人工智能
新的Deepfake方法解决了“面部宿主”问题

尽管媒体对深度伪造图像可能破坏我们对视频真实性的长期信任的潜力进行了多年的炒作,但所有当前流行的方法都依赖于找到与目标面部形状大致相似的“面部宿主”。
当原始镜头中有宽脸,但目标对象有窄脸时,结果始终存在问题,因为这种转移涉及切掉原始面部的一部分并重建现在暴露的背景。当前的软件包,如DeepFaceLab和FaceSwap,当配置反转(窄>宽)时,可以产生有限的结果,但它们没有解决这个场景的说服力。
现在,腾讯和中国厦门大学之间的合作开发了一种新的方法,称为HifiFace,旨在解决这个不足。

两张HifiFace深度伪造图像,第一张是安妮·海瑟薇,尽管宿主面部形状不兼容,但仍然获得了良好的相似度。HifiFace还在传统上深度伪造的绊脚石——眼镜目标上表现良好。 Source: https://arxiv.org/pdf/2106.09965.pdf
重塑深度伪造面部
之前的方法,例如2019年的主体无关面部交换和重演(FSGAN),依赖于3DMM拟合(3D可变形模型)或其他基于面部特征识别或变换的方法,其中要“覆盖”的面部线条基本上决定了交换的范围:

3DMM面部特征检测。 Source: https://github.com/Yinghao-Li/3DMM-fitting
虽然竞争方法利用了来自面部识别网络的特征,但这些主要是为了重新构建纹理而不是结构,并且在宿主面部不完全兼容的情况下(即发际线、下颌线和颧骨的限制和形状)会产生“面具般”的效果。
为了解决这些问题,中国研究人员开发了一个端到端的网络,该网络使用3D重构模型来回归目标和源面部的系数,然后将其重新组合为形状信息,并将其与来自面部识别网络的身份向量信息连接起来。
这种几何数据然后被输入到编码器-解码器模型中作为结构信息,融合目标面部的表情和姿势,这些被利用为准确转移的辅助源。

语义面部融合
另外,HifiFace包括一个语义面部融合(SFF)组件,该组件使用编码器中的低级特征来保留空间和纹理信息,而不牺牲目标图像的身份。编码器和解码器的特征被整合到一个学习的自适应掩码中,背景信息通过学习的面部掩码融入输出。

HifiFace在行动。 Source: https://johann.wang/HifiFace/
通过这种方式,HifiFace偏离了使用原始材料的面部边界作为硬限制,而是使用扩张面部语义分割,其中模型可以在面部边缘界限上更好地执行自适应融合。
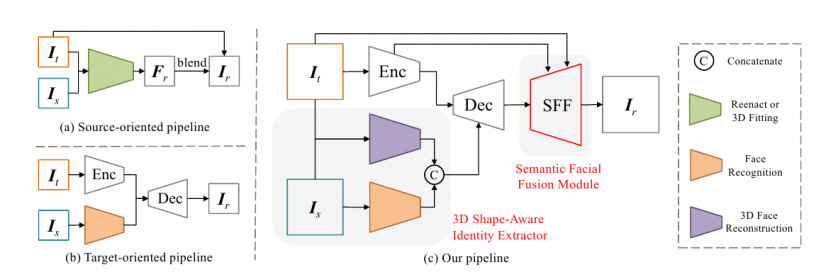
两种先前的方法(左上和左下),以及新的HifiFace架构,包括编码器、解码器、3D形状感知身份提取器和SFF模块。

在与前几种方法FSGAN、SimSwap和FaceShifter的比较中,HifiFace展示了更好的面部形状重构,因为它不是近似“幽灵”元素,而是在面部边界混淆身份映射时确定地重构它们。

测试
研究人员使用VGGFace2和DeepGlint Asian-Celeb数据集实现了该系统。面部通过5个外部标志对齐并裁剪到256×256像素。还使用了肖像增强网络来生成512×512像素的版本,用于额外的高分辨率模型。该模型在Adam下训练。

虽然FaceShifter在保留身份方面表现良好,但它不能像HifiFace一样有效地解决表达、颜色和遮挡问题,并且具有更复杂的网络结构。FSGAN在转移源到目标的照明时存在问题。
研究人员使用FaceForensics++进行量化比较,分别从每种方法转换的视频中采样十帧,并发现HifiFace获得了更高的ID检索分数。在测试其他因素(如图像质量)时,研究人员还发现他们的方法优于竞争对手。

本尼迪克特·康伯巴奇的面部线条被忠实地再现。
这项工作代表了进一步抽象源材料的步骤,使其仅作为粗略模板来转移准确的身份。一些当前的FOSS软件包,包括DeepFaceLab,具有原始的全头替换功能,但与HifiFace一样,它们不考虑头发,并且更擅长“构建”面部而不是雕刻它以匹配所需的目标源。
