Künstliche Intelligenz
Code-Einbettung: Eine umfassende Anleitung

Code-Embeddings sind eine transformative Möglichkeit, Code-Schnipsel als dichte Vektoren in einem kontinuierlichen Raum darzustellen. Diese Embeddings erfassen die semantischen und funktionalen Beziehungen zwischen Code-Schnipseln und ermöglichen so leistungsstarke Anwendungen in der KI-gestützten Programmierung. Ähnlich wie bei Word Embeddings in der Verarbeitung natürlicher Sprache (NLP) positionieren Code-Embeddings ähnliche Code-Schnipsel dicht beieinander im Vektorraum, sodass Maschinen Code effektiver verstehen und bearbeiten können.
Was sind Code-Einbettungen?
Code-Embeddings wandeln komplexe Codestrukturen in numerische Vektoren um, die die Bedeutung und Funktionalität des Codes erfassen. Im Gegensatz zu herkömmlichen Methoden, die Code als Zeichenfolgen behandeln, erfassen Embeddings die semantischen Beziehungen zwischen Codeteilen. Dies ist für verschiedene KI-gesteuerte Softwareentwicklungsaufgaben von entscheidender Bedeutung, z. B. Codesuche, Vervollständigung, Fehlererkennung und mehr.
Betrachten Sie beispielsweise diese beiden Python-Funktionen:
def add_numbers(a, b):
return a + b
def sum_two_values(x, y):
result = x + y
return result
Obwohl diese Funktionen syntaktisch unterschiedlich aussehen, führen sie dieselbe Operation aus. Eine gute Codeeinbettung würde diese beiden Funktionen mit ähnlichen Vektoren darstellen und so ihre funktionale Ähnlichkeit trotz ihrer textlichen Unterschiede erfassen.

Vektoreinbettung
Wie werden Code-Einbettungen erstellt?
Es gibt verschiedene Techniken zum Erstellen von Code-Einbettungen. Ein gängiger Ansatz besteht darin, neuronale Netzwerke zu verwenden, um diese Darstellungen aus einem großen Code-Datensatz zu lernen. Das Netzwerk analysiert die Codestruktur, einschließlich Token (Schlüsselwörter, Bezeichner), Syntax (wie der Code strukturiert ist) und möglicherweise Kommentare, um die Beziehungen zwischen verschiedenen Codeausschnitten zu lernen.
Lassen Sie uns den Prozess aufschlüsseln:
- Code als Sequenz: Zunächst werden Codefragmente als Token-Sequenzen (Variablen, Schlüsselwörter, Operatoren) behandelt.
- Neuronales Netztraining: Ein neuronales Netzwerk verarbeitet diese Sequenzen und lernt, sie auf Vektordarstellungen mit fester Größe abzubilden. Das Netzwerk berücksichtigt Faktoren wie Syntax, Semantik und Beziehungen zwischen Codeelementen.
- Ähnlichkeiten erfassen: Das Training zielt darauf ab, ähnliche Codeausschnitte (mit ähnlicher Funktionalität) nahe beieinander im Vektorraum zu positionieren. Dies ermöglicht Aufgaben wie das Finden von ähnlichem Code oder das Vergleichen von Funktionalitäten.
Hier ist ein vereinfachtes Python-Beispiel, wie Sie Code zum Einbetten vorverarbeiten können:
import ast
def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Add more node types as needed
return tokens
# Example usage
code = """
def greet(name):
print("Hello, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
Diese tokenisierte Darstellung kann dann zur Einbettung in ein neuronales Netzwerk eingespeist werden.
Bestehende Ansätze zur Code-Einbettung
Vorhandene Methoden zur Code-Einbettung können in drei Hauptkategorien eingeteilt werden:
Tokenbasierte Methoden
Tokenbasierte Methoden behandeln Code als eine Folge von lexikalischen Token. Techniken wie Term Frequency-Inverse Document Frequency (TF-IDF) und Deep-Learning-Modelle wie CodeBERT in diese Kategorie fallen.
Baumbasierte Methoden
Baumbasierte Methoden zerlegen Code in abstrakte Syntaxbäume (ASTs) oder andere Baumstrukturen und erfassen dabei die syntaktischen und semantischen Regeln des Codes. Beispiele hierfür sind baumbasierte neuronale Netzwerke und Modelle wie code2vec und ASTNN.
Graphenbasierte Methoden
Graphenbasierte Methoden konstruieren Graphen aus Code, wie etwa Kontrollflussgraphen (CFGs) und Datenflussgraphen (DFGs), um das dynamische Verhalten und die Abhängigkeiten des Codes darzustellen. GraphCodeBERT ist ein bemerkenswertes Beispiel.
TransformCode: Ein Framework zum Einbetten von Code
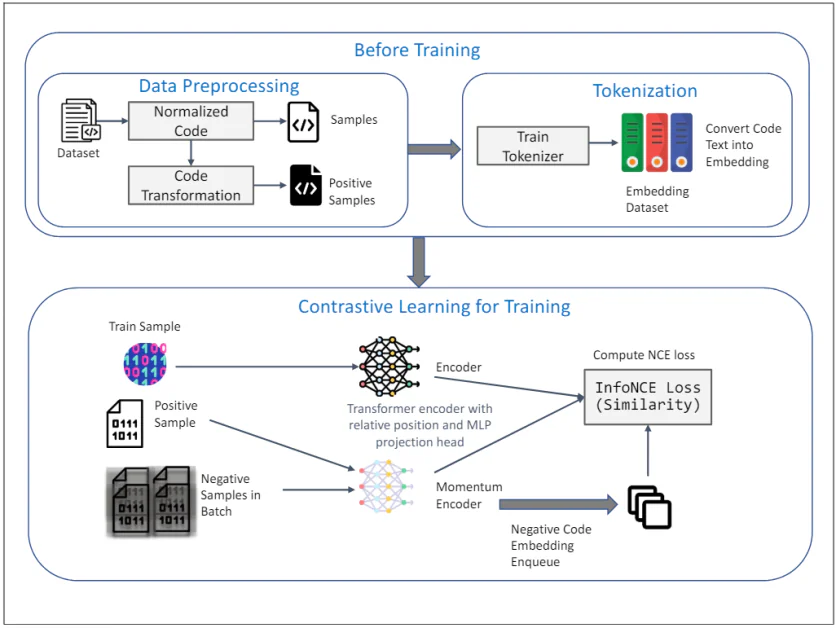
TransformCode: Unüberwachtes Lernen der Code-Einbettung
TransformCode ist ein Framework, das die Einschränkungen bestehender Methoden behebt, indem es Code-Einbettungen in einer kontrastiven Lernmethode lernt. Es ist codierer- und sprachunabhängig, d. h. es kann jedes Codierermodell nutzen und jede Programmiersprache verarbeiten.
Das obige Diagramm veranschaulicht das Framework von TransformCode für unüberwachtes Lernen von Code-Einbettungen mithilfe von kontrastivem Lernen. Es besteht aus zwei Hauptphasen: Vor dem Training und Kontrastives Lernen für das Training. Hier ist eine detaillierte Erklärung der einzelnen Komponenten:
Vor dem Training
1. Datenvorverarbeitung:
- Datensatz: Die anfängliche Eingabe ist ein Datensatz, der Codeausschnitte enthält.
- Normalisierter Code: Die Codeausschnitte werden normalisiert, um Kommentare zu entfernen und Variablen in ein Standardformat umzubenennen. Dies trägt dazu bei, den Einfluss der Variablenbenennung auf den Lernprozess zu verringern und die Generalisierbarkeit des Modells zu verbessern.
- Code-Transformation: Der normalisierte Code wird dann mithilfe verschiedener syntaktischer und semantischer Transformationen transformiert, um positive Beispiele zu generieren. Diese Transformationen stellen sicher, dass die semantische Bedeutung des Codes unverändert bleibt, und bieten vielfältige und robuste Beispiele für kontrastives Lernen.
2. Tokenisierung:
- Zug-Tokenizer: Ein Tokenizer wird anhand des Codedatensatzes trainiert, um Codetext in Einbettungen umzuwandeln. Dabei wird der Code in kleinere Einheiten, z. B. Token, zerlegt, die vom Modell verarbeitet werden können.
- Einbettender Datensatz: Der trainierte Tokenizer wird verwendet, um den gesamten Code-Datensatz in Einbettungen umzuwandeln, die als Eingabe für die kontrastive Lernphase dienen.
Kontrastives Lernen für das Training
3. Trainingsprozess:
- Trainingsbeispiel: Als Darstellung des Abfragecodes wird eine Stichprobe aus dem Trainingsdatensatz ausgewählt.
- Positive Probe: Die entsprechende positive Probe ist die transformierte Version des Abfragecodes, die während der Datenvorverarbeitungsphase erhalten wurde.
- Negative Proben im Batch: Negative Beispiele sind alle anderen Codebeispiele im aktuellen Mini-Batch, die sich vom positiven Beispiel unterscheiden.
4. Encoder und Momentum-Encoder:
- Transformator-Encoder mit relativer Position und MLP-Projektionskopf: Sowohl die Abfrage als auch die positiven Beispiele werden in einen Transformer-Encoder eingespeist. Der Encoder enthält eine relative Positionscodierung, um die syntaktische Struktur und die Beziehungen zwischen Token im Code zu erfassen. Ein MLP-Projektionskopf (Multi-Layer Perceptron) wird verwendet, um die codierten Darstellungen in einen Raum mit niedrigerer Dimension abzubilden, in dem das kontrastive Lernziel angewendet wird.
- Impulsgeber: Außerdem wird ein Momentum-Encoder verwendet, der durch einen gleitenden Durchschnitt der Parameter des Abfrage-Encoders aktualisiert wird. Dies trägt dazu bei, die Konsistenz und Vielfalt der Darstellungen zu erhalten und den Zusammenbruch des Kontrastverlusts zu verhindern. Die negativen Samples werden mit diesem Momentum-Encoder kodiert und für den kontrastiven Lernprozess in die Warteschlange gestellt.
5. Kontrastives Lernziel:
- InfoNCE-Verlust berechnen (Ähnlichkeit): Die InfoNCE-Verlust (Noise Contrastive Estimation) wird berechnet, um die Ähnlichkeit zwischen der Abfrage und den positiven Beispielen zu maximieren und gleichzeitig die Ähnlichkeit zwischen der Abfrage und den negativen Beispielen zu minimieren. Dieses Ziel stellt sicher, dass die gelernten Einbettungen diskriminativ und robust sind und die semantische Ähnlichkeit der Codeausschnitte erfassen.
Das gesamte Framework nutzt die Stärken des kontrastiven Lernens, um aussagekräftige und robuste Code-Einbettungen aus nicht gekennzeichneten Daten zu lernen. Die Verwendung von AST-Transformationen und eines Momentum-Encoders verbessert die Qualität und Effizienz der gelernten Darstellungen weiter und macht TransformCode zu einem leistungsstarken Werkzeug für verschiedene Softwareentwicklungsaufgaben.
Hauptfunktionen von TransformCode
- Flexibilität und Anpassungsfähigkeit: Kann auf verschiedene nachgelagerte Aufgaben erweitert werden, die eine Codedarstellung erfordern.
- Effizienz und Skalierbarkeit: Erfordert kein großes Modell oder umfangreiche Trainingsdaten und unterstützt jede Programmiersprache.
- Unüberwachtes und überwachtes Lernen: Kann auf beide Lernszenarien angewendet werden, indem aufgabenspezifische Bezeichnungen oder Ziele integriert werden.
- Einstellbare Parameter: Die Anzahl der Encoderparameter kann basierend auf den verfügbaren Rechenressourcen angepasst werden.
TransformCode führt eine Datenerweiterungstechnik namens AST-Transformation ein, bei der syntaktische und semantische Transformationen auf die ursprünglichen Codeausschnitte angewendet werden. Dadurch werden vielfältige und robuste Beispiele für kontrastives Lernen generiert.
Anwendungen von Code-Einbettungen
Code-Einbettungen haben verschiedene Aspekte der Softwareentwicklung revolutioniert, indem sie Code von einem Textformat in eine numerische Darstellung umwandeln, die von Modellen des maschinellen Lernens verwendet werden kann. Hier sind einige wichtige Anwendungen:
Verbesserte Codesuche
Traditionell beruhte die Codesuche auf der Übereinstimmung von Schlüsselwörtern, was häufig zu irrelevanten Ergebnissen führte. Code-Einbettungen ermöglichen eine semantische Suche, bei der Codeausschnitte anhand ihrer Ähnlichkeit in der Funktionalität bewertet werden, selbst wenn sie unterschiedliche Schlüsselwörter verwenden. Dies verbessert die Genauigkeit und Effizienz beim Auffinden von relevantem Code in großen Codebasen erheblich.
Intelligentere Code-Vervollständigung
Tools zur Codevervollständigung schlagen relevante Codeausschnitte basierend auf dem aktuellen Kontext vor. Durch die Nutzung von Codeeinbettungen können diese Tools genauere und hilfreichere Vorschläge liefern, indem sie die semantische Bedeutung des geschriebenen Codes verstehen. Dies führt zu schnelleren und produktiveren Codierungserlebnissen.
Automatisierte Codekorrektur und Fehlererkennung
Code-Einbettungen können verwendet werden, um Muster zu identifizieren, die häufig auf Fehler oder Ineffizienzen im Code hinweisen. Durch die Analyse der Ähnlichkeit zwischen Codeausschnitten und bekannten Fehlermustern können diese Systeme automatisch Korrekturen vorschlagen oder Bereiche hervorheben, die möglicherweise einer weiteren Überprüfung bedürfen.
Verbesserte Codezusammenfassung und Dokumentationserstellung
In großen Codebasen fehlt oft die richtige Dokumentation, was es für neue Entwickler schwierig macht, ihre Funktionsweise zu verstehen. Code-Einbettungen können prägnante Zusammenfassungen erstellen, die das Wesentliche der Funktionalität des Codes erfassen. Dies verbessert nicht nur die Wartbarkeit des Codes, sondern erleichtert auch den Wissenstransfer innerhalb der Entwicklungsteams.
Verbesserte Codeüberprüfungen
Codeüberprüfungen sind für die Aufrechterhaltung der Codequalität von entscheidender Bedeutung. Codeeinbettungen können Prüfer unterstützen, indem sie potenzielle Probleme hervorheben und Verbesserungen vorschlagen. Darüber hinaus können sie den Vergleich zwischen verschiedenen Codeversionen erleichtern und so den Prüfprozess effizienter gestalten.
Sprachenübergreifende Codeverarbeitung
Die Welt der Softwareentwicklung ist nicht auf eine einzige Programmiersprache beschränkt. Code-Einbettungen sind vielversprechend, um sprachenübergreifende Codeverarbeitungsaufgaben zu erleichtern. Durch die Erfassung der semantischen Beziehungen zwischen in verschiedenen Sprachen geschriebenem Code könnten diese Techniken Aufgaben wie die Codesuche und -analyse über Programmiersprachen hinweg ermöglichen.












