Inteligencia artificial
Zero123++: Un Modelo de Difusión de Imágenes Únicas a Imágenes de Vistas Múltiples Coherentes

En los últimos años, hemos presenciado un avance rápido en el rendimiento, la eficiencia y las capacidades generativas de los nuevos modelos de inteligencia artificial (IA) que aprovechan conjuntos de datos extensos y prácticas de generación de difusión en 2D. Hoy en día, los modelos de IA generativos son extremadamente capaces de generar diferentes formas de contenido de medios en 2D y, hasta cierto punto, en 3D, incluyendo texto, imágenes, videos, GIF y más.
En este artículo, hablaremos sobre el marco de trabajo Zero123++, un modelo de IA generativo condicionado por imágenes que tiene como objetivo generar imágenes de vistas múltiples coherentes en 3D a partir de una sola vista de entrada. Para maximizar la ventaja obtenida de los modelos generativos preentrenados, el marco de trabajo Zero123++ implementa numerosos esquemas de entrenamiento y acondicionamiento para minimizar el esfuerzo necesario para ajustar los modelos de difusión de imágenes fuera de la caja. Analizaremos la arquitectura, el funcionamiento y los resultados del marco de trabajo Zero123++, y evaluaremos sus capacidades para generar imágenes de vistas múltiples coherentes de alta calidad a partir de una sola imagen. Así que comencemos.
Zero123 y Zero123++: Una Introducción
El marco de trabajo Zero123++ es un modelo de IA generativo condicionado por imágenes que tiene como objetivo generar imágenes de vistas múltiples coherentes en 3D a partir de una sola vista de entrada. El marco de trabajo Zero123++ es una continuación del marco de trabajo Zero123 o Zero-1-a-3, que aprovecha la técnica de síntesis de imágenes de vistas nuevas en cero disparos para pionear la conversión de imágenes únicas a 3D de código abierto. Aunque el marco de trabajo Zero123++ ofrece un rendimiento prometedor, las imágenes generadas por el marco de trabajo tienen inconsistencias geométricas visibles, y es la principal razón por la que todavía existe una brecha entre las escenas en 3D y las imágenes de vistas múltiples.
El marco de trabajo Zero-1-a-3 sirve como base para varios otros marcos de trabajo, incluyendo SyncDreamer, One-2-3-45, Consistent123 y más, que agregan capas adicionales al marco de trabajo Zero123 para obtener resultados más coherentes al generar imágenes en 3D. Otros marcos de trabajo como ProlificDreamer, DreamFusion, DreamGaussian y más siguen un enfoque basado en la optimización para obtener imágenes en 3D destilando una imagen en 3D de varios modelos inconsistentes. Aunque estas técnicas son efectivas y generan imágenes en 3D satisfactorias, los resultados podrían mejorarse con la implementación de un modelo de difusión base capaz de generar imágenes de vistas múltiples de manera coherente. En consecuencia, el marco de trabajo Zero123++ toma el Zero-1-a-3 y ajusta un nuevo modelo de difusión base de vistas múltiples a partir de la difusión estable.
En el marco de trabajo Zero-1-a-3, cada vista nueva se genera de forma independiente, y este enfoque conduce a inconsistencias entre las vistas generadas, ya que los modelos de difusión tienen una naturaleza de muestreo. Para abordar este problema, el marco de trabajo Zero123++ adopta un enfoque de diseño de mosaico, con el objeto rodeado por seis vistas en una sola imagen, y garantiza el modelado correcto de la distribución conjunta de las imágenes de vistas múltiples de un objeto.
Otro desafío importante que enfrentan los desarrolladores que trabajan en el marco de trabajo Zero-1-a-3 es que subutiliza las capacidades ofrecidas por la difusión estable que, en última instancia, conduce a la ineficiencia y a costos adicionales. Hay dos razones principales por las que el marco de trabajo Zero-1-a-3 no puede aprovechar al máximo las capacidades ofrecidas por la difusión estable
- Cuando se entrena con condiciones de imagen, el marco de trabajo Zero-1-a-3 no incorpora mecanismos de acondicionamiento local o global ofrecidos por la difusión estable de manera efectiva.
- Durante el entrenamiento, el marco de trabajo Zero-1-a-3 utiliza una resolución reducida, un enfoque en el que la resolución de salida se reduce por debajo de la resolución de entrenamiento, lo que puede reducir la calidad de la generación de imágenes para los modelos de difusión estable.
Para abordar estos problemas, el marco de trabajo Zero123++ implementa una variedad de técnicas de acondicionamiento que maximizan la utilización de los recursos ofrecidos por la difusión estable y mantienen la calidad de la generación de imágenes para los modelos de difusión estable.
Mejorando la Coherencia y el Acondicionamiento
En un intento por mejorar el acondicionamiento de imágenes y la coherencia de las imágenes de vistas múltiples, el marco de trabajo Zero123++ implementó diferentes técnicas, con el objetivo principal de reutilizar técnicas anteriores obtenidas del modelo de difusión estable preentrenado.
Generación de Vistas Múltiples
La calidad indispensable de generar imágenes de vistas múltiples coherentes radica en modelar la distribución conjunta de múltiples imágenes de manera correcta. En el marco de trabajo Zero-1-a-3, la correlación entre las imágenes de vistas múltiples se ignora porque, para cada imagen, el marco de trabajo modela la distribución marginal condicional de forma independiente y por separado. Sin embargo, en el marco de trabajo Zero123++, los desarrolladores han optado por un enfoque de diseño de mosaico que combina 6 imágenes en una sola imagen para la generación coherente de vistas múltiples, y el proceso se demuestra en la siguiente imagen.
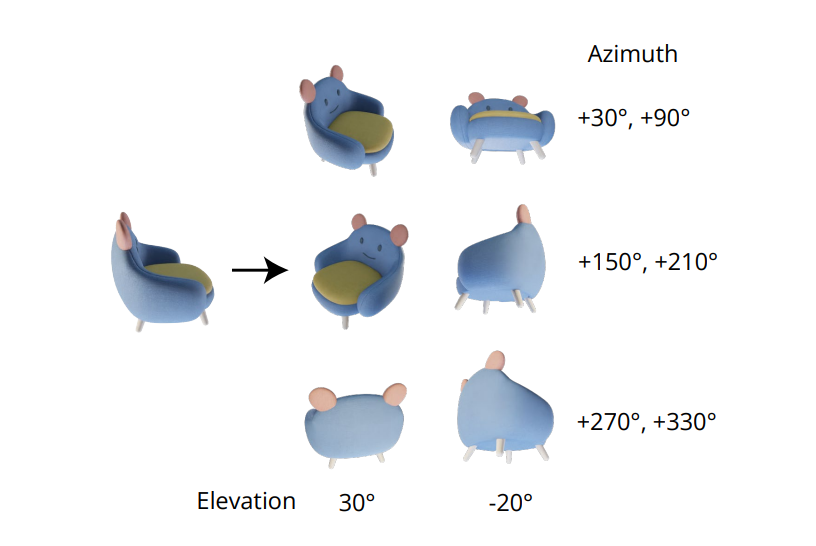

Además, se ha notado que las orientaciones de los objetos tienden a desambiguarse cuando se entrena el modelo en poses de cámara, y para prevenir esta desambiguación, el marco de trabajo Zero-1-a-3 se entrena en poses de cámara con ángulos de elevación y azimut relativo a la entrada. Para implementar este enfoque, es necesario conocer el ángulo de elevación de la vista de la entrada que se utiliza para determinar la pose relativa entre las vistas de entrada nuevas. En un intento por conocer este ángulo de elevación, los marcos de trabajo a menudo agregan un módulo de estimación de elevación, y este enfoque a menudo conlleva errores adicionales en la canalización.
Programa de Ruido
La programación lineal escalada, la programación de ruido original para la difusión estable, se centra principalmente en los detalles locales, pero como se puede ver en la siguiente imagen, tiene muy pocos pasos con una relación señaligena (SNR) más baja.


Estos pasos de baja relación señaligena ocurren temprano durante la etapa de desenoise, una etapa crucial para determinar la estructura de baja frecuencia global. Reducir el número de pasos durante la etapa de desenoise, ya sea durante la interferencia o el entrenamiento, a menudo resulta en una mayor variación estructural. Aunque este diseño es ideal para la generación de imágenes individuales, limita la capacidad del marco de trabajo para garantizar la coherencia global entre las diferentes vistas. Para superar este obstáculo, el marco de trabajo Zero123++ ajusta un modelo LoRA en el marco de trabajo de predicción 2 v de la difusión estable para realizar una tarea de juguete, y los resultados se demuestran a continuación.

Con la programación lineal escalada, el modelo LoRA no se sobreajusta, sino que solo blanquea ligeramente la imagen. Por el contrario, cuando se trabaja con la programación lineal, el marco de trabajo LoRA genera una imagen en blanco con éxito, independientemente de la entrada de la promoción, lo que indica el impacto de la programación de ruido en la capacidad del marco de trabajo para adaptarse a nuevos requisitos de manera global.
Atención de Referencia Escalada para Condiciones Locales
La entrada de vista única o las imágenes de acondicionamiento en el marco de trabajo Zero-1-a-3 se concatenan con las entradas ruidosas en la dimensión de características para ser ruidosas para el acondicionamiento de imágenes.
Esta concatenación conduce a una correspondencia espacial de píxeles incorrecta entre la imagen objetivo y la entrada. Para proporcionar una entrada de acondicionamiento local adecuada, el marco de trabajo Zero123++ utiliza una atención de referencia escalada, un enfoque en el que se ejecuta un modelo de red neuronal de denoising UNet en una imagen de referencia adicional, seguido de la adición de matrices de valor y autoatención clave de la imagen de referencia a las capas de atención respectivas cuando la entrada del modelo se desenoise, y se demuestra en la siguiente figura.

El enfoque de atención de referencia es capaz de guiar el modelo de difusión para generar imágenes que comparten texturas similares con la imagen de referencia y contenido semántico sin ningún ajuste. Con ajuste, el enfoque de atención de referencia ofrece resultados superiores con el latente escalado.

Acondicionamiento Global: FlexDiffuse
En el enfoque original de difusión estable, las incrustaciones de texto son la única fuente de incrustaciones globales, y el enfoque utiliza el marco de trabajo CLIP como codificador de texto para realizar exámenes cruzados entre las incrustaciones de texto y los latentes del modelo. En consecuencia, los desarrolladores pueden utilizar la alineación entre los espacios de texto y las imágenes CLIP resultantes para utilizarla para el acondicionamiento de imágenes globales.
El marco de trabajo Zero123++ propone utilizar una variante trainable de la guía lineal para incorporar el acondicionamiento de imágenes globales en el marco de trabajo con un ajuste mínimo necesario, y los resultados se demuestran en la siguiente imagen. Como se puede ver, sin la presencia de un acondicionamiento de imágenes globales, la calidad del contenido generado por el marco de trabajo es satisfactoria para las regiones visibles que corresponden a la imagen de entrada. Sin embargo, la calidad de la imagen generada por el marco de trabajo para las regiones no vistas sufre una deterioración significativa, lo que se debe principalmente a la incapacidad del modelo para inferir la semántica global del objeto.

Arquitectura del Modelo
El marco de trabajo Zero123++ se entrena con el modelo 2v de la difusión estable como base utilizando los diferentes enfoques y técnicas mencionadas en el artículo. El marco de trabajo Zero123++ se preentrena en el conjunto de datos Objaverse que se renderiza con iluminación HDRI aleatoria. El marco de trabajo también adopta el enfoque de programación de entrenamiento por fases utilizado en el marco de trabajo de variaciones de imágenes de difusión estable en un intento por minimizar aún más la cantidad de ajuste necesario y preservar tanto como sea posible el conocimiento previo de la difusión estable.
El funcionamiento o la arquitectura del marco de trabajo Zero123++ se puede dividir aún más en pasos o fases secuenciales. La primera fase presencia el marco de trabajo ajustando las matrices KV de las capas de autoatención y las capas de atención cruzada de la difusión estable con AdamW como su optimizador, 1000 pasos de calentamiento y la programación de aprendizaje de coseno que maximiza en 7×10-5. En la segunda fase, el marco de trabajo emplea una tasa de aprendizaje constante muy conservadora con 2000 conjuntos de calentamiento y emplea el enfoque de minimización de la relación señaligena para maximizar la eficiencia durante el entrenamiento.
Zero123++: Resultados y Comparación de Rendimiento
Rendimiento Cualitativo
Para evaluar el rendimiento del marco de trabajo Zero123++ en función de la calidad generada, se compara con SyncDreamer y Zero-1-a-3-XL, dos de los marcos de trabajo de estado del arte más finos para la generación de contenido. Los marcos de trabajo se comparan con cuatro imágenes de entrada con diferentes alcances. La primera imagen es un gato de juguete eléctrico, tomada directamente del conjunto de datos Objaverse, y cuenta con una gran incertidumbre en la parte posterior del objeto. La segunda es la imagen de un extintor de incendios, y la tercera es la imagen de un perro sentado en un cohete, generada por el modelo SDXL. La última imagen es una ilustración de anime. Los pasos de elevación necesarios para los marcos de trabajo se logran utilizando el método de estimación de elevación del marco de trabajo One-2-3-4-5, y la eliminación de fondo se logra utilizando el marco de trabajo SAM. Como se puede ver, el marco de trabajo Zero123++ genera imágenes de vistas múltiples de alta calidad de manera coherente y es capaz de generalizar a ilustraciones de 2D fuera del dominio y a imágenes generadas por IA de manera igualmente efectiva.


Análisis Cuantitativo
Para comparar cuantitativamente el marco de trabajo Zero123++ con los marcos de trabajo de estado del arte Zero-1-a-3 y Zero-1-a-3-XL, los desarrolladores evalúan la puntuación de similitud de parches de imágenes percibidas aprendidas (LPIPS) de estos modelos en el conjunto de datos de validación, un subconjunto del conjunto de datos Objaverse. Para evaluar el rendimiento del modelo en la generación de imágenes de vistas múltiples, los desarrolladores combinan las imágenes de referencia de verdad y 6 imágenes generadas respectivamente, y luego calculan la puntuación LPIPS. Los resultados se demuestran a continuación y, como se puede ver claramente, el marco de trabajo Zero123++ logra el mejor rendimiento en el conjunto de datos de validación.

Evaluación de Texto a Vistas Múltiples
Para evaluar la capacidad del marco de trabajo Zero123++ en la generación de contenido de texto a vistas múltiples, los desarrolladores primero utilizan el marco de trabajo SDXL con promociones de texto para generar una imagen, y luego emplean el marco de trabajo Zero123++ en la imagen generada. Los resultados se demuestran en la siguiente imagen, y como se puede ver, en comparación con el marco de trabajo Zero-1-a-3 que no puede garantizar la generación de vistas múltiples coherentes, el marco de trabajo Zero123++ devuelve imágenes de vistas múltiples coherentes, realistas y muy detalladas mediante la implementación del enfoque o canalización de texto a imagen a vistas múltiples.

Zero123++ Depth ControlNet
Además del marco de trabajo Zero123++ base, los desarrolladores también han lanzado el ControlNet de profundidad Zero123++, una versión controlada por profundidad del marco de trabajo original construido utilizando la arquitectura ControlNet. Las imágenes lineales normalizadas se renderizan con respecto a las imágenes RGB subsiguientes, y se entrena un marco de trabajo ControlNet para controlar la geometría del marco de trabajo Zero123++ utilizando la percepción de profundidad.


Conclusión
En este artículo, hemos hablado sobre Zero123++, un modelo de IA generativo condicionado por imágenes que tiene como objetivo generar imágenes de vistas múltiples coherentes en 3D a partir de una sola vista de entrada. Para maximizar la ventaja obtenida de los modelos generativos preentrenados, el marco de trabajo Zero123++ implementa numerosos esquemas de entrenamiento y acondicionamiento para minimizar el esfuerzo necesario para ajustar los modelos de difusión de imágenes fuera de la caja. También hemos analizado las diferentes técnicas y mejoras implementadas por el marco de trabajo Zero123++ que le permiten lograr resultados comparables a, e incluso superar, los logrados por los marcos de trabajo de estado del arte actuales.
Sin embargo, a pesar de su eficiencia y capacidad para generar imágenes de vistas múltiples coherentes de alta calidad, el marco de trabajo Zero123++ todavía tiene margen de mejora, con posibles áreas de investigación como un
- Modelo de Refinador de Dos Etapas que podría resolver la incapacidad del marco de trabajo Zero123++ para cumplir con los requisitos globales de coherencia.
- Escalas Adicionales para mejorar aún más la capacidad del marco de trabajo Zero123++ para generar imágenes de alta calidad.












