人工智能
为单个问题创建GPT风格的语言模型

中国的研究人员开发了一种经济的方法来创建GPT-3风格的自然语言处理系统,而不需要训练大量数据集所带来的巨大时间和金钱成本,这种趋势正日益增长,否则将最终使这一人工智能领域仅限于FAANG玩家和高级投资者。
提出的框架称为任务驱动语言建模(TLM)。与其训练一个巨大而复杂的模型在数十亿字和数千个标签和类别的巨大语料库上,TLM训练一个小得多的模型,它实际上将查询直接纳入模型中。

左,典型的超大规模语言模型方法;右,TLM的细长方法,用于按主题或问题探索大型语言语料库。来源:https://arxiv.org/pdf/2111.04130.pdf
有效地,为了回答单个问题,会产生一个独特的NLP算法或模型,而不是创建一个巨大而笨拙的通用语言模型,可以回答更广泛的问题。
在测试TLM时,研究人员发现新的方法实现的结果与预训练语言模型(如RoBERTa-Large)和超大规模NLP系统(如OpenAI的GPT-3,Google的TRILLION参数开关变压器模型,韩国的HyperClover,AI21实验室的Jurassic 1和Microsoft的Megatron-Turing NLG 530B)相似或更好。
在四个领域的八个分类数据集上进行的TLM试验中,作者还发现该系统将训练FLOPs(每秒浮点运算)减少了两个数量级。研究人员希望TLM可以“民主化”一个正在变得越来越精英的领域,NLP模型太大,无法在本地安装,而是位于GPT-3后面,位于OpenAI和昂贵和有限访问的API后面,现在还包括Microsoft Azure。
作者指出,减少两个数量级的训练时间将训练成本从1,000个GPU一天减少到仅8个GPU48小时。
新的报告的标题为无需大规模预训练的NLP:一种简单高效的框架,来自北京清华大学的三位研究人员和中国人工智能开发公司Recurrent AI公司的一位研究人员。
无法承受的答案
训练有效的、通用的语言模型的成本正日益被认为是人工智能领域中自然语言处理(NLP)发展的潜在“热限”。
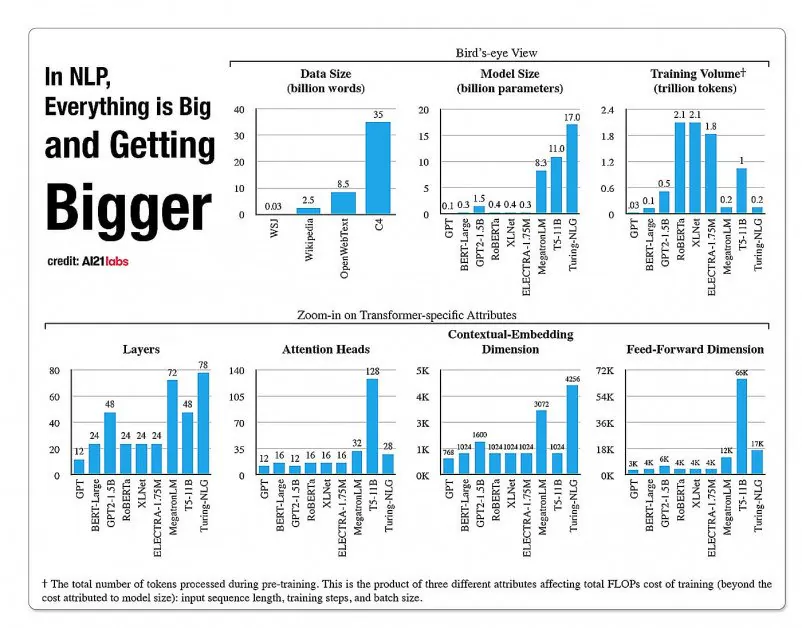
NLP模型架构中方面的增长统计,来自A121实验室2020年的报告。来源:https://arxiv.org/pdf/2004.08900.pdf
2019年,一位研究人员计算出训练XLNet模型(当时报告称其在NLP任务中优于BERT)的成本为61,440美元,训练时间为2.5天,使用512个核心和64个设备,而GPT-3的训练成本估计为1200万美元,是其前身GPT-2的200倍(尽管最近的重新估计表明,它现在可以以460万美元的价格在最低价的云GPU上训练)。
基于查询需求的数据子集
相反,新的提议架构旨在通过使用查询作为一种过滤器来定义大型语言数据库中的信息子集,并将其与查询一起训练,以提供有关有限主题的答案,从而实现准确的分类、标签和概括。
作者指出:
‘TLM的动机来自两个关键想法。首先,人类通过使用世界知识的一小部分来掌握一项任务(例如,学生只需要复习世界上所有书籍中的几章才能为考试做准备)。’
‘我们假设,对于一个特定的任务,大型语料库中存在大量冗余。其次,在有标签的数据上训练有监督的标签数据比在无标签数据上优化语言建模目标更节省数据。基于这些动机,TLM使用任务数据作为查询来检索一般语料库的一小部分。然后,使用检索的数据和任务数据共同优化有监督的任务目标和语言建模目标。’
除了使高效的NLP模型训练变得可承受外,作者还看到了使用任务驱动的NLP模型的几个优势。例如,研究人员可以享受到更大的灵活性,拥有自定义的序列长度、标记化、超参数调优和数据表示策略。
研究人员还预见了未来混合系统的发展,这些系统将有限的预训练PLM(在当前实现中不预期)与更大的多功能性和概括性权衡,换取训练时间。他们认为该系统是推进领域内零样本泛化方法发展的步骤。
测试和结果
TLM在四个领域的八个任务中进行了测试,包括生物医学科学、新闻、评论和计算机科学。任务被分为高资源和低资源类别。高资源任务包括超过5,000个任务数据,例如AGNews和RCT等;低资源任务包括ChemProt和ACL-ARC,以及HyperPartisan新闻检测数据集。
研究人员开发了两个名为Corpus-BERT和Corpus-RoBERTa的训练集,后者是前者的十倍大小。实验比较了通用的预训练语言模型BERT(来自Google)和RoBERTA(来自Facebook)与新的架构。
该论文观察到,尽管TLM是一种通用方法,应该比更广泛和更高容量的最先进模型的范围和适用性更有限,但它能够实现与领域适应性微调方法相似的性能。

将TLM的性能与BERT和RoBERTa基于集成进行比较的结果。结果列出了三个不同训练规模的平均F1得分,并列出了参数数量、总训练计算(FLOPs)和训练语料库的大小。
作者得出结论,TLM能够实现与PLM相似或更好的结果,同时大大减少了所需的FLOPs,并且只需要1/16的训练语料库。在中等和大规模上,TLM显然可以提高0.59和0.24个点的平均性能,同时将训练数据大小减少了两个数量级。
‘这些结果证实TLM既高效又非常准确。另外,TLM在更大规模上具有更大的优势。这表明,更大规模的PLM可能被训练来存储更多的通用知识,这些知识对于特定任务来说是无用的。’
