Inteligencia artificial
Alterando Emociones en Metrajes de Video con IA

Investigadores de Grecia y el Reino Unido han desarrollado un enfoque de aprendizaje profundo novedoso para cambiar las expresiones y el estado de ánimo aparente de las personas en metrajes de video, mientras preservan la fidelidad de los movimientos de los labios con respecto al audio original de una manera que los intentos anteriores no han podido igualar.

Del video que acompaña el artículo (incrustado al final de este artículo), un breve clip del actor Al Pacino con su expresión sutilmente alterada por NED, basado en conceptos semánticos de alto nivel que definen expresiones faciales individuales y sus emociones asociadas. El método ‘Reference-Driven’ de la derecha toma la emoción interpretada de un video de origen y la aplica a toda una secuencia de video. Fuente: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Este campo en particular cae en la categoría en crecimiento de emociones deepfaked, donde se preserva la identidad del hablante original, pero se alteran sus expresiones y microexpresiones. A medida que esta tecnología de IA madura, ofrece la posibilidad de que las producciones de cine y televisión realicen alteraciones sutiles en las expresiones de los actores, pero también abre una categoría bastante nueva de ‘deepfakes de video con emociones alteradas’.
Cambiar Rostros
Las expresiones faciales de figuras públicas, como políticos, están rigurosamente curadas; en 2016, las expresiones faciales de Hillary Clinton estuvieron bajo intensa escrutinio de los medios por su posible impacto negativo en sus perspectivas electorales; las expresiones faciales, resulta, también son un tema de interés para el FBI; y son un indicador crítico en entrevistas de trabajo, lo que hace que la perspectiva lejana de un filtro de control de expresiones en vivo sea un desarrollo deseable para los buscadores de empleo que intentan pasar una preselección en Zoom.
Un estudio de 2005 del Reino Unido afirmó que la apariencia facial afecta las decisiones de votación, mientras que una característica de 2019 de The Washington Post examinó el uso de clips de video ‘fuera de contexto’, que es actualmente la cosa más cercana que los partidarios de las noticias falsas tienen a poder cambiar realmente cómo parece que una figura pública se está comportando, respondiendo o sintiendo.
Hacia la Manipulación Neural de Expresiones
En este momento, el estado del arte en la manipulación de afecto facial es bastante rudimentario, ya que implica abordar el desentrelazamiento de conceptos de alto nivel (como triste, enojado, feliz, sonriente) del contenido de video real. Aunque las arquitecturas de deepfakes tradicionales parecen lograr este desentrelazamiento bastante bien, reflejar emociones a través de diferentes identidades todavía requiere que dos conjuntos de entrenamiento de rostros contengan expresiones coincidentes para cada identidad.

Ejemplos típicos de imágenes de rostros en conjuntos de datos utilizados para entrenar deepfakes. Actualmente, solo puedes manipular la expresión facial de una persona creando rutas de expresión a expresión específicas de ID en una red neural de deepfake. El software de deepfake de 2017 no tiene una comprensión intrínseca, semántica de una ‘sonrisa’ – simplemente mapea y coincide con los cambios percibidos en la geometría facial entre los dos sujetos.
Lo que es deseable y no se ha logrado perfectamente es reconocer cómo sonríe el sujeto B (por ejemplo) y simplemente crear un interruptor de ‘sonrisa‘ en la arquitectura, sin necesidad de mapearlo a una imagen equivalente del sujeto A sonriendo.
El nuevo artículo se titula Neural Emotion Director: Control semántico de expresiones faciales en videos ‘in-the-wild’ que preserva el habla, y proviene de investigadores de la Escuela de Ingeniería Eléctrica y Computación de la Universidad Técnica Nacional de Atenas, el Instituto de Ciencias de la Computación de la Fundación para la Investigación y la Tecnología Hellas (FORTH), y la Facultad de Ingeniería, Matemáticas y Ciencias Físicas de la Universidad de Exeter en el Reino Unido.
El equipo ha desarrollado un marco llamado Neural Emotion Director (NED), que incorpora una red de traducción de emociones basada en 3D, 3D-Based Emotion Manipulator.
NED toma una secuencia recibida de parámetros de expresión y los traduce a un dominio objetivo. Se entrena en datos no pareados, lo que significa que no es necesario entrenar en conjuntos de datos donde cada identidad tenga expresiones faciales coincidentes.
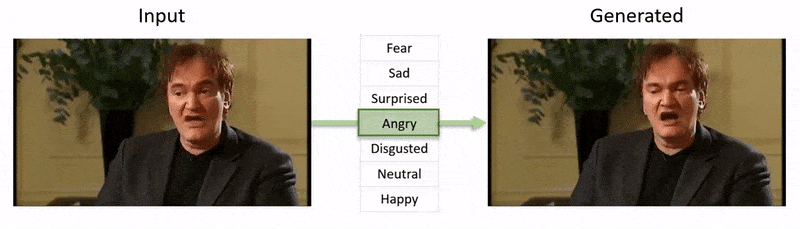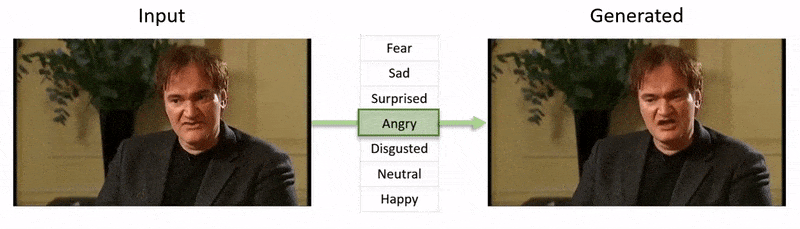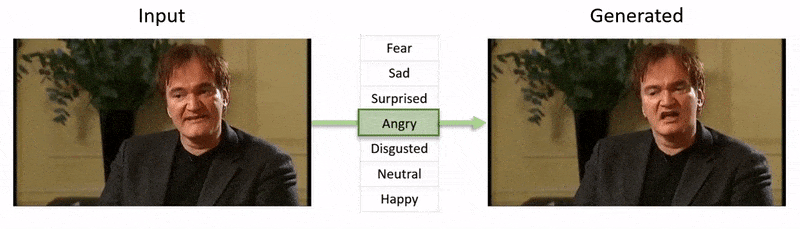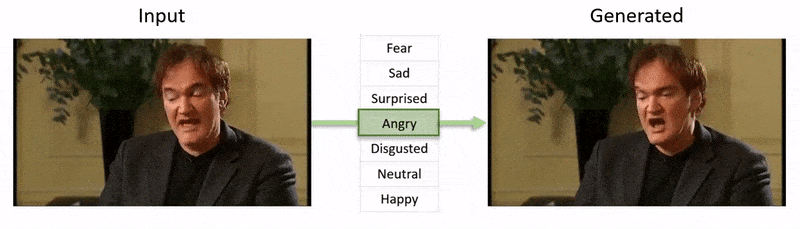
El video, mostrado al final de este artículo, pasa por una serie de pruebas donde NED impone un estado emocional aparente en metrajes del conjunto de datos de YouTube.
Los autores afirman que NED es el primer método basado en video para ‘dirigir’ a actores en situaciones aleatorias e impredecibles, y han puesto el código a disposición en la página del proyecto de NED.
Método y Arquitectura
El sistema se entrena en dos grandes conjuntos de datos de video que han sido anotados con etiquetas de ’emoción’.
La salida está habilitada por un renderizador de rostros de video que renderiza la emoción deseada al video utilizando técnicas de síntesis de imágenes faciales tradicionales, incluyendo segmentación de rostros, alineación de puntos de referencia faciales y mezcla, donde solo se sintetiza el área facial y luego se impone sobre el metraje original.

La arquitectura para la canalización del Detector de Emociones Neural (NED). Fuente: https://arxiv.org/pdf/2112.00585.pdf
Inicialmente, el sistema obtiene la recuperación facial 3D y impone alineaciones de puntos de referencia faciales en los fotogramas de entrada para identificar la expresión. Después de esto, estos parámetros de expresión recuperados se pasan al Manipulador de Emociones Basado en 3D, y un vector de estilo calculado por medio de una etiqueta semántica (como ‘feliz’) o por un archivo de referencia.
Un archivo de referencia es un video que representa una expresión/emoción reconocida particular, que se impone sobre toda la secuencia de video objetivo, intercambiando la expresión original.

Etapa en la canalización de transferencia de emociones, con varios actores muestreados de videos de YouTube.
La forma de rostro 3D generada final se concatena con la Coordinada de Rostro Normalizada Media (NMFC) y las imágenes de ojos (los puntos rojos en la imagen de arriba), y se pasa al renderizador neural, que realiza la manipulación final.
Resultados
Los investigadores realizaron estudios extensivos, incluyendo estudios de usuario y de ablación, para evaluar la efectividad del método en comparación con trabajos anteriores, y encontraron que en la mayoría de las categorías, NED supera el estado actual del arte en este subsector de manipulación facial neural.

Los autores del artículo vislumbran que implementaciones posteriores de este trabajo, y herramientas de naturaleza similar, serán útiles principalmente en las industrias de la televisión y el cine, afirmando:
‘Nuestro método abre una gran cantidad de nuevas posibilidades para aplicaciones útiles de tecnologías de renderizado neural, que van desde la postproducción de películas y videojuegos hasta avatares afectivos fotorealistas.’
Este es un trabajo temprano en el campo, pero uno de los primeros en intentar la reencarnación facial con video en lugar de imágenes fijas. Aunque los videos son esencialmente muchas imágenes fijas que se ejecutan muy rápido, hay consideraciones temporales que hacen que las aplicaciones anteriores de transferencia de emociones sean menos efectivas. En el video que acompaña y los ejemplos en el artículo, los autores incluyen comparaciones visuales de la salida de NED contra otros métodos recientes comparables.

Se pueden encontrar comparaciones más detalladas y muchos más ejemplos de NED en el video completo:
3 de diciembre de 2021, 18:30 GMT+2 – A petición de uno de los autores del artículo, se realizaron correcciones con respecto al ‘archivo de referencia’, que equivocadamente afirmé que era una foto fija (cuando en realidad es un clip de video). También se realizó una enmienda al nombre del Instituto de Ciencias de la Computación de la Fundación para la Investigación y la Tecnología.
3 de diciembre de 2021, 20:50 GMT+2 – Una segunda solicitud de uno de los autores del artículo para una enmienda adicional al nombre de la institución mencionada anteriormente.












