AI 101
Co jsou CNN (Convolutional Neural Networks)?
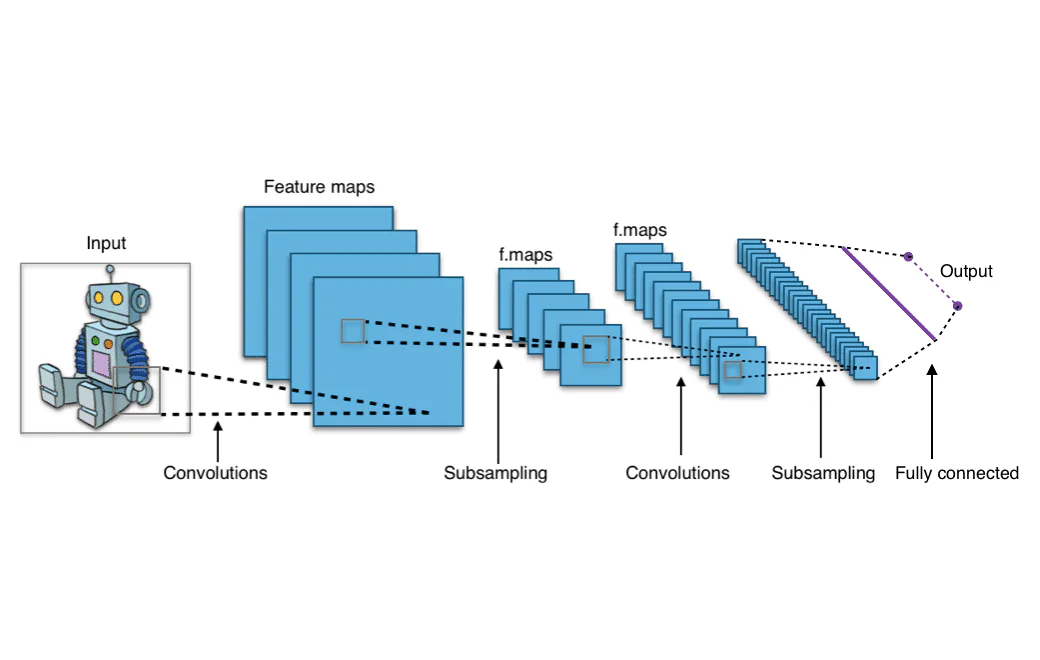
Možná jste se někdy divili, jak Facebook nebo Instagram dokáže automaticky rozpoznat tváře na obrázku, nebo jak Google umožňuje vyhledávat na webu podobné fotografie pouze tím, že nahrajete svou vlastní fotografii. Tyto funkce jsou příklady počítačového vidění a jsou poháněny convolutional neural networks (CNNs). Ale co exactly jsou convolutional neural networks? Pojďme se podívat na architekturu CNN a pochopit, jak fungují.
Co jsou Neural Networks?
Než začneme mluvit o convolutional neural networks, pojďme se podívat na definici běžných neuronových sítí. Existuje jiný článek na téma neuronových sítí, takže se do nich nebudeme příliš pouštět. Nicméně, aby jsme je stručně definovali, jsou to výpočetní modely inspirované lidským mozkem. Neuronová síť funguje tak, že přijímá data a manipuluje jimi úpravou “váh”, které jsou předpoklady o tom, jak jsou vstupní funkce spojeny s třídou objektu. Jakmile je síť trénována, hodnoty váh se upravují a měly by konvergovat na váhy, které přesně zachycují vztahy mezi funkcemi.
To je, jak funguje feed-forward neuronová síť, a CNN se skládá ze dvou částí: feed-forward neuronové sítě a skupiny convolutional vrstev.
Co jsou Convolution Neural Networks (CNNs)?
Co jsou “konvoluce”, které se dějí v convolutional neural network? Konvoluce je matematická operace, která vytváří sadu váh, což je vlastně reprezentace částí obrázku. Tato sada váh se nazývá jádro nebo filtr. Filtr, který je vytvořen, je menší než celý vstupní obrázek, pokrývá pouze část obrázku. Hodnoty ve filtru se násobí s hodnotami v obrázku. Filtr se poté přesune, aby vytvořil reprezentaci nové části obrázku, a proces se opakuje, dokud není celý obrázek pokrytý.
Jiný způsob, jak o tom přemýšlet, je si představit zdí z cihel, kde cihly reprezentují pixely ve vstupním obrázku. “Okno” se posouvá sem a tam po zdi, což je filtr. Cihly, které jsou vidět skrz okno, jsou pixely, jejichž hodnota se násobí hodnotami ve filtru. Z tohoto důvodu se tato metoda vytváření váh pomocí filtru často nazývá “technika posouvajících se oken”.
Výstup z filtrů, které se pohybují kolem celého vstupního obrázku, je dvourozměrné pole reprezentující celý obrázek. Toto pole se nazývá “mapa funkcí”.
Proč jsou konvoluce nezbytné
Jaký je účel vytváření konvolucí? Konvoluce jsou nezbytné, protože neuronová síť musí být schopna interpretovat pixely v obrázku jako numerické hodnoty. Funkce convolutional vrstev je převést obrázek na numerické hodnoty, které neuronová síť může interpretovat a poté extrahovat relevantní vzory. Úkolem filtrů v convolutional síti je vytvořit dvourozměrné pole hodnot, které lze předat do pozdějších vrstev neuronové sítě, které se naučí vzory v obrázku.
Filtry a kanály
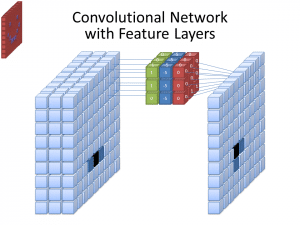
Foto: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNNs nepoužívají pouze jeden filtr k naučení vzorů z vstupních obrázků. Používají se multiple filtry, protože různé pole vytvořené různými filtry vedou k více komplexní a bohaté reprezentaci vstupního obrázku. Obvyklé počty filtrů pro CNNs jsou 32, 64, 128 a 512. Čím více filtrů je, tím více příležitostí má CNN k prozkoumání vstupních dat a naučení se z nich.
CNN analyzuje rozdíly v pixelových hodnotách, aby určil hranice objektů. U grayscale obrázku by CNN hledal pouze rozdíly v černé a bílé, světlo-tma. Když jsou obrázky barevné, CNN musí brát v úvahu nejen tmavé a světlé, ale také tři různé barevné kanály – červenou, zelenou a modrou. V tomto případě filtry mají 3 kanály, stejně jako obrázek sám. Počet kanálů, které filtr má, se nazývá jeho hloubka, a počet kanálů ve filtru musí odpovídat počtu kanálů v obrázku.
Architektura Convolutional Neural Network (CNN)
Pojeďme se podívat na kompletní architekturu convolutional neural network. Convolutional vrstva se nachází na začátku každé convolutional sítě, protože je nezbytná k transformaci obrazových dat na numerické pole. Nicméně, convolutional vrstvy mohou také následovat po jiných convolutional vrstvách, což znamená, že tyto vrstvy mohou být navzájem kombinovány. Mít multiple convolutional vrstvy znamená, že výstupy z jedné vrstvy mohou podstoupit další konvoluce a být seskupeny do relevantních vzorů. Prakticky to znamená, že jak obrazová data procházejí convolutional vrstvami, síť začíná “rozpoznávat” složitější funkce obrázku.
Rané vrstvy ConvNet jsou odpovědné za extrahování nízkoúrovňových funkcí, jako jsou pixely, které tvoří jednoduché linie. Pozdější vrstvy ConvNet spojí tyto linie do tvarů. Tento proces přechodu od povrchové analýzy k hluboké analýze pokračuje, dokud ConvNet nerozpozná složitější tvary, jako jsou zvířata, lidské tváře a auta.
Po prochodu všech convolutional vrstev data postupují do hustě propojené části CNN. Hustě propojené vrstvy jsou podobné tradiční feed-forward neuronové síti, série uzlů uspořádaných do vrstev, které jsou propojeny navzájem. Data postupují через tyto hustě propojené vrstvy, které se naučí vzory, které byly extrahovány convolutional vrstvami, a tím se síť stává schopnou rozpoznat objekty.










