Künstliche Intelligenz
Kompletter Leitfaden zu Gemma 2: Googles neuem offenen Large Language Model

Gemma 2 baut auf seinem Vorgänger auf und bietet verbesserte Leistung und Effizienz sowie eine Reihe innovativer Funktionen, die es sowohl für Forschung als auch für praktische Anwendungen besonders attraktiv machen. Was Gemma 2 von anderen Modellen unterscheidet, ist seine Fähigkeit, eine Leistung zu erzielen, die mit viel größeren proprietären Modellen vergleichbar ist, aber in einem Paket, das für eine breitere Zugänglichkeit und Nutzung auf bescheideneren Hardware-Konfigurationen konzipiert ist.
Als ich mich mit den technischen Spezifikationen und der Architektur von Gemma 2 auseinandersetzte, war ich zunehmend von der Ingeniosität seines Designs beeindruckt. Das Modell integriert mehrere fortschrittliche Techniken, darunter neuartige Aufmerksamkeitsmechanismen und innovative Ansätze zur Trainingsstabilität, die zu seinen bemerkenswerten Fähigkeiten beitragen.

Google Open Source LLM Gemma
In diesem umfassenden Leitfaden werden wir Gemma 2 ausführlich untersuchen, seine Architektur, Schlüsselfunktionen und praktischen Anwendungen betrachten. Ob Sie ein erfahrener AI-Praktiker oder ein begeisterter Neuling auf diesem Gebiet sind, zielt dieser Artikel darauf ab, wertvolle Einblicke in die Funktionsweise von Gemma 2 und dessen Einsatzmöglichkeiten in Ihren eigenen Projekten zu vermitteln.
Was ist Gemma 2?
Gemma 2 ist Googles neuestes offenes Large Language Model, das leichtgewichtig und gleichzeitig leistungsstark konzipiert ist. Es basiert auf den gleichen Forschungsergebnissen und Technologien, die zur Erstellung der Google-Gemini-Modelle verwendet wurden, und bietet damit eine Spitzenleistung in einem zugänglicheren Paket. Gemma 2 ist in zwei Größen erhältlich:
Gemma 2 9B: Ein Modell mit 9 Milliarden Parametern
Gemma 2 27B: Ein größeres Modell mit 27 Milliarden Parametern
Jede Größe ist in zwei Varianten erhältlich:
Basismodelle: Vorge trainiert auf einem umfangreichen Textkorpus
Instruction-tuned (IT)-Modelle: Feinabgestimmt für bessere Leistung bei spezifischen Aufgaben
Modelle in Google AI Studio zugreifen: Google AI Studio – Gemma 2
Den technischen Bericht hier lesen: Gemma 2 Technical Report
Schlüsselfunktionen und Verbesserungen
Gemma 2 introduceert mehrere bedeutende Neuerungen im Vergleich zu seinem Vorgänger:
1. Erhöhte Trainingsdaten
Die Modelle wurden auf wesentlich mehr Daten trainiert:
Gemma 2 27B: Trainiert auf 13 Billionen Token
Gemma 2 9B: Trainiert auf 8 Billionen Token
Diese erweiterte Datenmenge, die hauptsächlich aus Webdaten (meist englisch), Code und Mathematik besteht, trägt zur verbesserten Leistung und Vielseitigkeit der Modelle bei.
2. Sliding Window Attention
Gemma 2 implementiert einen neuartigen Ansatz für Aufmerksamkeitsmechanismen:
Jede zweite Schicht verwendet eine Sliding Window Attention mit einem lokalen Kontext von 4096 Token
Alternierende Schichten verwenden eine vollständige quadratische globale Aufmerksamkeit über den gesamten Kontext von 8192 Token
Dieser hybride Ansatz zielt darauf ab, Effizienz mit der Fähigkeit zu kombinieren, langfristige Abhängigkeiten im Eingabeinput zu erfassen.
3. Soft-Capping
Um die Trainingsstabilität und Leistung zu verbessern, introduceert Gemma 2 einen Soft-Capping-Mechanismus:
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # Angewendet auf Aufmerksamkeitslogits attention_logits = soft_cap(attention_logits, cap=50.0) # Angewendet auf finale Layer-Logits final_logits = soft_cap(final_logits, cap=30.0)
Diese Technik verhindert, dass Logits übermäßig groß werden, ohne eine harte Trunkierung durchzuführen, und bewahrt so mehr Informationen, während die Trainingsstabilität erhalten bleibt.
- Gemma 2 9B: Ein Modell mit 9 Milliarden Parametern
- Gemma 2 27B: Ein größeres Modell mit 27 Milliarden Parametern
Jede Größe ist in zwei Varianten erhältlich:
- Basismodelle: Vorge trainiert auf einem umfangreichen Textkorpus
- Instruction-tuned (IT)-Modelle: Feinabgestimmt für bessere Leistung bei spezifischen Aufgaben
4. Wissensdistillation
Für das 9B-Modell verwendet Gemma 2 Wissensdistillationstechniken:
- Vor-Training: Das 9B-Modell lernt von einem größeren Lehrermodell während des anfänglichen Trainings
- Nach-Training: Sowohl das 9B- als auch das 27B-Modell verwenden On-Policy-Distillation, um ihre Leistung zu verfeinern
Dieser Prozess hilft dem kleineren Modell, die Fähigkeiten der größeren Modelle effektiver zu erfassen.
5. Modellzusammenführung
Gemma 2 nutzt eine neuartige Modellzusammenführungstechnik namens Warp, die mehrere Modelle in drei Stufen kombiniert:
- Exponentieller Moving Average (EMA) während des feinabgestimmten Trainings
- Sphärische lineare Interpolation (SLERP) nach dem feinabgestimmten Training mehrerer Richtlinien
- Lineare Interpolation zur Initialisierung (LITI) als letzter Schritt
Dieser Ansatz zielt darauf ab, ein robusteres und leistungsfähigeres Endmodell zu erstellen.
Leistungsbewertung
Gemma 2 zeigt eine beeindruckende Leistung in verschiedenen Bewertungen:
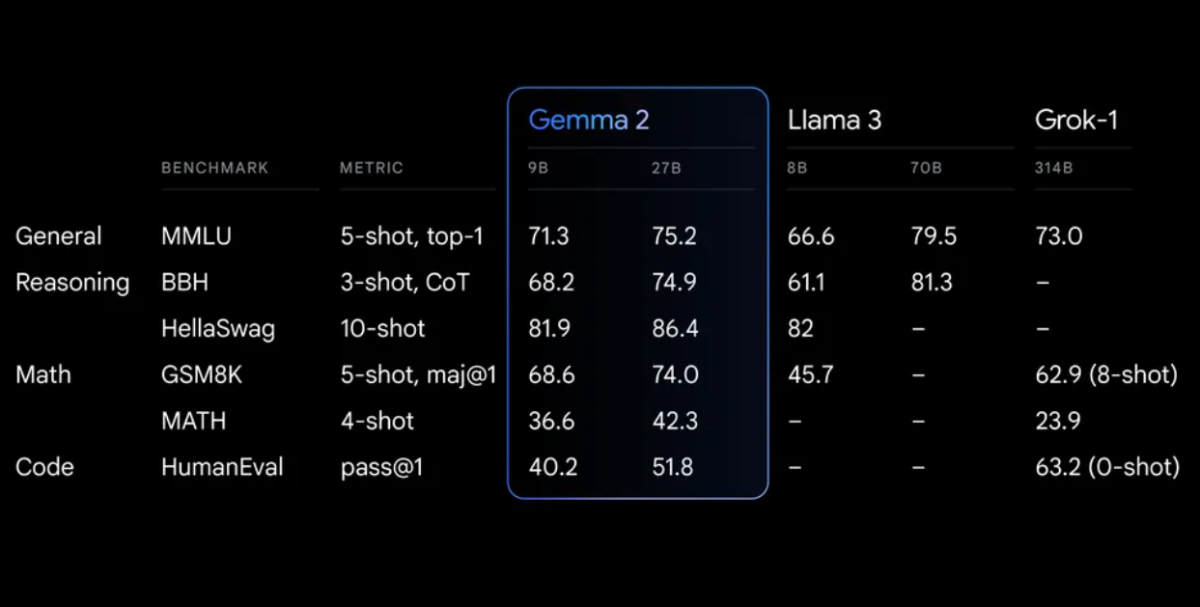
Gemma 2 auf einer neu gestalteten Architektur, die für außergewöhnliche Leistung und Inferenz-Effizienz konzipiert ist
Loslegen mit Gemma 2
Um mit Gemma 2 in Ihren Projekten zu beginnen, haben Sie mehrere Optionen:
1. Google AI Studio
Für schnelles Experimentieren ohne Hardware-Anforderungen können Sie auf Gemma 2 über Google AI Studio zugreifen.
2. Hugging Face Transformers
Gemma 2 ist in die beliebte Hugging Face-Transformers-Bibliothek integriert. Hier erfahren Sie, wie Sie es verwenden können:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Modell und Tokenizer laden model_name = "google/gemma-2-27b-it" # oder "google/gemma-2-9b-it" für die kleinere Version tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Eingabe vorbereiten prompt = "Erklären Sie das Konzept der Quantenverschränkung in einfachen Worten." inputs = tokenizer(prompt, return_tensors="pt") # Text generieren outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Für TensorFlow-Benutzer ist Gemma 2 über Keras verfügbar:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Modell laden
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Text generieren
prompt = "Erklären Sie das Konzept der Quantenverschränkung in einfachen Worten."
output = model.generate(prompt, max_length=200)
print(output)
Erweiterte Verwendung: Erstellen eines lokalen RAG-Systems mit Gemma 2
Eine leistungsstarke Anwendung von Gemma 2 ist das Erstellen eines Retrieval Augmented Generation (RAG)-Systems. Lassen Sie uns ein einfaches, vollständig lokales RAG-System mit Gemma 2 und Nomic-Embeddings erstellen.
Schritt 1: Umgebung einrichten
Stellen Sie sicher, dass Sie die notwendigen Bibliotheken installiert haben:
pip install langchain ollama nomic chromadb
Schritt 2: Dokumente indizieren
Erstellen Sie einen Indexer, um Ihre Dokumente zu verarbeiten:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
documents = loader.load()
return self.text_splitter.split_documents(documents)
def create_vector_store(self, documents):
return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")
def index(self):
documents = self.load_and_split_documents()
vector_store = self.create_vector_store(documents)
vector_store.persist()
return vector_store
# Verwendung
indexer = Indexer("Pfad/zu/Ihren/Dokumenten")
vector_store = indexer.index()
Schritt 3: RAG-System einrichten
Jetzt erstellen wir das RAG-System mit Gemma 2:
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})
self.template = """
Verwenden Sie die folgenden Kontexte, um die Frage am Ende zu beantworten.
Wenn Sie die Antwort nicht kennen, sagen Sie einfach, dass Sie sie nicht wissen, versuchen Sie nicht, eine Antwort zu erfinden.
{context}
Frage: {question}
Antwort: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)
def query(self, question):
return self.qa_chain({"query": question})
# Verwendung
rag_system = RAGSystem(vector_store)
response = rag_system.query("Was ist die Hauptstadt von Frankreich?")
print(response["result"])
Dieses RAG-System verwendet Gemma 2 über Ollama für das Sprachmodell und Nomic-Embeddings für die Dokumentenrückgewinnung. Es ermöglicht es Ihnen, Fragen auf der Grundlage der indizierten Dokumente zu stellen und Antworten mit Kontext aus den relevanten Quellen zu erhalten.
Feinabstimmung von Gemma 2
Für spezifische Aufgaben oder Domänen möchten Sie Gemma 2 möglicherweise feinabstimmen. Hier ist ein grundlegender Beispiel mit der Hugging Face Transformers-Bibliothek:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Modell und Tokenizer laden
model_name = "google/gemma-2-9b-it";
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Dataset vorbereiten
dataset = load_dataset("Ihr_Dataset")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Trainingsargumente einrichten
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Trainer initialisieren
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# Feinabstimmung starten
trainer.train()
# Feinabgestimmtes Modell speichern
model.save_pretrained("./fein_abgestimmtes_gemma2")
tokenizer.save_pretrained("./fein_abgestimmtes_gemma2")
Denken Sie daran, die Trainingsparameter basierend auf Ihren spezifischen Anforderungen und Rechenressourcen anzupassen.
Ethische Überlegungen und Einschränkungen
Während Gemma 2 beeindruckende Fähigkeiten bietet, ist es wichtig, sich seiner Einschränkungen und ethischen Überlegungen bewusst zu sein:
- Vorurteile: Wie alle Sprachmodelle kann Gemma 2 Vorurteile widerspiegeln, die in seinen Trainingsdaten vorhanden sind. Bewerten Sie seine Ausgaben immer kritisch.
- Sachliche Genauigkeit: Obwohl Gemma 2 sehr leistungsfähig ist, kann es manchmal falsche oder inkonsistente Informationen generieren. Überprüfen Sie wichtige Fakten aus verlässlichen Quellen.
- Kontextlänge: Gemma 2 hat eine Kontextlänge von 8192 Token. Für längere Dokumente oder Gespräche müssen Sie möglicherweise Strategien zur Kontextverwaltung implementieren.
- Rechenressourcen: Insbesondere für das 27B-Modell können erhebliche Rechenressourcen für effiziente Inferenz und Feinabstimmung erforderlich sein.
- Verantwortungsvoller Einsatz: Halten Sie sich an Googles Grundsätze für verantwortungsvolle KI und stellen Sie sicher, dass Ihre Verwendung von Gemma 2 mit ethischen KI-Prinzipien übereinstimmt.
Schlussfolgerung
Gemma 2 bietet fortschrittliche Funktionen wie Sliding Window Attention, Soft-Capping und neuartige Modellzusammenführungstechniken, die es zu einem leistungsstarken Werkzeug für eine Vielzahl von Aufgaben im Bereich der natürlichen Sprachverarbeitung machen.
Durch die Nutzung von Gemma 2 in Ihren Projekten, sei es durch einfache Inferenz, komplexe RAG-Systeme oder feinabgestimmte Modelle für spezifische Domänen, können Sie die Leistung von Spitzen-AI-Technologie nutzen, während Sie die Kontrolle über Ihre Daten und Prozesse behalten.












