Künstliche Intelligenz
ChatGPTs erstes Jubiläum: Die Zukunft der AI-Interaktion neu gestalten

Wenn man auf ChatGPTs erstes Jahr zurückblickt, ist klar, dass dieses Tool die AI-Szene erheblich verändert hat. Ende 2022 gestartet, hob sich ChatGPT durch seinen benutzerfreundlichen, konversationellen Stil hervor, der das Interagieren mit AI mehr wie ein Gespräch mit einer Person als mit einer Maschine erscheinen ließ. Dieser neue Ansatz erregte schnell die Aufmerksamkeit der Öffentlichkeit. Bereits fünf Tage nach seiner Veröffentlichung hatte ChatGPT eine Million Nutzer angezogen. Anfang 2023 belief sich diese Zahl auf etwa 100 Millionen monatliche Nutzer, und bis Oktober zog die Plattform weltweit etwa 1,7 Milliarden Besuche an. Diese Zahlen sprechen Bände über ihre Popularität und Nützlichkeit.
Im Laufe des letzten Jahres haben Nutzer ChatGPT auf alle möglichen kreativen Weisen genutzt, von einfachen Aufgaben wie dem Schreiben von E-Mails und dem Aktualisieren von Lebensläufen bis hin zum Starten erfolgreicher Unternehmen. Aber es geht nicht nur darum, wie die Menschen es nutzen; die Technologie selbst ist gewachsen und verbessert worden. Anfangs war ChatGPT ein kostenloser Service, der detaillierte Textantworten bot. Jetzt gibt es ChatGPT Plus, das ChatGPT-4 enthält. Diese aktualisierte Version wurde mit mehr Daten trainiert, gibt weniger falsche Antworten und versteht komplexe Anweisungen besser.
Eine der größten Updates ist, dass ChatGPT jetzt auf mehrere Arten interagieren kann – es kann zuhören, sprechen und sogar Bilder verarbeiten. Das bedeutet, dass Sie mit ihm über seine Mobile-App sprechen und ihm Bilder zeigen können, um Antworten zu erhalten. Diese Änderungen haben neue Möglichkeiten für AI eröffnet und haben geändert, wie Menschen über die Rolle von AI in unserem Leben denken.
Von seinen Anfängen als Tech-Demo bis zu seinem aktuellen Status als wichtiger Spieler in der Tech-Welt ist ChatGPTs Reise ziemlich beeindruckend. Anfangs wurde es als Möglichkeit gesehen, Technologie zu testen und zu verbessern, indem man Feedback von der Öffentlichkeit erhielt. Aber es wurde schnell zu einem wesentlichen Teil der AI-Landschaft. Dieser Erfolg zeigt, wie effektiv es ist, große Sprachmodelle (LLMs) mit sowohl überwachtem Lernen als auch Feedback von Menschen fein zu justieren. Als Ergebnis kann ChatGPT eine breite Palette von Fragen und Aufgaben bewältigen.
Der Wettlauf, die leistungsfähigsten und vielseitigsten AI-Systeme zu entwickeln, hat zu einer Vielzahl von Open-Source- und proprietären Modellen wie ChatGPT geführt. Um ihre allgemeinen Fähigkeiten zu verstehen, sind umfassende Benchmarks über eine breite Palette von Aufgaben erforderlich. Dieser Abschnitt untersucht diese Benchmarks und wirft Licht darauf, wie sich unterschiedliche Modelle, einschließlich ChatGPT, gegenüber anderen behaupten.
Bewertung von LLMs: Die Benchmarks
- MT-Bench: Diese Benchmark testet die Fähigkeit zu mehrstufigen Konversationen und Anweisungsfolgen in acht Bereichen: Schreiben, Rollenspiel, Informationsextraktion, Argumentation, Mathematik, Codierung, STEM-Wissen und Geistes- und Sozialwissenschaften. Stärkere LLMs wie GPT-4 werden als Evaluatoren verwendet.
- AlpacaEval: Basierend auf dem AlpacaFarm-Evaluierungssatz benchmarket dieser LLM-basierte automatische Evaluierer Modelle gegen Antworten von fortschrittlichen LLMs wie GPT-4 und Claude, indem er die Gewinnrate der Kandidatenmodelle berechnet.
- Open LLM Leaderboard: Mit Hilfe des Language Model Evaluation Harness bewertet diese Leaderboard LLMs anhand von sieben Schlüsselbenchmarks, einschließlich Argumentationsherausforderungen und allgemeinen Wissens-tests, in sowohl Zero-Shot- als auch Few-Shot-Szenarien.
- BIG-bench: Diese kollaborative Benchmark deckt über 200 neue Sprachaufgaben ab, die eine Vielzahl von Themen und Sprachen umfassen. Sie zielt darauf ab, LLMs zu testen und ihre zukünftigen Fähigkeiten vorherzusagen.
- ChatEval: Ein Multi-Agent-Debatt-Frame, der es Teams ermöglicht, autonom zu diskutieren und die Qualität von Antworten aus verschiedenen Modellen auf offene Fragen und traditionelle Aufgaben der natürlichen Sprachgenerierung zu bewerten.
Vergleichbare Leistung
In Bezug auf allgemeine Benchmarks haben Open-Source-LLMs bemerkenswerte Fortschritte gezeigt. Llama-2-70B, zum Beispiel, erzielte beeindruckende Ergebnisse, insbesondere nach der Feinabstimmung mit Anweisungsdaten. Seine Variante, Llama-2-chat-70B, übertraf in AlpacaEval mit einer Gewinnrate von 92,66 % GPT-3.5-turbo. Allerdings bleibt GPT-4 mit einer Gewinnrate von 95,28 % der Spitzenreiter.
Zephyr-7B, ein kleineres Modell, zeigte Fähigkeiten, die mit denen größerer 70B-LLMs vergleichbar sind, insbesondere in AlpacaEval und MT-Bench. Währenddessen erzielte WizardLM-70B, das mit einer Vielzahl von Anweisungsdaten fein abgestimmt wurde, die höchste Punktzahl unter den Open-Source-LLMs in MT-Bench. Es lag jedoch immer noch hinter GPT-3.5-turbo und GPT-4 zurück.
Ein interessanter Eintrag, GodziLLa2-70B, erreichte einen wettbewerbsfähigen Punktestand auf der Open LLM Leaderboard, was die Potenziale von experimentellen Modellen unterstreicht, die diverse Datensätze kombinieren. Ähnlich dazu zeigte Yi-34B, das von Grund auf entwickelt wurde, Punktzahlen, die mit denen von GPT-3.5-turbo vergleichbar sind und nur leicht unter denen von GPT-4 liegen.
UltraLlama, das mit vielfältigen und hochwertigen Daten fein abgestimmt wurde, erreichte GPT-3.5-turbo in den vorgeschlagenen Benchmarks und übertraf es sogar in Bereichen des Welt- und Fachwissens.
Skalierung: Der Aufstieg der Riesen-LLMs
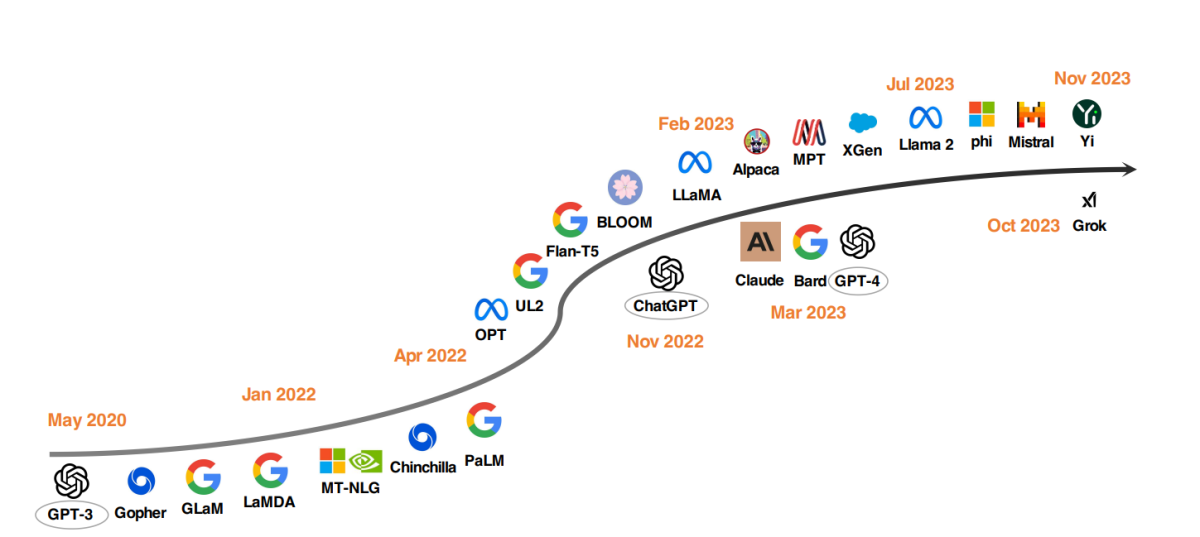
Top-LLM-Modelle seit 2020
Ein bemerkenswerter Trend in der LLM-Entwicklung ist die Skalierung der Modellparameter. Modelle wie Gopher, GLaM, LaMDA, MT-NLG und PaLM haben die Grenzen ausgedehnt, was zu Modellen mit bis zu 540 Milliarden Parametern geführt hat. Diese Modelle haben außergewöhnliche Fähigkeiten gezeigt, aber ihre geschlossene Natur hat ihre breitere Anwendung begrenzt. Diese Einschränkung hat das Interesse an der Entwicklung von Open-Source-LLMs geweckt, ein Trend, der an Fahrt gewinnt.
Parallel zur Skalierung der Modellgrößen haben Forscher alternative Strategien erforscht. Anstatt einfach größere Modelle zu erstellen, haben sie sich auf die Verbesserung der Vorbereitung kleinerer Modelle konzentriert. Beispiele hierfür sind Chinchilla und UL2, die gezeigt haben, dass mehr nicht immer besser ist; intelligente Strategien können effiziente Ergebnisse liefern. Darüber hinaus gab es erhebliche Aufmerksamkeit für die Anweisungsfeinabstimmung von Sprachmodellen, mit Projekten wie FLAN, T0 und Flan-T5, die wesentliche Beiträge zu diesem Bereich geleistet haben.
Der ChatGPT-Katalysator
Die Einführung von OpenAIs ChatGPT markierte einen Wendepunkt in der NLP-Forschung. Um mit OpenAI zu konkurrieren, starteten Unternehmen wie Google und Anthropic ihre eigenen Modelle, Bard und Claude. Während diese Modelle in vielen Aufgaben eine vergleichbare Leistung wie ChatGPT zeigen, bleiben sie hinter dem neuesten Modell von OpenAI, GPT-4, zurück. Der Erfolg dieser Modelle wird hauptsächlich der Technik des Reinforcement Learning mit menschlichem Feedback (RLHF) zugeschrieben, einer Technik, die zunehmend im Fokus der Forschung für weitere Verbesserungen steht.
Gerüchte und Spekulationen um OpenAIs Q* (Q-Stern)
Aktuelle Berichte deuten darauf hin, dass Forscher bei OpenAI möglicherweise einen bedeutenden Durchbruch in der KI-Entwicklung mit der Entwicklung eines neuen Modells namens Q* (ausgesprochen Q-Stern) erzielt haben. Angeblich verfügt Q* über die Fähigkeit, Rechenaufgaben auf Grundschulniveau zu lösen, was unter Experten Diskussionen über sein Potenzial als Meilenstein auf dem Weg zur künstlichen allgemeinen Intelligenz (AGI) ausgelöst hat. Während OpenAI zu diesen Berichten keine Stellung genommen hat, haben die vermuteten Fähigkeiten von Q* erhebliche Aufregung und Spekulationen in sozialen Medien und unter KI-Enthusiasten ausgelöst.
Die Entwicklung von Q* ist bemerkenswert, weil bestehende Sprachmodelle wie ChatGPT und GPT-4, obwohl sie einige mathematische Aufgaben lösen können, nicht besonders gut darin sind, dies zuverlässig zu tun. Die Herausforderung liegt darin, dass AI-Modelle nicht nur Muster erkennen müssen, wie sie es derzeit durch Deep Learning und Transformer tun, sondern auch argumentieren und abstrakte Konzepte verstehen müssen. Mathematik, als Benchmark für Argumentationsfähigkeit, erfordert, dass die AI plant und mehrere Schritte ausführt, was ein tiefes Verständnis abstrakter Konzepte demonstriert. Diese Fähigkeit würde einen bedeutenden Sprung in den AI-Fähigkeiten markieren, der möglicherweise über Mathematik hinausgeht und sich auf andere komplexe Aufgaben erstreckt.
Experten warnen jedoch davor, diese Entwicklung zu überbewerten. Während ein AI-System, das zuverlässig mathematische Probleme löst, eine beeindruckende Leistung wäre, bedeutet es nicht unbedingt den Beginn der Superintelligenz oder der AGI. Die derzeitige KI-Forschung, einschließlich der Bemühungen von OpenAI, hat sich auf elementare Probleme konzentriert, mit unterschiedlichem Erfolg in komplexeren Aufgaben.
Die potenziellen Anwendungen von Fortschritten wie Q* sind vielfältig, von personalisiertem Unterricht bis hin zur Unterstützung in wissenschaftlicher Forschung und Ingenieurwesen. Es ist jedoch wichtig, Erwartungen zu managen und die Einschränkungen und Sicherheitsbedenken im Zusammenhang mit solchen Fortschritten zu erkennen. Die Bedenken hinsichtlich der Existenzrisiken durch KI, ein grundlegendes Anliegen von OpenAI, bleiben relevant, insbesondere wenn KI-Systeme beginnen, stärker mit der realen Welt zu interagieren.
Die Open-Source-LLM-Bewegung
Um die Open-Source-LLM-Forschung zu fördern, veröffentlichte Meta die Llama-Serie-Modelle, was eine Welle neuer Entwicklungen auf der Grundlage von Llama auslöste. Dazu gehören Modelle, die mit Anweisungsdaten fein abgestimmt wurden, wie Alpaca, Vicuna, Lima und WizardLM. Die Forschung erstreckt sich auch auf die Verbesserung der Agentenfähigkeiten, der logischen Argumentation und der Langkontextmodellierung im Rahmen des Llama-basierten Frameworks.
Darüber hinaus gibt es einen wachsenden Trend, leistungsstarke LLMs von Grund auf zu entwickeln, mit Projekten wie MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok und Yi. Diese Bemühungen spiegeln das Engagement wider, die Fähigkeiten geschlossener LLMs zu demokratisieren und fortgeschrittene AI-Tools zugänglicher und effizienter zu machen.
Auswirkungen von ChatGPT und Open-Source-Modellen im Gesundheitswesen
Wir blicken auf eine Zukunft, in der LLMs bei der klinischen Notiznahme, der Formularausfüllung für Erstattungen und der Unterstützung von Ärzten bei der Diagnose und Behandlungsplanung helfen. Dies hat die Aufmerksamkeit von Tech-Giganten und Gesundheitseinrichtungen auf sich gezogen.
Microsofts Gespräche mit Epic, einem führenden Anbieter von Software für elektronische Gesundheitsakten, signalisieren die Integration von LLMs in das Gesundheitswesen. Initiativen sind bereits an der UC San Diego Health und der Stanford University Medical Center im Gange. Ähnlich dazu markieren Googles Partnerschaften mit der Mayo-Klinik und der Start von HealthScribe, einem AI-Klinikkodierdienst von Amazon Web Services, bedeutende Schritte in diese Richtung.
Allerdings werfen diese schnellen Bereitstellungen Bedenken hinsichtlich der Abtretung der Kontrolle über die Medizin an Unternehmensinteressen auf. Die proprietäre Natur dieser LLMs macht es schwierig, sie zu bewerten. Ihre mögliche Modifizierung oder Einstellung aus Gründen der Profitabilität könnte die Patientenversorgung, Privatsphäre und Sicherheit gefährden.
Der dringende Bedarf besteht in einem offenen und inklusiven Ansatz für die Entwicklung von LLMs im Gesundheitswesen. Gesundheitseinrichtungen, Forscher, Kliniker und Patienten müssen global zusammenarbeiten, um Open-Source-LLMs für das Gesundheitswesen zu entwickeln. Dieser Ansatz, ähnlich dem Trillion Parameter Consortium, würde es ermöglichen, Rechen-, Finanz- und Fachressourcen zu bündeln.












