Künstliche Intelligenz
SofGAN: Ein GAN-Gesichtsgenerator, der eine größere Kontrolle bietet
Forscher in Shanghai und den USA haben ein auf GAN basierendes Porträtgenerierungssystem entwickelt, das es Benutzern ermöglicht, neue Gesichter mit einem bisher unverfügbaren Kontrollgrad über einzelne Aspekte wie Haare, Augen, Brillen, Texturen und Farben zu erstellen.
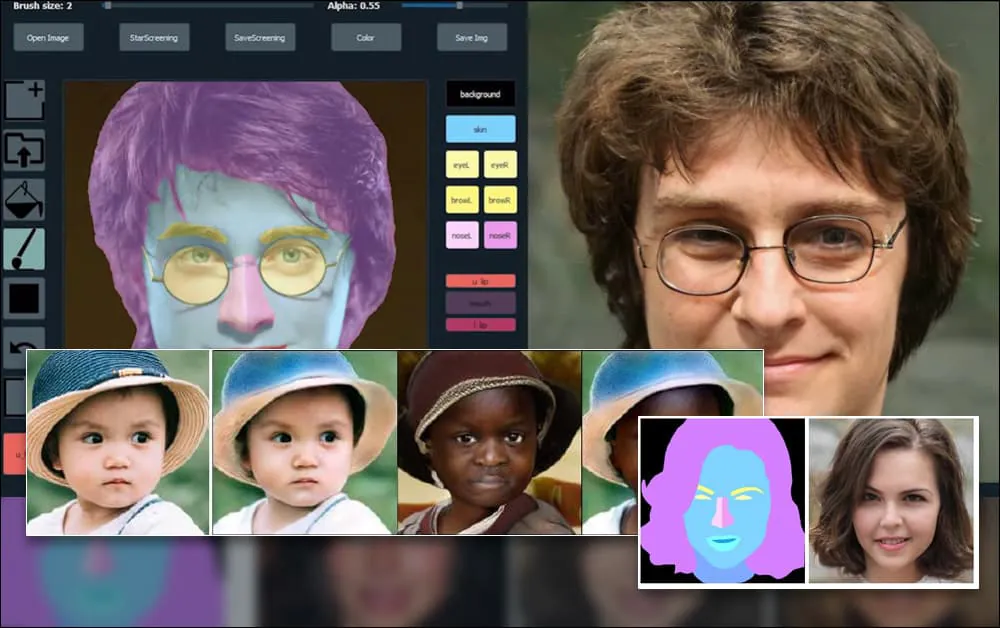
Um die Vielseitigkeit des Systems zu demonstrieren, haben die Ersteller eine Photoshop-ähnliche Oberfläche bereitgestellt, in der ein Benutzer direkt semantische Segmentierungselemente zeichnen kann, die in realistische Bilder uminterpretiert werden, und die sogar durch Zeichnen direkt über bestehende Fotografien erhalten werden können.
In dem folgenden Beispiel wird ein Bild des Schauspielers Daniel Radcliffe als Vorlage verwendet (und das Ziel ist nicht, eine Ähnlichkeit mit ihm zu produzieren, sondern ein allgemein photorealistisches Bild). Wenn der Benutzer verschiedene Elemente ausfüllt, einschließlich diskreter Aspekte wie Brillen, werden sie identifiziert und in dem Ausgabebild interpretiert:
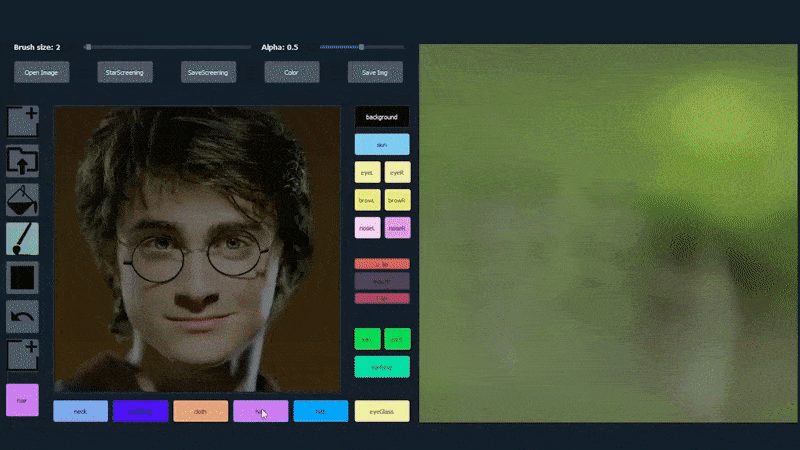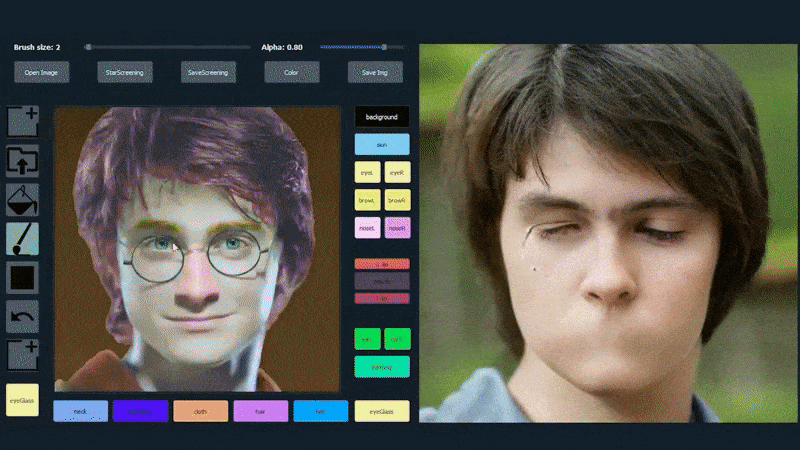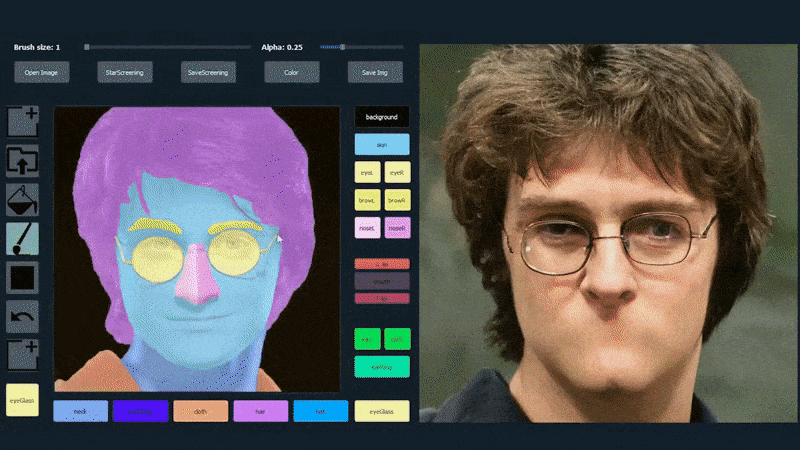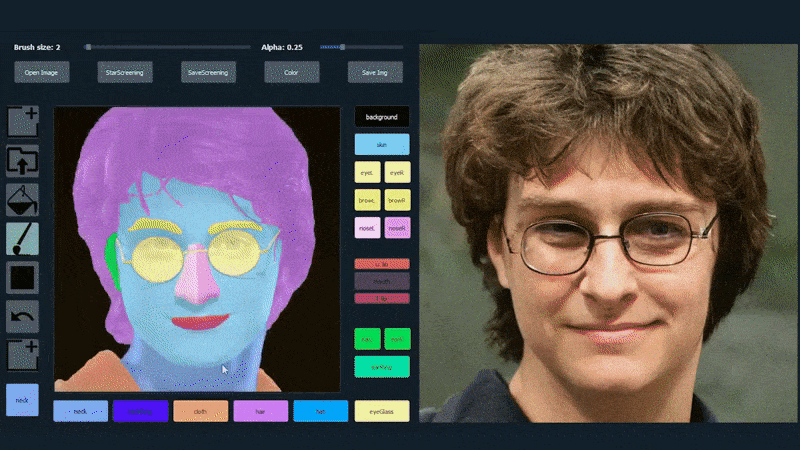
Verwendung eines Bildes als Vorlage für ein SofGAN-erzeugtes Porträt. Source: https://www.youtube.com/watch?v=xig8ZA3DVZ8
Die Veröffentlichung trägt den Titel SofGAN: Ein Porträtbildgenerator mit dynamischem Stil und wird von Anpei Chen und Ruiyang Liu geleitet, zusammen mit zwei anderen Forschern von der ShanghaiTech University und einem von der University of California in San Diego.
Merkmale entflechten
Der Hauptbeitrag der Arbeit liegt nicht so sehr in der Bereitstellung einer benutzerfreundlichen Oberfläche, sondern vielmehr in der “Entflechtung” von Merkmalen erlernter Gesichtszüge, wie Pose und Textur, was es SofGAN auch ermöglicht, Gesichter zu erzeugen, die in indirekten Winkeln zur Kameraperspektive stehen.

Unüblich unter Gesichtsgeneratoren auf der Grundlage von Generative Adversarial Networks, kann SofGAN den Blickwinkel nach Belieben ändern, innerhalb der Grenzen des Arrays von Winkeln, die in den Trainingsdaten vorhanden sind. Source: https://arxiv.org/pdf/2007.03780.pdf
Da Texturen nun von der Geometrie entflechtet sind, können Gesichtsform und Textur auch als separate Entitäten manipuliert werden. Dies ermöglicht es im Wesentlichen, die Rasse eines Quellgesichts zu ändern, eine skandalöse Praxis, die jetzt eine potenziell nützliche Anwendung für die Erstellung von rassisch ausgewogenen maschinellen Lern-Datensätzen hat.

SofGAN unterstützt auch künstliches Altern und attributkonsistentes Stil-Adjustment auf einem feinen Level, das in ähnlichen Segmentierung-Bild-Systemen wie NVIDIAs GauGAN und Intels game-basiertem neuronalen Rendering-System nicht zu sehen ist.

SofGAN kann Altern als iterativen Stil implementieren.
Ein weiterer Durchbruch für SofGANs Methodik ist, dass die Ausbildung nicht paarweise Segmentierung/Echtbilder erfordert, sondern direkt auf unpaaren Echtbildern aus der realen Welt trainiert werden kann.
Die Forscher erklären, dass die “Entflechtungs”-Architektur von SofGAN von traditionellen Bildrendering-Systemen inspiriert wurde, die die einzelnen Aspekte eines Bildes zerlegen. In visuellen Effekt-Workflows werden die Elemente für eine Zusammensetzung routinemäßig in die kleinsten Komponenten zerlegt, mit Spezialisten, die sich auf jede Komponente konzentrieren.
Semantisches Besetzungsgebiet (SOF)
Um dies in einem maschinellen Lern-Bildsynthese-Rahmen zu erreichen, entwickelten die Forscher ein semantisches Besetzungsgebiet (SOF), eine Erweiterung des traditionellen Besetzungsgebiets, das die Komponentenelemente von Gesichtsporträts individuiert. Das SOF wurde auf kalibrierten multi-view semantischen Segmentierungskarten trainiert, aber ohne jede Ground-Truth-Überwachung.

Mehrere Iterationen aus einer einzigen Segmentierungskarte (unten links).
Zusätzlich werden 2D-Segmentierungskarten durch Ray-Tracing der Ausgabe des SOF erhalten, bevor sie von einem GAN-Generator texturiert werden. Die “synthetischen” semantischen Segmentierungskarten werden auch in einem niedrigdimensionalen Raum durch einen dreischichtigen Encoder kodiert, um die Kontinuität der Ausgabe zu gewährleisten, wenn der Blickwinkel geändert wird.
Das Trainingsverfahren mischt räumlich zwei zufällige Stile für jede semantische Region:

Die Architektur für SofGAN.
Die Forscher behaupten, dass SofGAN eine geringere Frechet-Inception-Distanz (FID) als die aktuellen alternativen State-of-the-Art-Ansätze erreicht, sowie einen höheren Learned Perceptual Image Patch Similarity (LPIPS)-Wert.
Frühere StyleGAN-Ansätze wurden häufig durch Merkmalsverflechtung behindert, bei der die Elemente, die ein Bild zusammensetzen, untrennbar miteinander verbunden sind, was unerwünschte Elemente neben einem gewünschten Element hervorrufen kann (z. B. können Ohrhänger erscheinen, wenn eine Ohrform gerendert wird, die während der Trainingszeit durch ein Bild informiert wurde, das Ohrhänger aufwies).

Ray-Marching wird verwendet, um das Volumen der semantischen Segmentierungskarten zu berechnen, wodurch multiple Blickwinkel ermöglicht werden.
Datensätze und Training
Drei Datensätze wurden bei der Entwicklung verschiedener Implementierungen von SofGAN verwendet: CelebAMask-HQ, ein Repository von 30.000 hochauflösenden Bildern aus dem CelebA-HQ-Datensatz; NVIDIAs Flickr-Faces-HQ (FFHQ), das 70.000 Bilder enthält, wobei die Forscher die Bilder mit einem vorgefertigten Gesichtsparser beschriftet haben; und eine selbst produzierte Gruppe von 122 Porträtskans mit manuell beschrifteten semantischen Regionen.
Das SOF besteht aus drei trainierbaren Submodulen – dem Hyper-Netz, einem Ray-Marcher (siehe Bild oben) und einem Klassifizierer. Der Semantic Instance Wised (SIW) StyleGAN-Generator des Projekts ist ähnlich wie StyleGAN2 in bestimmten Aspekten konfiguriert. Datenverstärkung wird durch zufälliges Skalieren und Beschneiden angewendet, und das Training umfasst Pfadregularisierung alle vier Schritte. Das gesamte Trainingsverfahren dauerte 22 Tage, um 800.000 Iterationen auf vier RTX 2080 Ti-GPUs über CUDA 10.1 zu erreichen.
Die Forscher bemerken, dass akzeptable, verallgemeinerte, hochwertige Ergebnisse bereits sehr früh im Training auftraten, bei 1500 Iterationen, drei Tage nach Beginn des Trainings. Der Rest des Trainings wurde mit dem vorhersehbaren, langsamen Kriechen zur Erlangung von Feinheiten wie Haar- und Augenfacetten verbracht.
SofGAN erreicht im Allgemeinen realistischere Ergebnisse aus einer einzigen Segmentierungskarte als rivalisierende Methoden wie NVIDIAs SPADE und Pix2PixHD und SEAN.

Unten ist das von den Forschern veröffentlichte Video zu sehen. Weitere selbst gehostete Videos sind auf der Projektseite verfügbar.
https://www.youtube.com/watch?v=xig8ZA3DVZ8












