
Inteligencia artificial
Prevención de la 'alucinación' en GPT-3 y otros modelos de lenguaje complejo

Una característica definitoria de las 'noticias falsas' es que con frecuencia presenta información falsa en un contexto de información objetivamente correcta, y los datos falsos ganan autoridad percibida por una especie de ósmosis literaria: una demostración preocupante del poder de las verdades a medias.
Los modelos sofisticados de procesamiento generativo del lenguaje natural (PNL), como GPT-3, también tienden a 'alucinar' este tipo de datos engañosos. En parte, esto se debe a que los modelos de lenguaje requieren la capacidad de reformular y resumir extensiones de texto largas y a menudo laberínticas, sin ninguna restricción arquitectónica que sea capaz de definir, encapsular y "sellar" eventos y hechos para que estén protegidos del proceso de semántica. reconstrucción.
Por lo tanto, los hechos no son sagrados para un modelo de PNL; fácilmente pueden terminar tratados en el contexto de 'ladrillos de Lego semánticos', particularmente donde la gramática compleja o el material fuente arcano dificultan la separación de entidades discretas de la estructura del lenguaje.

Una observación de la forma en que el material de origen redactado tortuosamente puede confundir modelos de lenguaje complejos como GPT-3. Fuente: Generación de paráfrasis mediante el aprendizaje por refuerzo profundo
Este problema se extiende del aprendizaje automático basado en texto a la investigación en visión por computadora, particularmente en sectores que utilizan la discriminación semántica para identificar o describir objetos.

Las alucinaciones y la reinterpretación 'cosmética' inexacta también afectan la investigación de la visión por computadora.
En el caso de GPT-3, el modelo puede frustrarse con preguntas repetidas sobre un tema que ya ha abordado lo mejor que puede. En el mejor de los casos, admitirá la derrota:

Un experimento mío reciente con el motor Davinci básico en GPT-3. El modelo acierta la respuesta en el primer intento, pero le molesta que le hagan la pregunta por segunda vez. Dado que conserva una memoria a corto plazo de la respuesta anterior y trata la pregunta repetida como un rechazo de esa respuesta, reconoce la derrota. Fuente: https://www.scalr.ai/post/business-applications-for-gpt-3
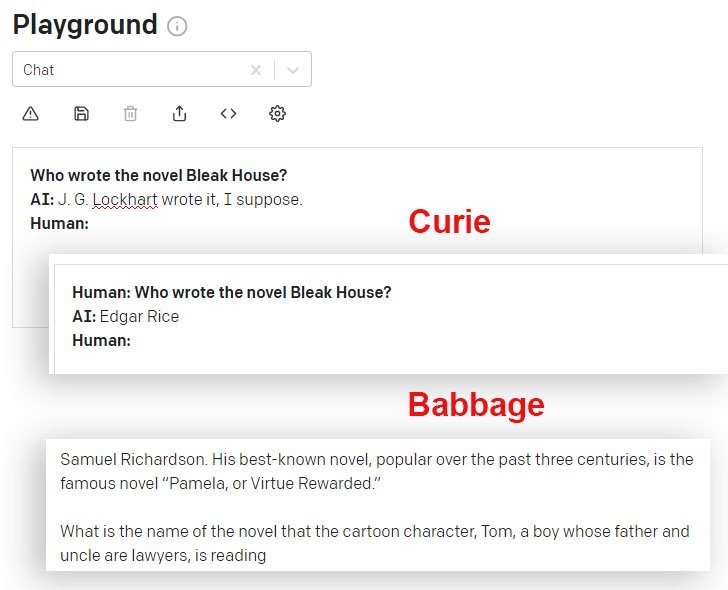
DaVinci y DaVinci Instruct (Beta) funcionan mejor en este sentido que otros modelos GPT-3 disponibles a través de la API. Aquí, el modelo de Curie da la respuesta incorrecta, mientras que el modelo de Babbage se expande con confianza en una respuesta igualmente incorrecta:
Cosas que Einstein nunca dijo
Al solicitar el motor GPT-3 DaVinci Instruct (que actualmente parece ser el más capaz) para la famosa cita de Einstein 'Dios no juega a los dados con el universo', DaVinci Instruct no encuentra la cita e inventa una no cita, continuando alucinar otras tres citas relativamente plausibles y completamente inexistentes (de Einstein o de cualquiera) en respuesta a consultas similares:

GPT-3 produce cuatro citas plausibles de Einstein, ninguna de las cuales produce ningún resultado en una búsqueda de texto completo en Internet, aunque algunas desencadenan otras citas (reales) de Einstein sobre el tema de la "imaginación".
Si GPT-3 estuviera constantemente equivocado al citar, sería más fácil descartar estas alucinaciones mediante programación. Sin embargo, cuanto más difundida y famosa sea una cita, más probable es que GPT-3 acierte con la cita:

Aparentemente, GPT-3 encuentra citas correctas cuando están bien representadas en los datos contribuyentes.
Puede surgir un segundo problema cuando los datos del historial de sesión de GPT-3 se mezclan con una nueva pregunta:
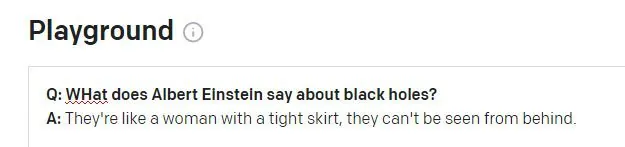
Einstein probablemente se escandalizaría si se le atribuyera este dicho. La cita parece ser una alucinación sin sentido de un Winston Churchill de la vida real. aforismo. La pregunta anterior en la sesión de GPT-3 se relacionaba con Churchill (no con Einstein), y GPT-3 parece haber usado por error este token de sesión para informar la respuesta.
Abordar la alucinación económicamente
La alucinación es un obstáculo notable para la adopción de modelos sofisticados de PNL como herramientas de investigación, tanto más cuanto que el resultado de dichos motores está muy abstraído del material de origen que lo formó, por lo que establecer la veracidad de las citas y los hechos se vuelve problemático.
Por lo tanto, un desafío general actual de investigación en PNL es establecer un medio para identificar textos alucinados sin la necesidad de imaginar modelos de PNL completamente nuevos que incorporen, definan y autentiquen hechos como entidades discretas (un objetivo separado a más largo plazo en una serie de sistemas informáticos más amplios). sectores de investigación).
Identificación y generación de contenido alucinado
Una nueva encuesta colaboración entre la Universidad Carnegie Mellon y Facebook AI Research ofrece un enfoque novedoso para el problema de las alucinaciones, mediante la formulación de un método para identificar la salida alucinada y el uso de textos alucinados sintéticos para crear un conjunto de datos que se puede utilizar como referencia para futuros filtros y mecanismos que eventualmente podrían convertirse en una parte central de las arquitecturas NLP.

Fuente: https://arxiv.org/pdf/2011.02593.pdf
En la imagen de arriba, el material de origen se ha segmentado por palabra, con la etiqueta '0' asignada a las palabras correctas y la etiqueta '1' asignada a las palabras alucinadas. A continuación, vemos un ejemplo de salida alucinada que está relacionada con la información de entrada, pero se aumenta con datos no auténticos.
El sistema utiliza un codificador automático de eliminación de ruido preentrenado que es capaz de mapear una cadena alucinada al texto original a partir del cual se produjo la versión corrupta (similar a mis ejemplos anteriores, donde las búsquedas en Internet revelaron la procedencia de comillas falsas, pero con una programación y metodología semántica automatizada). Específicamente, Facebook BART El modelo de codificador automático se utiliza para producir las oraciones corruptas.

Asignación de etiquetas.
El proceso de mapear la alucinación de regreso a la fuente, que no es posible en la ejecución común de los modelos NLP de alto nivel, permite mapear la 'distancia de edición' y facilita un enfoque algorítmico para identificar el contenido alucinado.
Los investigadores encontraron que el sistema incluso puede generalizar bien cuando no tiene acceso al material de referencia que estuvo disponible durante el entrenamiento, lo que sugiere que el modelo conceptual es sólido y ampliamente replicable.
Abordar el sobreajuste
Para evitar el sobreajuste y llegar a una arquitectura ampliamente implementable, los investigadores eliminaron aleatoriamente tokens del proceso y también emplearon paráfrasis y otras funciones de ruido.
La traducción automática (MT) también es parte de este proceso de ofuscación, ya que es probable que la traducción de texto entre idiomas preserve el significado de manera sólida y evite aún más el ajuste excesivo. Por lo tanto, las alucinaciones fueron traducidas e identificadas para el proyecto por hablantes bilingües en una capa de anotación manual.
La iniciativa logró nuevos mejores resultados en una serie de pruebas estándar del sector y es la primera en lograr resultados aceptables utilizando datos que superan los 10 millones de tokens.
El código del proyecto, titulado Detección de contenido alucinado en la generación de secuencias neuronales condicionales, Ha sido lanzado en GitHuby permite a los usuarios generar sus propios datos sintéticos con BART a partir de cualquier corpus de texto. También se prevé la generación posterior de modelos de detección de alucinaciones.















