb tekintélytől erednek, és hatással vannak a bizalomra egy olyan szektorban, amelyet egy harmadik összeomlás az AI fejlesztésébe vetett üzleti bizalom hatvan éven belül.
Ng, a Stanford Egyetem professzora a deeplearning.ai egyik alapítója is, és márciusban közzétett egy hírnök a szervezet oldalán, amely lepárolta a legutóbbi beszéd néhány alapvető ajánlásból:
Először is, hogy a kutatói közösség ne panaszkodjon arról, hogy az adattisztítás jelenti a gépi tanulás kihívásainak 80%-át, és folytassa a robusztus MLOps módszertanok és gyakorlatok kidolgozását.
Másodszor, hogy el kell távolodnia a „könnyű nyereményektől”, amelyeket az adatok túlillesztésével lehet elérni egy gépi tanulási modellben, hogy jól teljesítsen ezen a modellen, de ne tudjon általánosítani vagy széles körben telepíthető modellt készíteni.
Az adatarchitektúra és -felügyelet kihívásának elfogadása
„Az én nézetem” – írta Ng. "az, hogy ha munkánk 80 százaléka az adatok előkészítése, akkor az adatminőség biztosítása egy gépi tanulási csapat fontos munkája."
Majd így folytatta:
„Ahelyett, hogy a véletlenre számítanánk a mérnökökre egy adathalmaz tökéletesítésének legjobb módját, remélem, ki tudunk fejleszteni MLOps-eszközöket, amelyek segítenek megismételhetőbbé és szisztematikusabbá tenni az AI-rendszerek építését, beleértve a kiváló minőségű adatkészletek készítését.
„Az MLOps egy kialakulóban lévő terület, és a különböző emberek eltérően határozzák meg. De úgy gondolom, hogy az MLOps csapatok és eszközök legfontosabb szervezőelve az, hogy biztosítsák a következetes és jó minőségű adatáramlást a projekt minden szakaszában. Ezzel sok projekt gördülékenyebben megy végbe.
Beszéd a Zoomon egy élő közvetítésben Kérdések és válaszok április végén az Ng foglalkozott a radiológiai gépi tanulási elemző rendszerek alkalmazhatósági hiányosságaival:
„Kiderült, hogy amikor adatokat gyűjtünk a Stanford Kórházból, akkor ugyanabból a kórházból oktatunk és tesztelünk, sőt, publikálhatunk olyan dokumentumokat, amelyek azt mutatják, hogy [az algoritmusok] összehasonlíthatók a humán radiológusokéval bizonyos állapotok észlelésében.
„…[Amikor] elviszi ugyanazt a modellt, ugyanazt a mesterséges intelligencia rendszert egy régebbi kórházba az utcán, egy régebbi géppel, és a technikus egy kicsit más képalkotó protokollt használ, akkor az adatok elsodródnak, és az AI rendszer teljesítményét rontják. jelentősen leromlik. Ezzel szemben bármelyik humán radiológus elsétálhat az utcán a régebbi kórházba, és jól járhat.”
Az alulspecifikáció nem megoldás
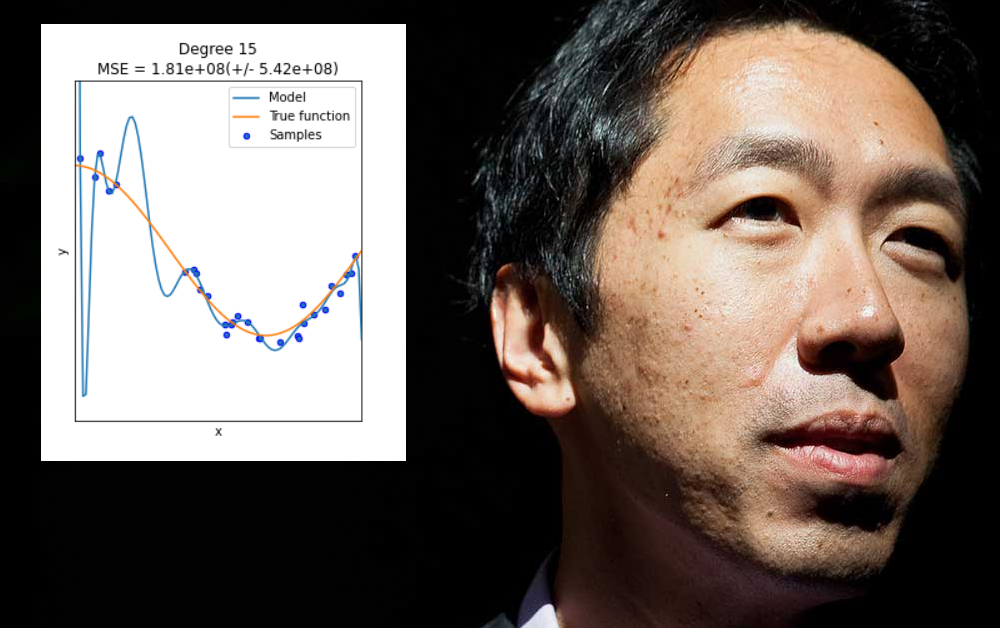
Túlillesztésről akkor beszélünk, ha egy gépi tanulási modellt kifejezetten úgy terveztek, hogy alkalmazkodjon egy adott adatkészlet excentricitásaihoz (vagy az adatok formázási módjához). Ez magában foglalhatja például olyan súlyok megadását, amelyek jó eredményeket hoznak az adott adatkészletből, de nem „általánosítanak” más adatokat.
Sok esetben az ilyen paramétereket a betanítási halmaz „nem adat” szempontjai alapján határozzák meg, mint például az összegyűjtött információ konkrét felbontása vagy más olyan sajátosságok, amelyek nem garantáltan ismétlődnek más későbbi adatkészletekben.
Bár jó lenne, a túlillesztés nem olyan probléma, amelyet az adatarchitektúra vagy a modelltervezés hatókörének vagy rugalmasságának vak kiterjesztésével lehet megoldani, amikor valójában széles körben alkalmazható és kiemelkedően fontos funkciókra van szükség, amelyek jól teljesítenek az adatok széles skáláján. környezetek – kényesebb kihívás.
Általánosságban elmondható, hogy az ilyen típusú „alulspecifikáció” csak azokhoz a problémákhoz vezet, amelyeket Ng az utóbbi időben felvázolt, amikor a gépi tanulási modell nem látható adatokon megbukik. A különbség ebben az esetben az, hogy a modell nem azért hibásodik meg, mert az adatok vagy adatformázás eltér a túlillesztett eredeti tanítókészlettől, hanem azért, mert a modell túlságosan rugalmas, mintsem túl törékeny.
2020 végén a papír Az alulspecifikáció kihívások elé állítja a hitelességet a modern gépi tanulásban heves kritikát fogalmazott meg ezzel a gyakorlattal szemben, és nem kevesebb, mint negyven gépi tanulási kutató és tudós nevét viselte a Google-tól és az MIT-től, egyéb intézmények mellett.
A cikk bírálja a „shortcut learning”-et, és megfigyeli, hogy az aluldefiniált modellek hogyan tudnak felszállni a vad érintőknél a véletlenszerű magpont alapján, ahol a modellképzés elkezdődik. A hozzászólók megfigyelik:
„Láttuk, hogy az alulspecifikáció mindenütt jelen van a gyakorlati gépi tanulási folyamatokban számos területen. Valójában az alulspecifikációnak köszönhetően a döntések lényeges szempontjait tetszőleges választások határozzák meg, például a paraméterek inicializálásához használt véletlen mag.
A kultúra megváltoztatásának gazdasági következményei
Tudományos minősítése ellenére Ng nem légies akadémikus, hanem mély és magas szintű iparági tapasztalattal rendelkezik a Google Brain és a Coursera társalapítójaként, a Baidu Big Data és AI korábbi vezető tudósaként, valamint alapító a Landing AI, amely 175 millió USD-t adminisztrál az ágazatban működő új vállalkozások számára.
Amikor azt mondja: „Az egész mesterséges intelligencia, nem csak az egészségügy, a koncepció és a termelés közötti szakadékkal rendelkezik”, ez egy ébresztő hívás egy olyan szektor számára, amelyet a jelenlegi felhajtás és foltos történelem egyre inkább úgy jellemez. bizonytalan hosszú távú üzleti befektetés, szorongat definíciós és terjedelmi problémákkal.
Mindazonáltal a szabadalmaztatott gépi tanulási rendszerek, amelyek jól működnek in situ, és más környezetekben meghibásodnak, azt a fajta piacbefoglalást jelentik, amely megjutalmazhatja az iparági befektetéseket. A „túlszerelési probléma” foglalkozási veszélyekkel összefüggésben való bemutatása téves módot kínál a bevételt vállalati befektetés a nyílt forráskódú kutatásba, és olyan (hatékonyan) szabadalmaztatott rendszerek előállítására, ahol a versenytársak replikációja lehetséges, de problémás.
Az, hogy ez a megközelítés hosszú távon működne-e vagy sem, attól függ, hogy a gépi tanulás terén milyen mértékben van szükség a valódi áttörésekhez. egyre magasabb befektetési szintek, és hogy az összes produktív kezdeményezés bizonyos mértékig elkerülhetetlenül a FAANG-ra költözik-e, a tárhelyszolgáltatáshoz és a működéshez szükséges kolosszális erőforrások miatt.















