Künstliche Intelligenz
Richtung Echtzeit-KI-Menschen mit Neural Lumigraph Rendering

Trotz der aktuellen Welle des Interesses an Neural Radiance Fields (NeRF), einer Technologie, die in der Lage ist, AI-generierte 3D-Umgebungen und -Objekte zu erstellen, benötigt diese neue Ansatz zur Bildsynthesetechnologie immer noch eine große Menge an Trainingszeit und verfügt nicht über eine Implementierung, die es ermöglicht, in Echtzeit hochresponsive Schnittstellen zu erstellen.
Allerdings bietet eine Zusammenarbeit zwischen einigen beeindruckenden Namen in der Industrie und der Wissenschaft einen neuen Ansatz für diese Herausforderung (allgemein bekannt als Novel View Synthesis oder NVS).
Das Forschungspapier paper, mit dem Titel Neural Lumigraph Rendering, behauptet, eine Verbesserung des aktuellen Standes der Technik um etwa zwei Größenordnungen, was mehrere Schritte in Richtung Echtzeit-CG-Rendering via Machine-Learning-Pipelines darstellt.

Neural Lumigraph Rendering (rechts) bietet eine bessere Auflösung von Blendartefakten und eine verbesserte Handhabung von Okklusion im Vergleich zu früheren Methoden. Quelle.
Obwohl die Credits für das Papier nur die Stanford University und das Hologramm-Display-Technologie-Unternehmen Raxium (derzeit in Stealth-Modus operiert) nennen, umfassen die Mitwirkenden einen leitenden Machine-Learning-Architekten bei Google, einen Computerwissenschaftler bei Adobe und den CTO bei StoryFile (das kürzlich mit einer AI-Version von William Shatner Schlagzeilen machte).
In Bezug auf die jüngste Shatner-Publicity-Kampagne scheint StoryFile NLR in seinem neuen Prozess zur Erstellung interaktiver, AI-generierter Entitäten auf der Grundlage der Eigenschaften und Erzählungen einzelner Personen einzusetzen.
StoryFile stellt sich die Verwendung dieser Technologie in Museumsausstellungen, interaktiven Online-Erzählungen, Hologramm-Displays, erweiterter Realität (AR) und Dokumentationen des kulturellen Erbes vor – und scheint auch potenzielle neue Anwendungen von NLR in Bewerbungsgesprächen und virtuellen Dating-Anwendungen zu prüfen:

Vorgeschlagene Anwendungen aus einem Online-Video von StoryFile. Quelle: https://www.youtube.com/watch?v=2K9J6q5DqRc
Volumetrische Erfassung für Novel View Synthesis-Schnittstellen und Video
Das Prinzip der volumetrischen Erfassung, über die gesamte Bandbreite von Papieren, die sich mit diesem Thema beschäftigen, ist die Idee, Stillbilder oder Videos eines Subjekts aufzunehmen und mithilfe von Machine Learning die nicht abgedeckten Blickwinkel zu “auffüllen”.

Quelle: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
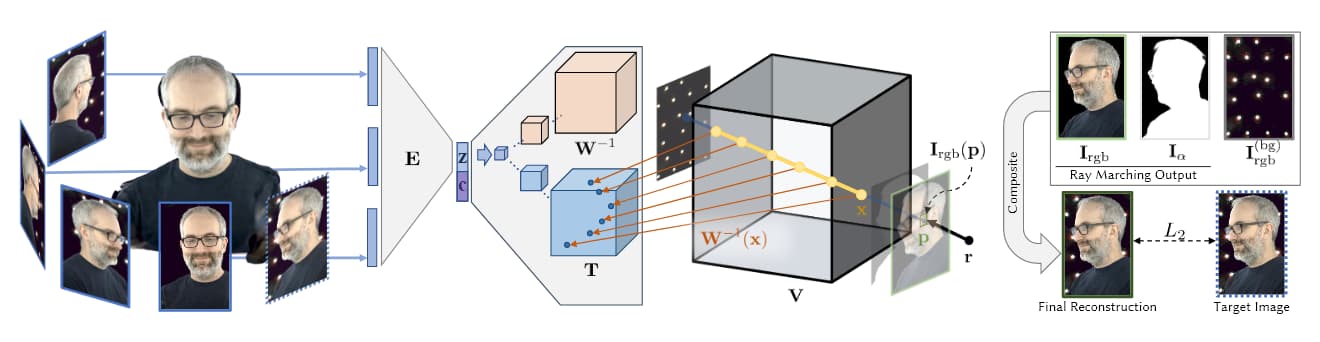
In dem oben gezeigten Bild, das aus Facebooks AI-Forschung von 2019 stammt (siehe unten), sehen wir die vier Stufen der volumetrischen Erfassung: Mehrere Kameras nehmen Bilder/Aufnahmen auf; Encoder/Decoder-Architektur (oder andere Architekturen) berechnen und verbinden die Relativität der Ansichten; Ray-Marching-Algorithmen berechnen die Voxels (oder andere XYZ-Spatial-Geometrie-Einheiten) jedes Punktes im volumetrischen Raum; und (in den meisten aktuellen Papieren) findet ein Training statt, um eine vollständige Entität zu synthetisieren, die in Echtzeit manipuliert werden kann.
Es ist diese oft umfangreiche und datenintensive Trainingsphase, die Novel View Synthesis bislang aus dem Bereich der Echtzeit- oder hochresponsiven Erfassung herausgehalten hat.
Die Tatsache, dass Novel View Synthesis eine vollständige 3D-Karte eines volumetrischen Raums erstellt, bedeutet, dass es relativ trivial ist, diese Punkte zusammenzufügen, um eine traditionelle Computer-Generierte-Mesh (CG-Mesh) zu erstellen, die effektiv eine CGI-Person (oder jedes andere relativ begrenzte Objekt) auf die Schnelle erfasst und artikuliert.
Ansätze, die NeRF verwenden, basieren auf Punktwolken und Tiefenkartierungen, um die Interpolationen zwischen den spärlichen Punkten der Erfassungsgeräte zu generieren:

NeRF kann volumetrische Tiefen durch Berechnung von Tiefenkartierungen und nicht durch Erstellung von CG-Meshes generieren. Quelle: https://www.youtube.com/watch?v=JuH79E8rdKc
Obwohl NeRF in der Lage ist, Meshes zu berechnen, verwenden die meisten Implementierungen dies nicht, um volumetrische Szenen zu generieren.
Im Gegensatz dazu basiert der Implicit Differentiable Renderer (IDR)-Ansatz, der im Oktober 2020 vom Weizmann Institute of Science veröffentlicht wurde, auf der Ausbeutung von 3D-Mesh-Informationen, die automatisch aus Erfassungsarrays generiert werden:

Beispiele für IDR-Erfassungen, die in interaktive CGI-Meshes umgewandelt wurden. Quelle: https://www.youtube.com/watch?v=C55y7RhJ1fE
Während NeRF die Fähigkeit von IDR zur Formenschätzung fehlt, kann IDR nicht die Bildqualität von NeRF erreichen, und beide erfordern umfangreiche Ressourcen, um zu trainieren und zu kombinieren (obwohl kürzliche Innovationen in NeRF beginnen, dies anzugehen).

NLRs benutzerdefinierte Kamerarig mit 16 GoPro HERO7 und 6 zentralen Back-Bone H7PRO-Kameras. Für die ‘Echtzeit’-Wiedergabe betreiben diese mit einer Mindestgeschwindigkeit von 60fps. Quelle: https://arxiv.org/pdf/2103.11571.pdf
Stattdessen nutzt Neural Lumigraph Rendering SIREN (Sinusoidale Repräsentationsnetzwerke), um die Stärken jedes Ansatzes in sein eigenes Framework zu integrieren, das darauf abzielt, eine Ausgabe zu erzeugen, die direkt in bestehende Echtzeit-Grafikpipelines verwendbar ist.
SIREN wurde für ähnliche Implementierungen im Laufe des letzten Jahres verwendet und stellt nun einen beliebten API-Aufruf für Hobby-Colabs in Bildsynthese-Communities dar; jedoch ist NLRs Innovation, SIRENs auf zweidimensionale Multi-View-Bildsupervision anzuwenden, was aufgrund des Ausmaßes, in dem SIREN überanpasste anstelle von verallgemeinerten Ausgaben produziert, problematisch ist.
Nachdem die CG-Mesh aus den Array-Bildern extrahiert wurde, wird die Mesh über OpenGL gerastert und die Vertex-Positionen der Mesh auf die entsprechenden Pixel abgebildet, wonach die Blendung der verschiedenen Beitragskarten berechnet wird.
Die resultierende Mesh ist verallgemeineter und repräsentativer als die von NeRF (siehe Bild unten), erfordert weniger Berechnungen und wendet keine übermäßigen Details auf Bereiche an (wie glatte Gesichtshaut), die nicht von ihnen profitieren können:

Quelle: https://arxiv.org/pdf/2103.11571.pdf
Auf der negativen Seite verfügt NLR derzeit nicht über die Fähigkeit, dynamische Beleuchtung oder Relighting zu ermöglichen, und die Ausgabe ist auf Schattenkarten und andere Beleuchtungsaspekte beschränkt, die zum Zeitpunkt der Erfassung erhalten wurden. Die Forscher planen, dies in zukünftigen Arbeiten anzugehen.
Darüber hinaus räumt das Papier ein, dass die von NLR erzeugten Formen nicht so genau sind wie einige alternative Ansätze, wie z. B. Pixelwise View Selection for Unstructured Multi-View Stereo oder die vom Weizmann Institute erwähnte Forschung.
Aufstieg der volumetrischen Bildsynthese
Die Idee, 3D-Entitäten aus einer begrenzten Reihe von Fotos mit neuronalen Netzen zu erstellen, geht auf das Jahr 2007 oder früher zurück. Im Jahr 2019 veröffentlichte Facebooks AI-Forschungsabteilung ein bahnbrechendes Forschungspapier, Neural Volumes: Learning Dynamic Renderable Volumes from Images, das erstmals responsive Schnittstellen für synthetische Menschen ermöglichte, die durch machine learning-basierte volumetrische Erfassung generiert wurden.

Facebooks Forschung von 2019 ermöglichte die Erstellung einer responsiven Benutzeroberfläche für eine volumetrische Person. Quelle: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/













{kind=link}