Künstliche Intelligenz
Enfabrica enthüllt Ethernet-basiertes Memory-Fabric, das AI-Inference im großen Maßstab neu definieren könnte
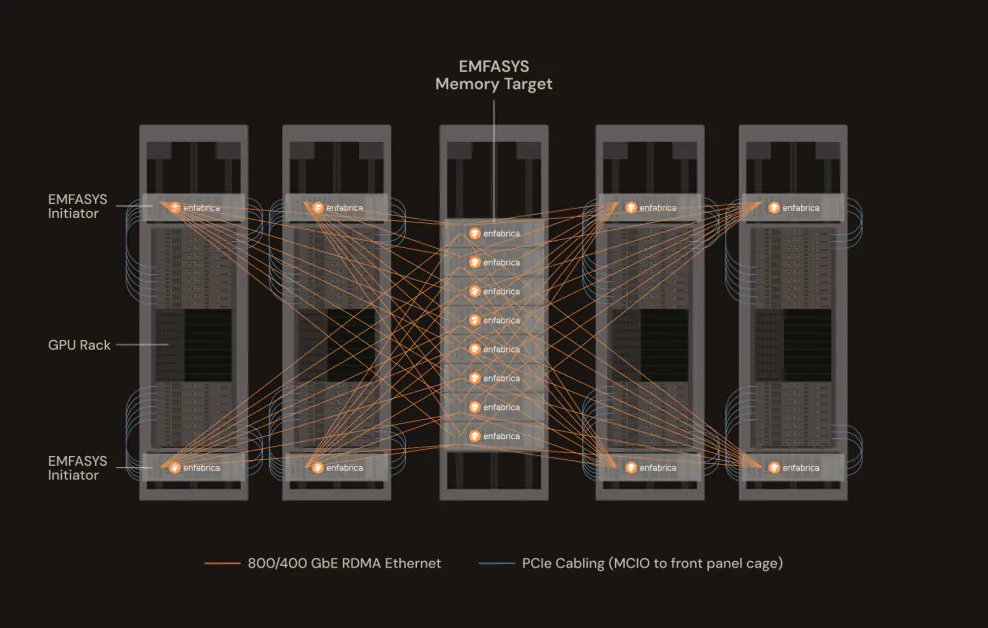
Enfabrica, ein in Silicon Valley ansässiges Startup, das von Nvidia unterstützt wird, hat ein bahnbrechendes Produkt vorgestellt, das die Art und Weise, wie große AI-Workloads bereitgestellt und skaliert werden, erheblich verändern könnte. Das neue Elastic Memory Fabric System (EMFASYS) von Enfabrica ist das erste kommerziell verfügbare Ethernet-basierte Memory-Fabric, das speziell dafür entwickelt wurde, den Kernflaschenhals der generativen AI-Inference zu adressieren: den Zugriff auf das Speichermedium.
In einer Zeit, in der AI-Modelle komplexer, kontextbewusster und persistenter werden und große Mengen an Speicher pro Benutzersitzung erfordern, bietet EMFASYS einen neuen Ansatz, um den Speicher von der Rechenleistung zu entkoppeln, sodass AI-Rechenzentren ihre Leistung erheblich verbessern, die Kosten senken und die Auslastung ihrer teuersten Ressourcen, der GPUs, erhöhen können.
Was ist ein Memory-Fabric – und warum ist es wichtig?
Traditionell war der Speicher in Rechenzentren eng an den Server oder Knoten gebunden, in dem er sich befand. Jeder GPU oder CPU hatte nur Zugriff auf den hochbandigen Speicher, der direkt an sie angeschlossen war – in der Regel HBM für GPUs oder DRAM für CPUs. Diese Architektur funktioniert gut, wenn die Workloads klein und vorhersehbar sind. Aber die generative AI hat das Spiel geändert. LLMs erfordern den Zugriff auf große Kontextfenster, Benutzerhistorie und Multi-Agenten-Speicher – all dies muss schnell und ohne Verzögerung verarbeitet werden. Diese Speicheranforderungen übersteigen oft die verfügbare Kapazität des lokalen Speichers, was Engpässe erzeugt, die GPU-Kerne blockieren und die Infrastrukturkosten in die Höhe treiben.
Ein Memory-Fabric löst dieses Problem, indem es den Speicher in eine gemeinsam genutzte, verteilte Ressource umwandelt – eine Art Netzwerk-attached-Speicherpool, der von jeder GPU oder CPU im Cluster zugänglich ist. Stellen Sie sich vor, Sie erstellen eine “Speicher-Wolke” innerhalb des Rechenzentrums-Racks. Anstatt den Speicher über Server zu replizieren oder teuren HBM zu überlasten, ermöglicht ein Fabric es, den Speicher zu aggregieren, zu disaggregieren und auf Abruf über ein Hochgeschwindigkeitsnetzwerk zuzugreifen. Dies ermöglicht es AI-Inference-Workloads, effizienter zu skalierten, ohne durch die physischen Speicherbegrenzungen eines einzelnen Knotens eingeschränkt zu sein.
Enfabricas Ansatz: Ethernet und CXL, endlich vereint
EMFASYS erreicht diese Rack-Speicher-Architektur, indem es zwei leistungsstarke Technologien kombiniert: RDMA über Ethernet und Compute Express Link (CXL). Erstere ermöglicht ultraniedrige Latenz, Hochdurchsatz-Datentransfer über Standard-Ethernet-Netzwerke. Letztere ermöglicht es, den Speicher von CPUs und GPUs zu trennen und in gemeinsam genutzte Ressourcen zu poolen, die über Hochgeschwindigkeits-CXL-Links zugänglich sind.
Im Kern von EMFASYS befindet sich Enfabricas ACF-S-Chip, ein 3,2-Terabit-pro-Sekunde-(Tbps)-“SuperNIC”, der Netzwerk- und Speichersteuerung in einem einzigen Gerät kombiniert. Dieser Chip ermöglicht es Servern, auf massive Speicher-Pools aus Commodity-DDR5-DRAM zuzugreifen – bis zu 18 Terabyte pro Knoten –, die über das Rack verteilt sind. Wesentlich ist, dass dies über Standard-Ethernet-Ports erfolgt, sodass Betreiber ihre bestehende Rechenzentrums-Infrastruktur nutzen können, ohne in proprietäre Interconnects investieren zu müssen.
Was EMFASYS besonders überzeugend macht, ist seine Fähigkeit, Speicher-begrenzte Workloads dynamisch von teurem GPU-angebundenen HBM auf viel günstigeren DRAM umzuleiten, während gleichzeitig Mikrosekunden-Latenz beibehalten wird. Die Software-Stack hinter EMFASYS umfasst intelligente Caching- und Lastausgleichsmechanismen, die Latenz verstecken und Speicherbewegungen auf eine Weise orchestrieren, die für die auf dem System laufenden LLMs transparent ist.
Auswirkungen auf die AI-Branche
Dies ist mehr als nur eine clevere Hardware-Lösung – es stellt eine philosophische Verschiebung dar, in der AI-Infrastruktur aufgebaut und skaliert wird. Wenn generative AI von einer Neuheit zu einer Notwendigkeit wird, mit Milliarden von Benutzeranfragen, die täglich verarbeitet werden, sind die Kosten für die Bereitstellung dieser Modelle für viele Unternehmen nicht mehr tragbar. GPUs werden oft nicht wegen mangelnder Rechenleistung, sondern weil sie untätig auf Speicher warten, unterausgelastet. EMFASYS adressiert diese Ungleichgewichtung direkt.
Indem Enfabrica einen gemeinsam genutzten, fabric-angebundenen Speicher über Ethernet ermöglicht, bietet das Unternehmen Rechenzentrums-Betreibern eine skalierbare Alternative, um ständig mehr GPUs oder HBM zu kaufen. Stattdessen können sie die Speicherkapazität modulartig erhöhen, indem sie Standard-DRAM und intelligente Netzwerke verwenden, was den Gesamtaufwand und die Wirtschaftlichkeit der AI-Inference verbessert.
Die Auswirkungen gehen über unmittelbare Kosteneinsparungen hinaus. Diese Art der disaggregierten Architektur ebnet den Weg für Speicher-as-a-Service-Modelle, bei denen Kontext, Historie und Agenten-Zustand über eine einzelne Sitzung oder Server hinaus bestehen bleiben können, was den Weg für intelligentere und personalisierte AI-Systeme ebnet. Es bereitet auch den Boden für widerstandsfähigere AI-Clouds, bei denen Workloads elastisch über ein Rack oder ein ganzes Rechenzentrum verteilt werden können, ohne dass es starre Speicherbegrenzungen gibt.
Ausblick
Enfabricas EMFASYS wird derzeit bei ausgewählten Kunden getestet, und obwohl das Unternehmen nicht preisgegeben hat, wer diese Partner sind, Reuters berichtet, dass große AI-Cloud-Anbieter das System bereits testen. Dies positioniert Enfabrica nicht nur als Komponenten-Lieferant, sondern auch als wichtiger Enabler in der nächsten Generation von AI-Infrastruktur.
Indem Enfabrica den Speicher von der Rechenleistung entkoppelt und ihn über Hochgeschwindigkeits-Commodity-Ethernet-Netzwerke verfügbar macht, legt das Unternehmen den Grundstein für eine neue Ära von AI-Architektur – eine, in der Inference ohne Kompromisse skaliert werden kann, in der Ressourcen nicht mehr gestrandet sind und in der die Wirtschaftlichkeit der Bereitstellung großer Sprachmodelle endlich Sinn ergibt.
In einer Welt, die zunehmend durch kontextreiche, multi-agenten-basierte AI-Systeme definiert wird, ist der Speicher nicht länger ein Nebendarsteller – er ist die Bühne. Und Enfabrica setzt darauf, dass wer die beste Bühne baut, die Leistung von AI für Jahre zu kommen definieren wird.










