Andersons Blickwinkel
Erstellung eines benutzerdefinierten Generative Adversarial Network mit Skizzen

Forscher von der Carnegie Mellon und dem MIT haben eine neue Methode entwickelt, die es einem Benutzer ermöglicht, ein benutzerdefiniertes Generative Adversarial Network (GAN) für die Bildgenerierung zu erstellen, indem sie einfach skizzierende Skizzen erstellen.
Ein System dieser Art könnte es einem Endbenutzer ermöglichen, Bildgenerierungssysteme zu erstellen, die sehr spezifische Bilder generieren können, wie z.B. bestimmte Tiere, Gebäudetypen oder sogar einzelne Personen. Derzeit produzieren die meisten GAN-Generierungssysteme breite und ziemlich zufällige Ausgaben, mit begrenzten Möglichkeiten, bestimmte Merkmale wie Tierarten, Haartypen bei Menschen, Architekturstile oder tatsächliche Gesichtsidentitäten zu spezifizieren.
Der Ansatz, der in dem Paper Sketch Your Own GAN beschrieben wird, verwendet eine neuartige Skizzieroberfläche als effektive “Suchfunktion”, um Merkmale und Klassen in Bildatenbanken zu finden, die möglicherweise Tausende von Objekttypen enthalten, darunter viele Untertypen, die nicht relevant für die Absicht des Benutzers sind. Das GAN wird dann auf diesem gefilterten Teil der Bilder trainiert.
Indem der Benutzer das spezifische Objekt skizziert, mit dem er das GAN kalibrieren möchte, werden die generativen Fähigkeiten des Frameworks auf diese Klasse spezialisiert. Wenn beispielsweise ein Benutzer ein Framework erstellen möchte, das ein bestimmtes Tier (und nicht nur irgendein Tier, wie es mit This Cat Does Not Exist erhalten werden kann) generiert, dienen seine Eingabeskizzen als Filter, um nicht relevante Klassen von Tieren auszuschließen.

Quelle: https://peterwang512.github.io/GANSketching/
Die Forschung wird von Sheng Yu-Wang der Carnegie Mellon University geleitet, zusammen mit seinem Kollegen Jun-Yan Zhu und David Bau vom Computer Science & Artificial Intelligence Laboratory des MIT.
Die Methode selbst wird als “GAN-Skizzieren” bezeichnet und verwendet die Eingabeskizzen, um die Gewichte eines “Vorlagen”-GAN-Modells direkt zu ändern, um das identifizierte Domäne oder Subdomäne durch cross-domain-adversarialen Verlust zu zielen.
Verschiedene Regularisierungsmethoden wurden erforscht, um sicherzustellen, dass die Ausgabe des Modells vielfältig ist, während eine hohe Bildqualität beibehalten wird. Die Forscher erstellten Beispielanwendungen, die in der Lage sind, den latenten Raum zu interpolieren und Bildbearbeitungsverfahren durchzuführen.
Dieses [$class] existiert nicht
GAN-basierte Bildgenerierungssysteme sind in den letzten Jahren zu einem Trend, wenn nicht sogar zu einem Meme geworden, mit einer Verbreitung von Projekten, die in der Lage sind, Bilder von nicht existierenden Dingen zu generieren, einschließlich Menschen, Mietwohnungen, Snacks, Füßen, Pferden, Politikern und Insekten, um nur einige zu nennen.
GAN-basierte Bildsynthesesysteme werden durch die Kompilierung oder Kuratierung umfangreicher Datensätze erstellt, die Bilder aus der Ziel-domäne enthalten, wie z.B. Gesichter oder Pferde; durch das Training von Modellen, die eine Reihe von Merkmalen über die Bilder in der Datenbank verallgemeinern; und durch die Implementierung von Generatormodulen, die zufällige Beispiele basierend auf den erlernten Merkmalen ausgeben können.

Ausgabe von Skizzen in DeepFacePencil, das es Benutzern ermöglicht, photorealistische Gesichter aus Skizzen zu erstellen. Viele ähnliche Skizze-zu-Bild-Projekte existieren. Quelle: https://arxiv.org/pdf/2008.13343.pdf
Hochdimensionale Merkmale sind unter den ersten, die während des Trainingsprozesses konkreter werden, und entsprechen einem Malers ersten breiten Pinselstrichen auf einer Leinwand. Diese hochdimensionalen Merkmale werden schließlich mit viel detaillierteren Merkmalen korrelieren (z.B. dem Glanz im Auge und den scharfen Schnurrhaaren einer Katze, anstatt nur einem generischen beige-farbenen Blob, das den Kopf darstellt).
Ich verstehe, was du meinst…
Indem die Beziehung zwischen diesen frühen seminalen Formen und den letztendlich detaillierten Interpretationen, die viel später im Trainingsprozess erhalten werden, kartiert wird, kann es möglich sein, Beziehungen zwischen “vagen” und “spezifischen” Bildern abzuleiten, was es Benutzern ermöglicht, komplexe und photorealistische Bilder aus groben Skizzen zu erstellen.
Erst kürzlich veröffentlichte NVIDIA eine Desktop-Version seiner langfristigen GauGAN-Forschung zur GAN-basierten Landschaftsgenerierung, die leicht diese Prinzipien demonstriert:
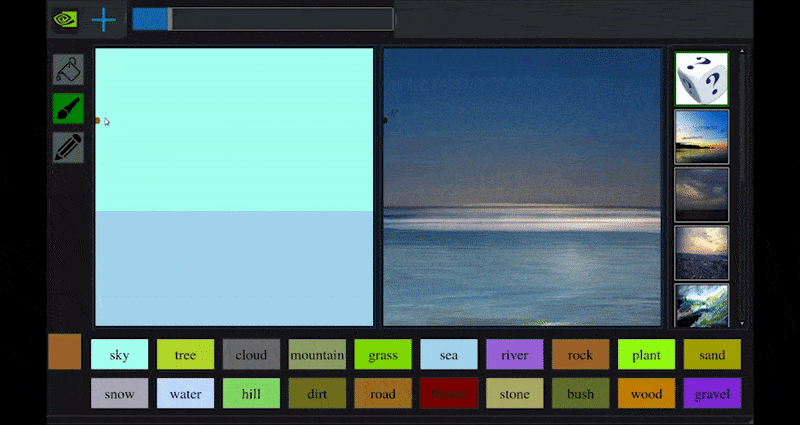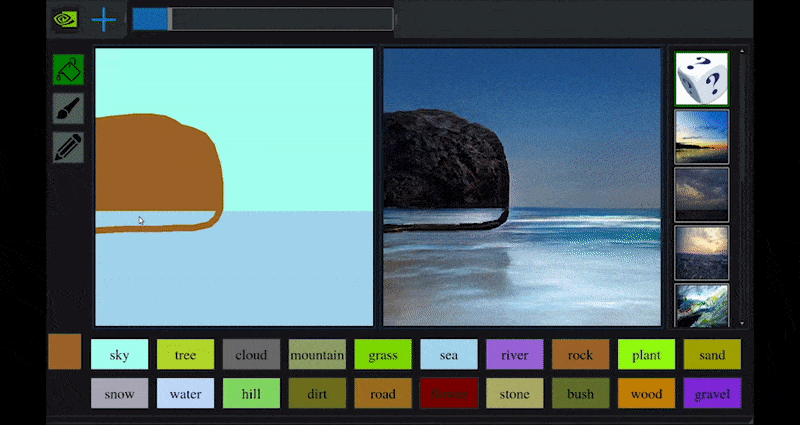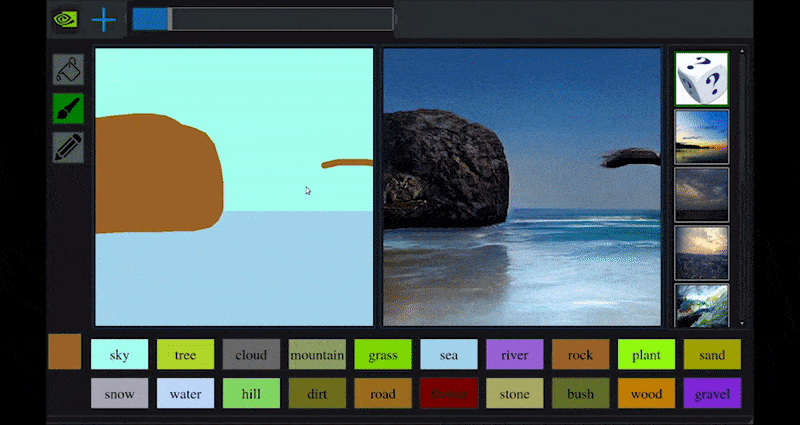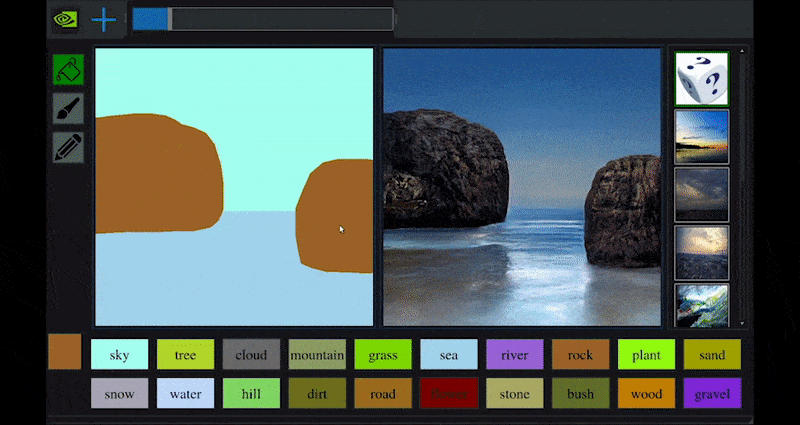
Approximative Pinselstriche werden in reiche Landschaftsbilder durch NVIDIAs GauGAN und jetzt die NVIDIA-Canvas-Anwendung umgewandelt. Quelle: https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
Ebenso haben mehrere Systeme wie DeepFacePencil dasselbe Prinzip verwendet, um skizzeninduzierte photorealistische Bildgeneratoren für verschiedene Domänen zu erstellen.

Die Architektur von DeepFacePencil.
Vereinfachung von Skizze-zu-Bild
Der neue Ansatz des GAN-Skizzierens zielt darauf ab, die enorme Belastung der Datenerfassung und -kuration zu entfernen, die normalerweise bei der Entwicklung von GAN-Bildframeworks beteiligt ist, indem Benutzereingaben verwendet werden, um zu definieren, welche Teilmenge von Bildern die Trainingsdaten bilden sollte.
Das System wurde so konzipiert, dass es nur eine kleine Anzahl von Eingabeskizzen benötigt, um das Framework zu kalibrieren. Das System kehrt im Wesentlichen die Funktionalität von PhotoSketch um, einer gemeinsamen Forschungsinitiative von 2019 von Forschern der Carnegie Mellon, Adobe, Uber ATG und Argo AI, die in die neue Arbeit integriert ist. PhotoSketch wurde entwickelt, um künstlerische Skizzen aus Bildern zu erstellen, und enthält bereits die effektive Kartierung von vagen zu spezifischen Bildschöpfungsbeziehungen.
Für den Generierungsteil des Prozesses wird nur das GAN-Modell StyleGAN2 modifiziert. Da die verwendeten Bilddaten nur eine Teilmenge der gesamten verfügbaren Daten sind, werden die gewünschten Ergebnisse durch die Modifizierung des Mapping-Netzwerks erzielt.
Die Methode wurde auf einer Reihe von populären Subdomänen getestet, einschließlich Pferden, Kirchen und Katzen.

Der LSUN-Datensatz von 2016 der Princeton University wurde als Kernmaterial verwendet, um die Ziel-Subdomänen abzuleiten. Um ein robustes Skizzier-System zu erstellen, das gegen die Exzentritäten von Eingabeskizzen von Benutzern resistent ist, wurde das System auf Bildern aus dem QuickDraw-Datensatz trainiert, der von Microsoft zwischen 2021-2016 entwickelt wurde.
Obwohl die Skizzier-Beziehungen zwischen PhotoSketch und QuickDraw sehr unterschiedlich sind, fanden die Forscher heraus, dass ihr Framework gut auf einfache Posen funktioniert, obwohl kompliziertere Posen (wie Katzen, die sich hinlegen) eine größere Herausforderung darstellen, während sehr abstrakte Benutzereingaben (z.B. übermäßig grobe Zeichnungen) auch die Qualität der Ergebnisse beeinträchtigen.

Latenter Raum und natürliche Bildbearbeitung
Die Forscher entwickelten zwei Anwendungen auf der Grundlage der Kernarbeit: latente Raumeditierung und Bildbearbeitung. Die latente Raumeditierung bietet interpretierbare Benutzersteuerungen, die während des Trainings ermöglicht werden, und ermöglichen eine breite Palette von Variationen, während sie treu zur Ziel-Domäne bleiben und angenehm konsistent über Variationen hinweg sind.

Glatte latente Rauminterpolation mit den benutzerdefinierten Modellen von GAN-Skizzieren.
Der latente Raumeditierungskomponent wurde von dem 2020er GANSpace-Projekt angetrieben, einer gemeinsamen Initiative von der Aalto-Universität, Adobe und NVIDIA.
Ein einzelnes Bild kann auch an das benutzerdefinierte Modell übergeben werden, um eine natürliche Bildbearbeitung zu ermöglichen. In dieser Anwendung wird ein einzelnes Bild auf das benutzerdefinierte GAN projiziert, um nicht nur eine direkte Bearbeitung zu ermöglichen, sondern auch die höhere latente Raumeditierung zu erhalten, wenn diese auch verwendet wird.

Hier wurde ein reales Bild als Eingabe für das GAN (Katzenmodell) verwendet, das die Eingabe bearbeitet, um den eingereichten Skizzen zu entsprechen. Dies ermöglicht eine Bildbearbeitung durch Skizzieren.
Obwohl konfigurierbar, ist das System nicht für die Verwendung in Echtzeit konzipiert, zumindest nicht in Bezug auf das Training und die Kalibrierung. Derzeit benötigt GAN-Skizzieren 30.000 Trainingsiterationen. Das System benötigt auch den Zugriff auf die ursprünglichen Trainingsdaten für das ursprüngliche Modell.
In Fällen, in denen der Datensatz Open-Source ist und eine Lizenz hat, die das lokale Kopieren erlaubt, könnte dies durch die Aufnahme der Quelldaten in ein lokales Paket ermöglicht werden, obwohl dies erheblichen Festplattenspeicherplatz erfordern würde; oder durch den Zugriff auf oder die Verarbeitung von Daten remote, über einen cloud-basierten Ansatz, der Netzwerkoverheads und (im Falle der tatsächlichen Verarbeitung in der Cloud) möglicherweise Rechenkostenbedenken einführt.

Transformationen von benutzerdefinierten FFHQ-Modellen, die nur auf von Menschen erstellten Skizzen trainiert wurden.












