从文本提示生成3D数字资产的能力代表了人工智能和计算机图形学中最令人兴奋的最近发展之一。随着3D数字资产市场预计从2024年的283亿美元增长到2029年的518亿美元 , 文本到3D AI模型有望在游戏、电影、电子商务等行业中革命性地改变内容创作。但是,这些AI系统到底是如何工作的?在本文中,我们将深入探讨文本到3D生成的技术细节。
3D生成的挑战
从文本生成3D资产比2D图像生成要复杂得多。虽然2D图像是基本的像素网格,但3D资产需要在三维空间中表示几何形状、纹理、材料和动画。这增加的维度和复杂性使得生成任务变得更加具有挑战性。
文本到3D生成中的一些关键挑战包括:
表示3D几何形状和结构
在3D表面上生成一致的纹理和材料
确保从多个视角来看的物理可行性和一致性
同时捕捉细节和全局结构
生成可以轻松渲染或3D打印的资产
为了解决这些挑战,文本到3D模型利用了几种关键技术和技术。
文本到3D系统的关键组件
大多数最先进的文本到3D生成系统共享几个核心组件:
文本编码 : 将输入文本提示转换为数值表示3D表示 : 表示3D几何形状和外观的方法生成模型 : 生成3D资产的核心AI模型渲染 : 将3D表示转换为2D图像以进行可视化
让我们更详细地探讨每一个组件。
文本编码
第一步是将输入文本提示转换为AI模型可以处理的数值表示。这通常使用像BERT或GPT 这样的大型语言模型来完成。
3D表示
有几种常见的方法来表示AI模型中的3D几何形状:
体素网格 : 代表占用或特征的3D值数组点云 : 一组3D点网格 : 定义表面的顶点和面隐式函数 : 定义表面的连续函数(例如有符号距离函数)神经辐射场 (NeRFs)
每种方法都有其在分辨率、内存使用和生成易用性方面的权衡。许多最近的模型使用隐式函数或NeRFs,因为它们可以在合理的计算要求下产生高质量的结果。
例如,我们可以将一个简单的球体表示为一个有符号距离函数:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluate SDF at a 3D point
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Distance to sphere surface: {distance}")
生成模型
文本到3D系统的核心是生成3D表示的AI模型。大多数最先进的模型使用某种扩散模型,类似于2D图像生成中使用的模型。
扩散模型通过逐渐向数据添加噪声,然后学习逆转此过程来工作。对于3D生成,这个过程发生在所选3D表示的空间中。
一个简化的扩散模型训练步骤伪代码可能如下所示:
def diffusion_training_step(model, x_0, text_embedding):
# Sample a random timestep
t = torch.randint(0, num_timesteps, (1,))
# Add noise to the input
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# Predict the noise
predicted_noise = model(x_t, t, text_embedding)
# Compute loss
loss = F.mse_loss(noise, predicted_noise)
return loss
# Training loop
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
在生成过程中,我们从纯噪声开始,迭代去噪,条件为文本嵌入。
渲染
为了可视化结果并在训练过程中计算损失,我们需要将3D表示渲染为2D图像。这通常使用可微渲染技术来完成,这些技术允许梯度通过渲染过程反向传播。
对于基于网格的表示,我们可能使用基于光栅化的渲染器:
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# Create a renderer
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# Set up camera
cameras = pr.FoVPerspectiveCameras()
# Render
images = renderer(vertices, faces, cameras=cameras)
return images
# Example usage
vertices = torch.rand(1, 100, 3) # Random vertices
faces = torch.randint(0, 100, (1, 200, 3)) # Random faces
rendered_images = render_mesh(vertices, faces)
对于隐式表示,如NeRFs,我们通常使用光线行进技术来渲染视图。
将所有内容整合在一起:文本到3D管道
现在我们已经介绍了关键组件,让我们来看看它们如何在典型的文本到3D生成管道中组合起来:
文本编码 : 输入提示被编码为一个密集的向量表示,使用语言模型。初始生成 : 一个扩散模型,条件为文本嵌入,生成一个初始的3D表示(例如NeRF或隐式函数)。多视图一致性 : 模型渲染生成的3D资产的多个视图,并确保视图之间的一致性。细化 : 额外的网络可能会细化几何形状、添加纹理或增强细节。最终输出 : 3D表示被转换为所需的格式(例如有纹理的网格),用于下游应用程序。
以下是一个简化的示例,展示了这可能是什么样子:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Encode text
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Generate initial 3D representation
initial_3d = self.diffusion_model(text_embedding)
# Render multiple views
views = self.renderer(initial_3d, num_views=4)
# Refine based on multi-view consistency
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Usage
model = TextTo3D()
text_prompt = "A red sports car"
generated_3d = model(text_prompt)
顶级文本到3D资产模型
3DGen – Meta
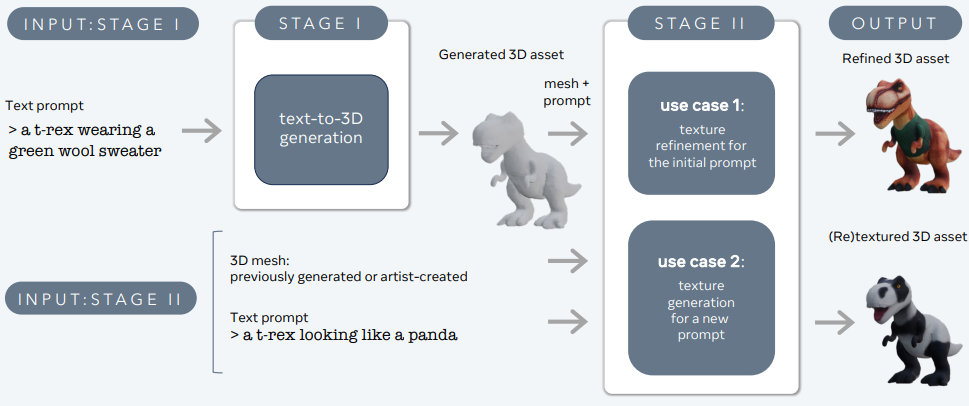
3DGen 旨在解决从文本描述生成3D内容(如角色、道具和场景)的问题。
Large Language and Text-to-3D Models – 3d-gen
3DGen支持基于物理的渲染(PBR),这对于在现实世界应用中对3D资产进行重新照明是必不可少的。它还允许使用新的文本输入对以前生成或由艺术家创建的3D形状进行生成性重新纹理化。管道集成了两个核心组件:Meta 3D AssetGen和Meta 3D TextureGen,分别处理文本到3D和文本到纹理生成。
Meta 3D AssetGen
Meta 3D AssetGen(Siddiqui et al.,2024)负责从文本提示生成初始3D资产。该组件生成一个带有纹理和PBR材质映射的3D网格,耗时约30秒。
Meta 3D TextureGen
Meta 3D TextureGen(Bensadoun et al.,2024)细化AssetGen生成的纹理。它还可以用于根据附加文本描述为现有3D网格生成新纹理。该阶段大约需要20秒。
Point-E(OpenAI)
Point-E,由OpenAI开发 ,是另一个值得注意的文本到3D生成模型。与DreamFusion不同,DreamFusion生成NeRF表示,Point-E生成3D点云。
Point-E的关键特征:
a)两阶段管道 :Point-E首先使用文本到图像扩散模型生成合成2D视图,然后使用此图像来条件第二个扩散模型,该模型生成3D点云。
b)效率 :Point-E被设计为计算高效,能够在单个GPU上几秒钟内生成3D点云。
c)颜色信息 :该模型可以生成彩色的点云,保留了几何和外观信息。
限制:
与基于网格或NeRF的方法相比,保真度较低
点云需要额外的处理才能用于许多下游应用程序
Shap-E(OpenAI):
在Point-E的基础上,OpenAI推出了Shap -E,它生成3D网格而不是点云。这解决了Point-E的一些限制,同时保持了计算效率。
Shap-E的关键特征:
a)隐式表示 :Shap-E学习生成3D对象的隐式表示(有符号距离函数)。
b)网格提取 :该模型使用可微分的行进立方体算法来将隐式表示转换为多边形网格。
c)纹理生成 :Shap-E还可以为3D网格生成纹理,从而产生更具视觉吸引力的输出。
优势:
快速生成时间(几秒到几分钟)
直接网格输出,适合渲染和下游应用程序
能够同时生成几何和纹理
GET3D(NVIDIA):
GET3D,由NVIDIA研究人员开发 ,是另一个强大的文本到3D生成模型,专注于生成高质量的有纹理3D网格。
GET3D的关键特征:
a)显式表面表示 :与DreamFusion或Shap-E不同,GET3D直接生成显式表面表示(网格),而无需中间隐式表示。
b)纹理生成 :该模型包括可微分渲染技术来学习和生成3D网格的高质量纹理。
c)基于GAN的架构 :GET3D使用生成对抗网络(GAN)方法,这允许在模型训练后快速生成。
优势:
高质量的几何和纹理
快速的推理时间
直接集成到3D渲染引擎中
限制:
需要3D训练数据,这对于某些对象类别来说可能很稀缺
结论
文本到3D AI生成代表了我们创建和交互3D内容的方式发生了根本性的转变。通过利用先进的深度学习技术,这些模型可以从简单的文本描述中生成复杂、高质量的3D资产。随着技术的不断发展,我们可以期待看到越来越复杂和强大的文本到3D系统,它们将革命性地改变从游戏和电影到产品设计和建筑等行业。