大型语言模型 (LLM) 像 GPT、LLaMA 和其他模型已经以其令人惊叹的能力来理解和生成类似人类的文本而风靡全球。然而,尽管它们具有令人印象深刻的能力,但这些模型的标准训练方法,即 “下一个标记预测”,有一些固有的局限性。
在下一个标记预测中,模型被训练为预测一个序列中的下一个单词,给定前面的单词。虽然这种方法已经被证明是成功的,但它可能导致模型难以处理长距离依赖和复杂推理任务。另外,教师强制训练和自回归生成过程之间的不匹配可能导致次优性能。
Meta AI 的 Gloeckle 等人 (2024) 的一篇最近的研究论文引入了一种新的训练范式,称为 “多标记预测“,旨在解决这些局限性并超级充电大型语言模型。在这篇博客文章中,我们将深入探讨这一开创性研究的核心概念、技术细节和潜在影响。
单标记预测:传统方法
在深入探讨多标记预测的细节之前,了解大型语言模型训练多年的传统方法至关重要,即单标记预测,也称为下一个标记预测。
下一个标记预测范式
在下一个标记预测范式中,语言模型被训练为预测一个序列中的下一个单词,给定前面的上下文。更正式地,模型的任务是最大化下一个标记 xt+1 的概率,给定前面的标记 x1、x2、…、xt。这通常是通过最小化交叉熵损失来完成的:
L = -Σt log P(xt+1 | x1, x2, …, xt)
这种简单而强大的训练目标已经成为许多成功的大型语言模型的基础,例如 GPT (Radford 等,2018 年)、BERT (Devlin 等,2019 年) 和它们的变体。
教师强制和自回归生成
下一个标记预测依赖于一种称为 “教师强制” 的训练技术,其中模型在训练过程中为每个未来标记提供了真实值。这使得模型能够从正确的上下文和目标序列中学习,促进更稳定和高效的训练。
然而,在推理或生成过程中,模型以自回归的方式运行,根据先前生成的标记预测一个标记。教师强制训练和自回归生成之间的不匹配可能导致潜在的差异和次优性能,特别是对于更长的序列或复杂的推理任务。
下一个标记预测的局限性
虽然下一个标记预测已经取得了显著的成功,但它也有一些固有的局限性:
- 短期关注: 通过仅预测下一个标记,模型可能难以捕获长距离依赖和文本的整体结构和连贯性,可能导致不一致或不连贯的生成。
- 局部模式捕获: 下一个标记预测模型可以捕获训练数据中的局部模式,使得它们难以推广到分布外场景或需要更抽象推理的任务。
- 推理能力: 对于涉及多步骤推理、算法思维或复杂逻辑运算的任务,下一个标记预测可能无法提供足够的归纳偏差或表示来有效地支持这些能力。
- 样本效率: 由于下一个标记预测的局部性质,模型可能需要更大的训练数据集来获得必要的知识和推理技能,导致潜在的样本效率低下。
这些局限性激发了研究人员探索替代训练范式的兴趣,例如多标记预测,它旨在解决其中一些缺点并解锁大型语言模型的新能力。
通过对比传统的下一个标记预测方法和新颖的多标记预测技术,读者可以更好地理解后者的动机和潜在的好处,为更深入地探索这一开创性研究奠定了基础。
什么是多标记预测?
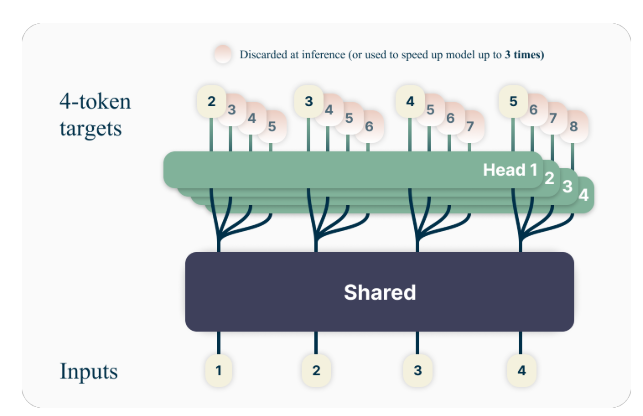
多标记预测的关键思想是训练语言模型预测多个未来标记,而不是仅预测下一个标记。具体来说,在训练过程中,模型的任务是预测每个位置的下一个 n 个标记,使用 n 个独立的输出头,依赖于共享的模型主干。
例如,使用 4 个标记预测设置,模型将被训练为预测 4 个下一个标记,给定前面的上下文。这一方法鼓励模型捕获更长距离的依赖关系和更好地理解文本的整体结构和连贯性。
一个玩具示例
为了更好地理解多标记预测的概念,让我们考虑一个简单的示例。假设我们有以下句子:
“快速的棕色狐狸跳过懒惰的狗。”
在标准的下一个标记预测方法中,模型将被训练为预测下一个单词,给定前面的上下文。例如,给定上下文 “快速的棕色狐狸跳过懒惰的”,模型将被任务预测下一个单词 “狗”。
然而,使用多标记预测,模型将被训练为预测多个下一个标记。例如,如果我们设置 n=4,模型将被训练为预测 4 个下一个标记。给定相同的上下文 “快速的棕色狐狸跳过懒惰的”,模型将被任务预测序列 “狗。”(注意句子末尾的空格以指示句子结束)。
通过训练模型预测多个下一个标记,模型被鼓励捕获更长距离的依赖关系和更好地理解文本的整体结构和连贯性。
技术细节
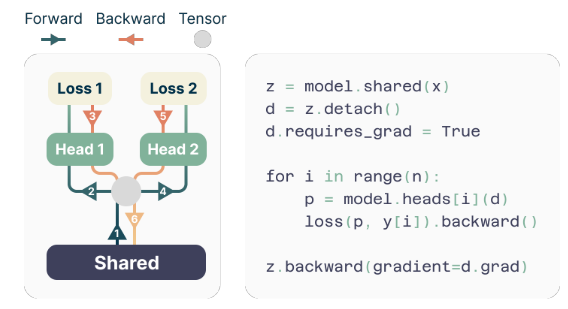
作者提出了一个简单而有效的多标记预测的架构。模型由一个共享的Transformer主干组成,生成输入上下文的潜在表示,然后是 n 个独立的Transformer层(输出头),预测相应的下一个标记。
在训练过程中,前向和后向传递被仔细编排,以最小化 GPU 内存占用。共享主干计算潜在表示,然后每个输出头顺序地执行其前向和后向传递,在主干级别累积梯度。这种方法避免了同时实例化所有 logit 向量及其梯度,减少了峰值 GPU 内存使用量,从 O(nV + d) 到 O(V + d),其中 V 是 词汇表大小,d 是 潜在表示的维度。
内存高效实现
训练多标记预测器的一个挑战是减少其 GPU 内存使用量。由于 词汇表大小 (V) 通常比 潜在表示的维度 (d) 大得多,logit 向量成为 GPU 内存使用的瓶颈。
为了解决这个挑战,作者提出了一个内存高效的实现,仔细调整了前向和后向操作的顺序。与其同时实例化所有 logit 向量及其梯度,不如每个独立的输出头顺序地执行其前向和后向传递,在主干级别累积梯度。
这种方法避免了同时存储所有 logit 向量及其梯度,减少了峰值 GPU 内存使用量,从 O(nV + d) 到 O(V + d),其中 n 是预测的下一个标记的数量。
多标记预测的优势
研究论文提出了多标记预测的几个令人信服的优势:
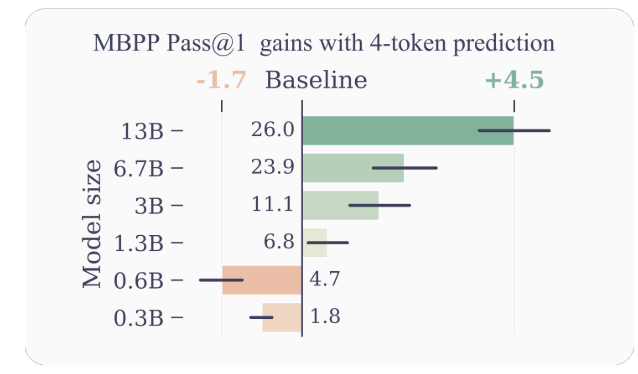
- 改进的样本效率: 通过鼓励模型预测多个下一个标记,多标记预测推动模型朝着更好的样本效率发展。作者展示了在代码理解和生成任务上的显著性能改进,具有多达 13 亿参数的模型平均解决了 15% 更多的问题。
- 更快的推理: 多标记预测训练的额外输出头可以用于自我推测解码,这是一种推测解码的变体,允许并行标记预测。结果是推理速度快了 3 倍,适用于广泛的批次大小,甚至对于大型模型也是如此。
- 促进长距离依赖: 多标记预测鼓励模型捕获更长距离的依赖和模式,这对于需要理解和推理更大上下文的任务尤其有益。
- 算法推理: 作者提出了在合成任务上的实验,展示了多标记预测模型在发展归纳头和算法推理能力方面的优越性,特别是对于较小的模型大小。
- 连贯性和一致性: 通过训练模型预测多个下一个标记,多标记预测鼓励模型发展连贯和一致的表示。这对于需要生成更长、更连贯的文本的任务尤其有益,例如讲故事、创作写作或生成说明手册。
- 改进的泛化: 作者的实验表明,多标记预测模型在合成任务上表现出更好的泛化能力,特别是在分布外设置中。这可能是由于模型能够捕获更长距离的模式和依赖,从而更好地推广到未见场景。

示例和直觉
为了更好地理解为什么多标记预测如此有效,让我们考虑几个示例:
- 代码生成: 在代码生成的背景下,预测多个标记可以帮助模型理解和生成更复杂的代码结构。例如,当生成函数定义时,仅预测下一个标记可能无法为模型提供足够的上下文来正确生成整个函数签名。然而,通过预测多个标记,模型可以更好地捕获函数名称、参数和返回类型之间的依赖关系,从而实现更准确和连贯的代码生成。
- 自然语言推理: 考虑一个语言模型被要求回答一个需要多步骤推理或信息片段的问题。通过预测多个标记,模型可以更好地捕获推理过程的不同组件之间的依赖关系,从而实现更连贯和准确的响应。
- 长文本生成: 当生成长文本(如故事、文章或报告)时,维持连贯性和一致性可能对使用下一个标记预测训练的语言模型来说是一个挑战。多标记预测鼓励模型发展出捕获文本整体结构和流程的表示,从而实现更连贯和一致的长文本生成。
局限性和未来方向
虽然论文中的结果令人印象深刻,但仍有一些局限性和开放问题需要进一步调查:
- 最佳标记数量: 论文探讨了不同的 n 值(要预测的下一个标记的数量),发现 n=4 对于许多任务都有效。然而,最佳的 n 值可能取决于具体任务、数据集和模型大小。开发确定最佳 n 的原则方法可能会带来进一步的性能改进。
- 词汇表大小和标记化: 作者指出,多标记预测模型的最佳词汇表大小和标记化策略可能与下一个标记预测模型不同。探索这一方面可能会带来更好的压缩序列长度和计算效率之间的权衡。
- 辅助预测损失: 作者建议他们的工作可能会激发人们对开发大型语言模型的新型辅助预测损失的兴趣,超越标准的下一个标记预测。研究替代辅助损失和它们与多标记预测的组合是一个令人兴奋的研究方向。
- 理论理解: 虽然论文提供了一些直觉和多标记预测有效性的实证证据,但对这一方法的工作原理和为什么如此有效的更深入的理论理解将是有价值的。
结论
Gloeckle 等人 (2024) 的研究论文 “通过多标记预测实现更好、更快的大型语言模型” 引入了一种新的训练范式,这种范式有可能显著提高大型语言模型的性能和能力。通过训练模型预测多个下一个标记,多标记预测鼓励模型发展长距离依赖、算法推理能力和更好的样本效率。
作者提出的技术实现优雅且计算高效,使其适用于大规模语言模型训练。另外,利用自我推测解码实现更快的推理是一个显著的实际优势。
虽然仍有一些开放问题和需要进一步探索的领域,但这一研究代表了大型语言模型领域的一个令人兴奋的步骤。随着对更强大和更高效的语言模型的需求继续增长,多标记预测可能成为下一代这些强大 AI 系统的关键组件。



