Künstliche Intelligenz
Adobe Research erweitert die entwirrte GAN-Gesichtsbearbeitung

Es ist nicht schwer zu verstehen, warum Verschränkung ist ein Problem bei der Bildsynthese, weil es auch in anderen Lebensbereichen oft ein Problem ist. So ist es beispielsweise viel schwieriger, Kurkuma aus einem Curry zu entfernen, als die Gewürzgurke aus einem Burger zu entfernen, und es ist praktisch unmöglich, eine Tasse Kaffee zu entsüßen. Manche Dinge kommen einfach gebündelt.
Ebenso ist die Verschränkung ein Stolperstein für Bildsynthesearchitekturen, die im Idealfall verschiedene Merkmale und Konzepte trennen möchten, wenn sie maschinelles Lernen zum Erstellen oder Bearbeiten von Gesichtern (bzw Hunde, Boote, oder eine andere Domain).
Wenn Sie Stränge trennen könnten, z Alter, Geschlecht, Haarfarbe, Hautfarbe, Emotionusw. hätten Sie den Anfang echter Instrumentalität und Flexibilität in einem Framework, das Gesichtsbilder auf einer wirklich granularen Ebene erstellen und bearbeiten könnte, ohne unerwünschte „Passagiere“ in diese Konvertierungen hineinzuziehen.

Bei maximaler Verschränkung (oben links) können Sie nur das Bild eines erlernten GAN-Netzwerks in das Bild einer anderen Person ändern.
Dabei wird effektiv die neueste KI-Computer-Vision-Technologie genutzt, um etwas zu erreichen, das mit anderen Mitteln gelöst werden konnte vor über dreißig Jahren.
Mit einem gewissen Grad an Trennung („Mittlere Trennung“ im obigen Bild) ist es möglich, stilbasierte Änderungen wie Haarfarbe, Ausdruck, kosmetische Anwendung und begrenzte Kopfdrehung usw. vorzunehmen.

Quelle: FEAT: Gesichtsbearbeitung mit Aufmerksamkeit, Februar 2022, https://arxiv.org/pdf/2202.02713.pdf
In den letzten zwei Jahren gab es eine Reihe von Versuchen, interaktive Gesichtsbearbeitungsumgebungen zu erstellen, die es einem Benutzer ermöglichen, Gesichtsmerkmale mit Schiebereglern und anderen herkömmlichen UI-Interaktionen zu ändern, während die Kernfunktionen des Zielgesichts bei Ergänzungen oder Änderungen erhalten bleiben. Dies hat sich jedoch aufgrund der zugrunde liegenden Merkmals-/Stilverschränkung im latenten Raum des GAN als Herausforderung erwiesen.
Zum Beispiel kann die Brille Merkmal ist häufig mit dem verknüpft alt Merkmal, was bedeutet, dass das Hinzufügen einer Brille das Gesicht auch „älter“ machen kann, während das Altern des Gesichts je nach Grad der angewendeten Trennung der Merkmale auf hoher Ebene eine Brille hinzufügen kann (Beispiele finden Sie unten unter „Testen“).
Insbesondere war es fast unmöglich, die Haarfarbe und andere Haarfacetten zu ändern, ohne dass die Haarsträhnen und die Anordnung neu berechnet wurden, was einen „knisternden“ Übergangseffekt erzeugt.

Quelle: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Latent-zu-Latent-GAN-Traversal
Ein neues von Adobe geleitetes Papier eingegeben for WACV 2022 bietet einen neuartigen Ansatz für diese zugrunde liegenden Probleme in a Krepppapier berechtigt Latent zu Latent: Ein erlernter Mapper für die identitätserhaltende Bearbeitung mehrerer Gesichtsattribute in StyleGAN-generierten Bildern.

Ergänzendes Material aus der Arbeit Latent zu Latent: Ein erlernter Mapper für die identitätserhaltende Bearbeitung mehrerer Gesichtsattribute in StyleGAN-generierten Bildern. Hier sehen wir, dass grundlegende Merkmale im erlernten Gesicht nicht in unabhängige Änderungen hineingezogen werden. Weitere Details und Auflösung finden Sie im eingebetteten vollständigen Video am Ende des Artikels. Quelle: https://www.youtube.com/watch?v=rf_61llRH0Q
Das Papier wird von Adobe Applied Scientist Siavash Khodadadeh zusammen mit vier weiteren Adobe-Forschern und einem Forscher vom Department of Computer Science der University of Central Florida geleitet.
Der Artikel ist zum einen deshalb interessant, weil Adobe schon seit einiger Zeit in diesem Bereich tätig ist und man sich vorstellen kann, dass diese Funktionalität in den nächsten Jahren in ein Creative Suite-Projekt aufgenommen wird. Zum anderen ist er vor allem deshalb interessant, weil die für das Projekt erstellte Architektur einen anderen Ansatz zur Aufrechterhaltung der visuellen Integrität in einem GAN-Gesichtseditor verfolgt, während Änderungen vorgenommen werden.
Die Autoren erklären:
„[Wir] trainieren ein neuronales Netzwerk, um eine Latent-zu-Latent-Transformation durchzuführen, die die latente Kodierung findet, die dem Bild mit dem geänderten Attribut entspricht.“ Da es sich bei der Technik um eine One-Shot-Technik handelt, ist sie nicht auf eine lineare oder nichtlineare Verlaufskurve der allmählichen Änderung der Attribute angewiesen.
„Durch das durchgehende Training des Netzwerks über die gesamte Erzeugungspipeline kann sich das System an die latenten Räume handelsüblicher Generatorarchitekturen anpassen.“ Erhaltungseigenschaften, wie etwa die Wahrung der Identität der Person, können in Form von Ausbildungsverlusten kodiert werden.
„Sobald das Latent-to-Latent-Netzwerk trainiert wurde, kann es ohne erneutes Training für beliebige Bilder wiederverwendet werden.“
Dieser letzte Teil bedeutet, dass die vorgeschlagene Architektur dem Endbenutzer in einem fertigen Zustand zur Verfügung steht. Es muss zwar weiterhin ein neuronales Netzwerk auf lokalen Ressourcen ausführen, aber neue Bilder können „eingefügt“ werden und stehen fast sofort zur Bearbeitung bereit, da das Framework ausreichend entkoppelt ist, um kein weiteres bildspezifisches Training zu benötigen.
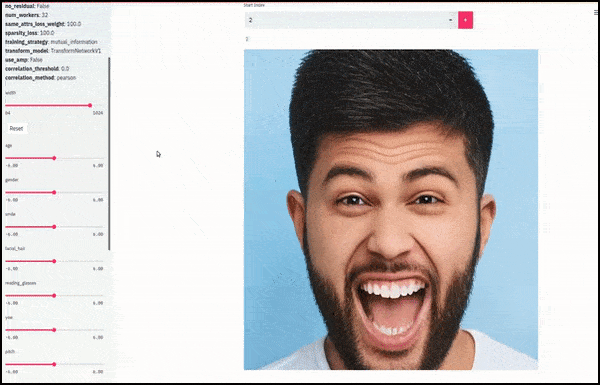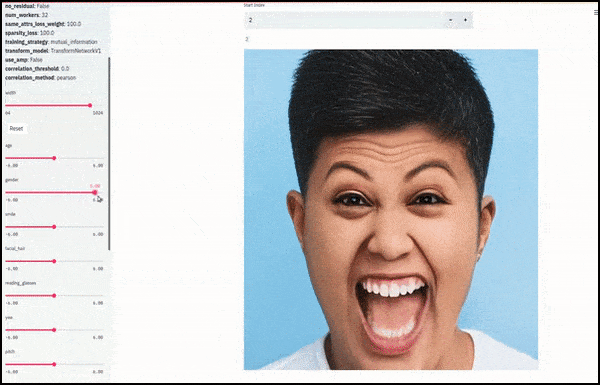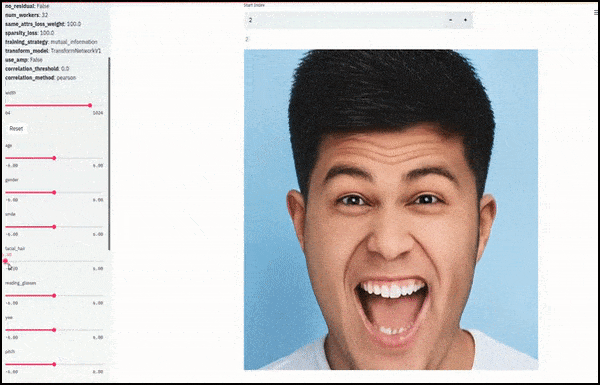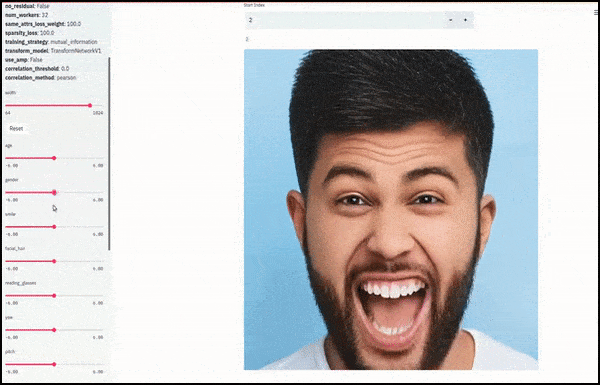
Geschlecht und Gesichtsbehaarung veränderten sich, als die Schieberegler zufällige und willkürliche Pfade durch den latenten Raum zeichneten und nicht nur zwischen Endpunkten schoben. Weitere Transformationen in besserer Auflösung finden Sie im eingebetteten Video am Ende des Artikels.
Zu den wichtigsten Errungenschaften der Arbeit gehört die Fähigkeit des Netzwerks, Identitäten im latenten Raum „einzufrieren“, indem nur das Attribut in einem Zielvektor geändert wird, und „Korrekturterme“ bereitzustellen, die die transformierten Identitäten erhalten.
Im Wesentlichen ist das vorgeschlagene Netzwerk in eine breitere Architektur eingebettet, die alle verarbeiteten Elemente orchestriert, die durch vorab trainierte Komponenten mit eingefrorenen Gewichten laufen, die keine unerwünschten seitlichen Auswirkungen auf Transformationen haben.
Da der Trainingsprozess darauf angewiesen ist Dreiergruppen das entweder durch ein Seed-Image (unter GAN-Inversion) oder einer vorhandenen anfänglichen latenten Codierung erfolgt der gesamte Trainingsprozess unbeaufsichtigt, wobei die stillschweigenden Aktionen der üblichen Reihe von Kennzeichnungs- und Kurationssystemen in solchen Systemen effektiv in die Architektur integriert sind. Tatsächlich verwendet das neue System handelsübliche Attributregressoren:
„[Die] Anzahl der Attribute, die unser Netzwerk unabhängig steuern kann, ist nur durch die Fähigkeiten des/der Erkenners/Erkenner begrenzt – wenn man einen Erkenner für ein Attribut hat, können wir es beliebigen Gesichtern hinzufügen. In unseren Experimenten haben wir das Latent-to-Latent-Netzwerk so trainiert, dass es die Anpassung von 35 verschiedenen Gesichtsmerkmalen ermöglicht, mehr als jeder bisherige Ansatz.“
Das System enthält einen zusätzlichen Schutz gegen unerwünschte Transformationen mit Nebeneffekten: Wenn keine Anforderung für eine Attributänderung vorliegt, bildet das Latent-to-Latent-Netzwerk einen latenten Vektor auf sich selbst ab, wodurch die stabile Persistenz der Zielidentität weiter erhöht wird.
Gesichtserkennung
Ein in den letzten Jahren immer wieder auftretendes Problem bei GAN- und Encoder/Decoder-basierten Gesichtseditoren war, dass angewandte Transformationen dazu neigen, die Ähnlichkeit zu verringern. Um dem entgegenzuwirken, nutzt das Adobe-Projekt ein eingebettetes Gesichtserkennungsnetzwerk namens FaceNet als Diskriminator.

Projektarchitektur, siehe unten in der Mitte links zur Einbeziehung von FaceNet. Quelle: Latent zu Latent: Ein erlernter Mapper für die identitätserhaltende Bearbeitung mehrerer Gesichtsattribute in StyleGAN-generierten Bildern, Uneingeschränkter Zugang.
(Persönlich gesehen scheint dies ein ermutigender Schritt hin zur Integration standardmäßiger Gesichtserkennungs- und sogar Ausdruckserkennungssysteme in generative Netzwerke zu sein, wohl der beste Weg nach vorn, um das Problem zu überwinden Blindpixel>Pixelzuordnung das dominiert aktuelle Deepfake-Architekturen auf Kosten der Ausdruckstreue und anderer wichtiger Bereiche im Bereich der Gesichtsgenerierung.)
Zugriff auf alle Bereiche im latenten Raum
Ein weiteres beeindruckendes Merkmal des Frameworks ist die Möglichkeit, je nach Wunsch des Benutzers beliebig zwischen möglichen Transformationen im latenten Raum zu wechseln. Bei früheren Systemen mit explorativen Schnittstellen musste der Benutzer oft zwischen festen Zeitlinien für Feature-Transformationen hin- und herwechseln – eine beeindruckende, aber oft recht lineare oder einschränkende Erfahrung.

Direkt von der Verbesserung des GAN-Gleichgewichts durch Steigerung des räumlichen Bewusstseins: Hier durchläuft der Benutzer eine Reihe potenzieller Übergangspunkte zwischen zwei latenten Raumpositionen, jedoch innerhalb der Grenzen vorab trainierter Positionen im latenten Raum. Um andere Arten der Transformation anzuwenden, die auf demselben Material basieren, ist eine Neukonfiguration und/oder Umschulung erforderlich. Quelle: https://genforce.github.io/eqgan/
Neben der Möglichkeit, völlig neue Benutzerbilder zu verwenden, kann der Benutzer auch Elemente, die während des Transformationsprozesses erhalten bleiben sollen, manuell „einfrieren“. Auf diese Weise kann der Benutzer beispielsweise sicherstellen, dass sich Hintergründe nicht verschieben oder die Augen geöffnet oder geschlossen bleiben.
Datum
Das Attributregressionsnetzwerk wurde auf drei Netzwerken trainiert: FFHQ, CelebAMask-HQund ein lokales, GAN-generiertes Netzwerk, das durch Abtasten von 400,000 Vektoren aus dem Z-Raum von erhalten wurde StyleGAN-V2.
Out-of-Distribution (OOD)-Bilder wurden herausgefiltert und Attribute mithilfe von Microsofts extrahiert Gesichts-API, wobei der resultierende Bildsatz im Verhältnis 90/10 aufgeteilt ist, so dass 721,218 Trainingsbilder und 72,172 Testbilder zum Vergleich übrig bleiben.
Tests
Obwohl das experimentelle Netzwerk ursprünglich für 35 potenzielle Transformationen konfiguriert war, wurden diese auf acht reduziert, um analoge Tests mit den vergleichbaren Frameworks durchzuführen InterFaceGAN, GANSpace und StyleFlow.
Die acht ausgewählten Attribute waren Alter, Kahlheit, Bart, Ausdruck, Geschlecht, Brillen, Tonhöhe (Pitch) und Gieren. Es war notwendig, die konkurrierenden Frameworks für bestimmte der acht Attribute, die in der ursprünglichen Distribution nicht bereitgestellt wurden, wie etwa das Hinzufügen, umzurüsten Kahlheit und Bart zu InterFaceGAN.
Wie erwartet kam es bei den konkurrierenden Architekturen zu einem größeren Grad an Verschränkung. In einem Test änderten beispielsweise InterFaceGAN und StyleFlow beide das Geschlecht des Probanden, als er zur Bewerbung aufgefordert wurde Alter:

Zwei der konkurrierenden Frameworks integrierten in die „Alters“-Transformation eine Geschlechtsänderung und änderten auch die Haarfarbe ohne direkten Befehl des Benutzers.
Darüber hinaus stellten zwei der Konkurrenten fest, dass Brille und Alter untrennbare Aspekte seien:

Brillen- und Haarfarbenwechsel ohne Aufpreis inklusive!
Es handelt sich nicht um einen einheitlichen Erfolg der Forschung: Wie im begleitenden Video am Ende des Artikels zu sehen ist, ist das Framework am wenigsten effektiv, wenn es darum geht, verschiedene Winkel (Gierwinkel) zu extrapolieren, während GANSpace ein besseres allgemeines Ergebnis für Alter und die Verhängung von Brille. Das mit GANSpace und StyleFlow verknüpfte Latent-zu-Latent-Framework hinsichtlich des Hinzufügens der Tonhöhe (Kopfwinkel).

Die berechneten Ergebnisse basieren auf einer Kalibrierung des MTCNN-Gesichtsdetektor. Niedrigere Ergebnisse sind besser.
Weitere Einzelheiten und eine bessere Auflösung der Beispiele finden Sie im Begleitvideo zum Dokument unten.
Erstveröffentlichung am 16. Februar 2022.












