人工智能
SofGAN:一种提供更大控制权的GAN面部生成器
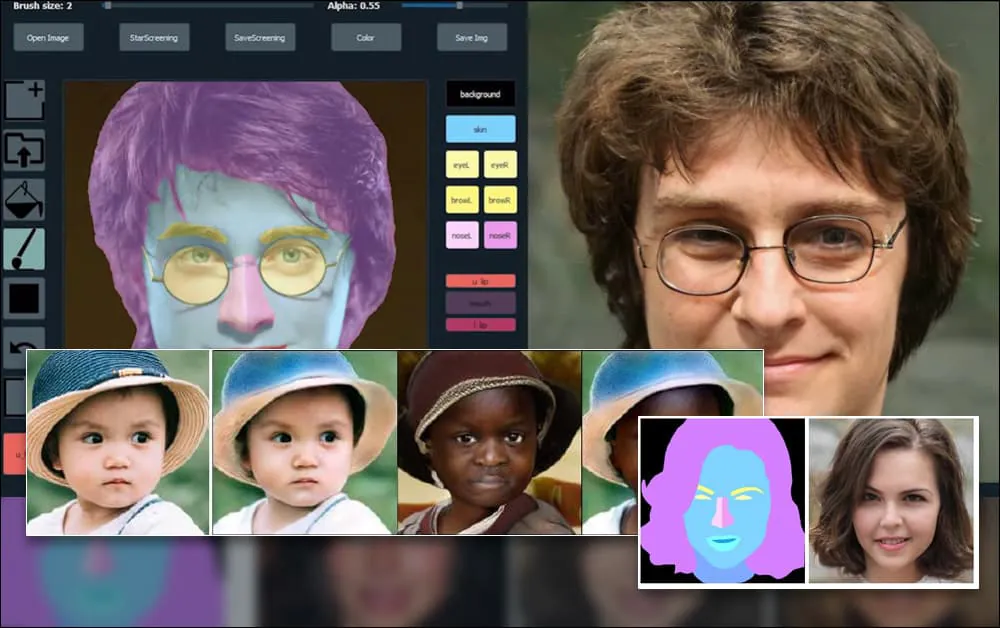
上海和美国的研究人员开发了一种基于GAN的肖像生成系统,允许用户创建具有以前不可用级别的控制的新面孔,例如头发、眼睛、眼镜、纹理和颜色。
为了展示该系统的多功能性,创建者提供了一个Photoshop风格的界面,用户可以直接绘制语义分割元素,这些元素将被重新解释为真实的图像,甚至可以通过直接绘制现有照片来获得。
在下面的示例中,演员丹尼尔·雷德克里夫的图片被用作追踪模板(目标不是产生他的相似度,而是一般的照片真实图像)。当用户填充各种元素,包括离散的方面,如眼镜时,它们被识别和解释在输出图像中:
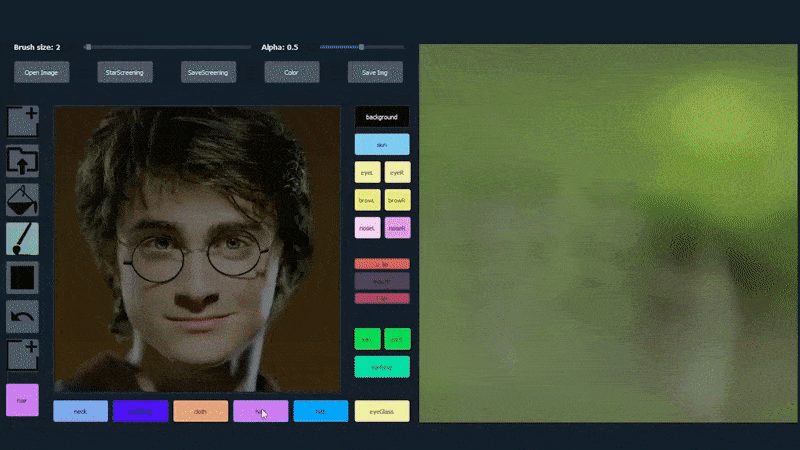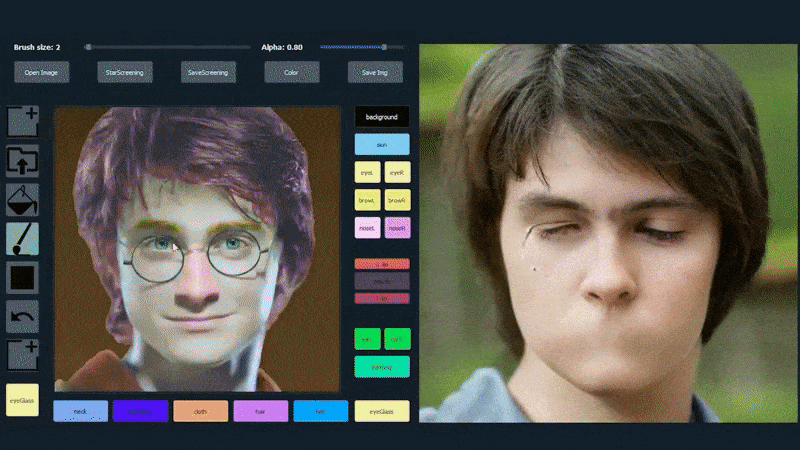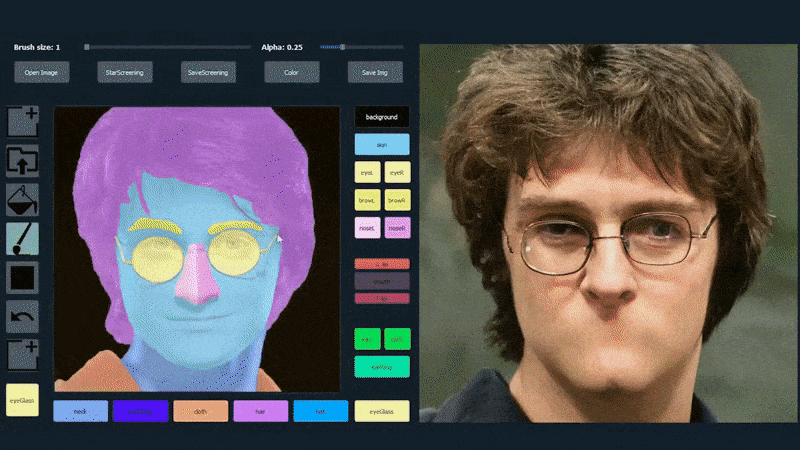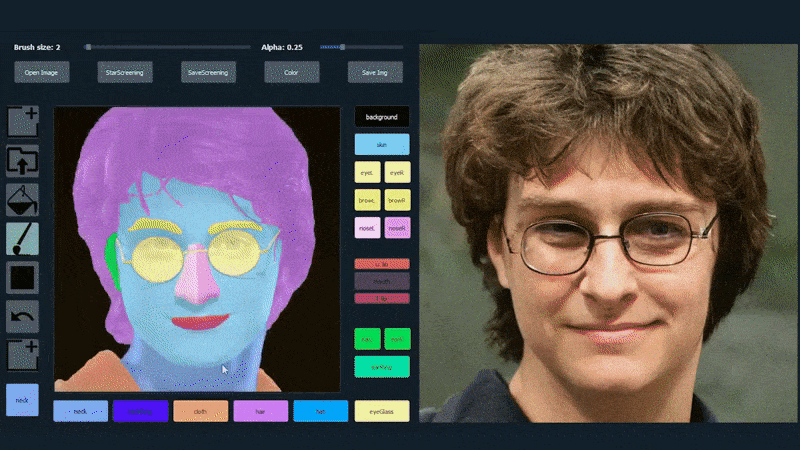
使用一张图片作为SofGAN生成肖像的追踪材料。 来源:https://www.youtube.com/watch?v=xig8ZA3DVZ8
该 论文 名为 SofGAN:具有动态风格的肖像图像生成器 ,由 Anpei Chen 和 Ruiyang Liu 领导,另外还有两位来自上海科技大学和加利福尼亚大学圣地亚哥分校的研究人员。
分离特征
该工作的主要贡献不在于提供用户友好的UX,而是在于“分离”学习的面部特征的特性,例如姿势和纹理,这使得SofGAN也可以生成面部朝向相机视点的间接角度。

在基于生成对抗网络的面部生成器中,SofGAN可以在训练数据中存在的角度数组的限制内任意改变视角。 来源:https://arxiv.org/pdf/2007.03780.pdf
由于纹理现在与几何分离,面部形状和纹理也可以作为单独的实体进行操作。实际上,这允许源面部的种族变化,这是一种 丑闻性的做法 ,现在有了一个潜在的有用应用,即创建 种族平衡的机器学习数据集 。

SofGAN还支持人工老化和属性一致的风格调整,在类似的分割>图像系统中,如NVIDIA的 GauGAN 和Intel的基于游戏的神经渲染 系统 中,具有前所未有的粒度。

SofGAN可以将老化作为迭代风格实现。
SofGAN的方法的另一个突破是,训练不需要成对的分割/真实图像,而可以直接在未配对的真实世界图像上进行训练。
研究人员表示,SofGAN的“分离”架构的灵感来自传统的图像渲染系统,这些系统将图像的个别方面分解。视觉效果工作流程中,复合图像的元素通常被分解为最小的组件,每个组件都有专门的专家。
语义占用场(SOF)
为了在机器学习图像合成框架中实现这一点,研究人员开发了一个 语义占用场 (SOF),它是传统占用场的扩展,用于个性化面部肖像的组件元素。SOF是在校准的多视图语义分割图上训练的,但没有任何地面真实监督。

来自单个分割图的多次迭代(左下)。
另外,2D分割图通过射线追踪SOF的输出获得,然后由GAN生成器进行纹理化。合成的语义分割图也通过三层编码器在低维空间中编码,以确保当视点改变时输出的连续性。
训练方案对每个语义区域的两个随机样式进行空间混合:

SofGAN的架构。
研究人员声称,SofGAN比当前的替代状态(SOTA)方法实现了更低的弗雷切特感知距离(FID),以及更高的学习感知图像补丁相似度(LPIPS)指标。
以前的StyleGAN方法经常受到特征纠缠的阻碍,其中组成图像的元素不可逆转地与彼此绑定,导致不需要的元素与所需的元素一起出现(例如,耳环可能会出现,当耳朵形状被渲染时,它是由训练时包含耳环的图片信息)。

射线追踪用于计算语义分割图的体积,实现多视点。
数据集和训练
三个数据集被用于SofGAN的开发:CelebAMask-HQ,一个包含30,000张高分辨率图像的仓库,从CelebA-HQ数据集中获取;NVIDIA的Flickr-Faces-HQ(FFHQ),包含70,000张图像,研究人员使用预训练的面部解析器对图像进行标记;以及一个自制的包含122张肖像扫描的数据集,具有手动标记的语义区域。
SOF由三个可训练的子模块组成:超网,射线行进器(见上图)和分类器。该项目的语义实例化StyleGAN生成器的配置与StyleGAN2在某些方面相似。数据增强通过随机缩放和裁剪进行,并且每四步进行路径正则化。整个训练过程需要22天才能在四个RTX 2080 Ti GPU上达到80万次迭代,使用CUDA 10.1。
该论文没有提到2080卡的配置,它们可以容纳11gb-22gb的VRAM,这意味着在几乎一个月的时间里训练SofGAN所使用的总VRAM在44Gb到88Gb之间。
研究人员观察到,接受的、一般化的、高级结果在训练的早期就开始出现,大约在1500次迭代,训练的三天内。训练的剩余时间花在了缓慢地朝着获得细节的过程中,例如头发和眼睛的方面。
SofGAN通常从单个分割图中实现比竞争方法(如NVIDIA的 SPADE 和 Pix2PixHD,以及 SEAN)更真实的结果。

以下是研究人员发布的视频。更多自托管视频可在 项目页面 上找到。
