
Штучний Інтелект
Попереду три виклики для стабільної дифузії

Команда звільнити of stability.ai Stable Diffusion прихована дифузія Модель синтезу зображення пару тижнів тому може стати одним із найважливіших технологічних розкриттів з DeCSS у 1999 році; це, безперечно, найбільша подія в області зображень, створених штучним інтелектом, з 2017 року код deepfakes було скопійовано на GitHub і розділено на те, що станеться DeepFaceLab та Заміна обличчя, а також потокове програмне забезпечення deepfake у реальному часі DeepFaceLive.
При інсульті, розчарування користувача за обмеження вмісту в API синтезу зображень DALL-E 2 були відкинуті, оскільки виявилося, що фільтр NSFW Stable Diffusion можна вимкнути, змінивши єдиний рядок коду. Stable Diffusion Reddits, орієнтований на порно, з’явився майже миттєво, і його так само швидко скоротили, у той час як табір розробників і користувачів розділився на Discord на офіційну та NSFW спільноти, а Twitter почав заповнюватись фантастичними творіннями Stable Diffusion.
На даний момент кожен день, здається, приносить якісь дивовижні інновації від розробників, які прийняли систему, з плагінами та сторонніми додатками, які поспішно пишуться для Крита, Photoshop, Cinema4D, змішувачта багато інших платформ додатків.

У той же час, швидке ремесло – нині професійне мистецтво «ШІ шепоту», яке може стати найкоротшим варіантом кар’єри після «Filofax binder» – уже стає комерціалізований, тоді як рання монетизація Stable Diffusion відбувається в Рівень патреона, з упевненістю, що з’являться більш складні пропозиції для тих, хто не хоче орієнтуватися На основі Conda встановлення вихідного коду або заборонні фільтри NSFW веб-реалізацій.
Темп розробки та вільне відчуття користувачів розвиваються з такою запаморочливою швидкістю, що важко зазирнути далеко вперед. По суті, ми ще точно не знаємо, з чим маємо справу, чи які всі обмеження чи можливості можуть бути.
Тим не менш, давайте подивимося на три найцікавіші та найскладніші перешкоди для спільноти Stable Diffusion, що швидко сформувалася та швидко зростає, і, сподіваємось, подолати їх.
1: Оптимізація плиткових трубопроводів
З огляду на обмежені апаратні ресурси та жорсткі обмеження на роздільну здатність навчальних зображень, схоже, що розробники знайдуть обхідні шляхи для покращення як якості, так і роздільної здатності вихідних даних Stable Diffusion. Багато з цих проектів спрямовані на використання обмежень системи, таких як її рідна роздільна здатність лише 512×512 пікселів.
Як це завжди буває з ініціативами комп’ютерного зору та синтезу зображень, Stable Diffusion було навчено на зображеннях із квадратним співвідношенням, у цьому випадку повторно дискретизованих до 512 × 512, щоб вихідні зображення могли бути регуляризовані та відповідати обмеженням графічних процесорів, які тренував модель.
Тому Stable Diffusion «мислить» (якщо думає взагалі) у 512 × 512 термінах і, звичайно, у квадратах. Багато користувачів, які наразі досліджують межі системи, повідомляють, що Stable Diffusion дає найнадійніші результати з найменшими збоями при цьому досить обмеженому співвідношенні сторін (див. «вирішення крайніх проблем» нижче).
Хоча в різних реалізаціях є функція масштабування за допомогою RealESRGAN (і може виправити погано відтворені обличчя через GFPGAN) кілька користувачів наразі розробляють методи поділу зображень на частини розміром 512x512 пікселів і зшивання зображень у більші складені роботи.

Цей рендер 1024 × 576, роздільна здатність, яка зазвичай неможлива в одному рендері Stable Diffusion, був створений шляхом копіювання та вставлення файлу Python attention.py з DoggettX форк Stable Diffusion (версія, яка реалізує масштабування на основі плиток) в інший форк. Джерело: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Хоча деякі ініціативи такого роду використовують оригінальний код або інші бібліотеки, порт txt2imghd GOBIG (режим у ProgRockDiffusion, що потребує VRAM) незабаром надасть цю функціональність головній гілці. Хоча txt2imghd є спеціальним портом GOBIG, інші зусилля розробників спільноти включають різні реалізації GOBIG.

Зручне абстрактне зображення в оригінальній візуалізації 512x512 пікселів (ліворуч і другий зліва); підвищено за допомогою ESGRAN, який тепер є більш-менш рідним для всіх дистрибутивів Stable Diffusion; і приділяється «особлива увага» через реалізацію GOBIG, створюючи деталі, які, принаймні в межах розділу зображення, здаються краще масштабованими. Сджерело: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Наведений вище абстрактний приклад має багато «маленьких королівств» деталей, які відповідають цьому соліпсистському підходу до масштабування, але можуть вимагати більш складних рішень, керованих кодом, щоб створити неповторюване, згуртоване масштабування, яке не дивитися ніби він зібраний з багатьох частин. Не в останню чергу це стосується людських облич, де ми надзвичайно налаштовані на аберації або «різкі» артефакти. Тому для обличчя може знадобитися спеціальне рішення.
Stable Diffusion наразі не має механізму фокусування уваги на обличчі під час візуалізації так само, як люди визначають пріоритет інформації про обличчя. Хоча деякі розробники в спільнотах Discord розглядають методи реалізації такого типу «посиленої уваги», наразі набагато простіше вручну (і, зрештою, автоматично) покращити обличчя після початкового рендерингу.
Обличчя людини має внутрішню та повну семантичну логіку, яку не можна знайти в «плитці» нижнього кута (наприклад) будівлі, тому наразі можна дуже ефективно «збільшити» та повторно відобразити «схемчасте» обличчя на виході Stable Diffusion.

Ліворуч: початкова спроба Stable Diffusion із підказкою «Кольорове фото в повний зріст Крістіни Хендрікс, яка заходить у багатолюдне місце в плащі; Canon50, зоровий контакт, висока деталізація, висока деталізація обличчя». Правильно, покращене обличчя, отримане шляхом передачі розмитого та схематичного обличчя з першого рендера назад у повну увагу Stable Diffusion за допомогою Img2Img (див. анімовані зображення нижче).
За відсутності спеціального рішення текстової інверсії (див. нижче) це працюватиме лише для зображень знаменитостей, де особа, про яку йде мова, уже добре представлена в підмножинах даних LAION, які тренували стабільну дифузію. Тому він працюватиме з такими людьми, як Том Круз, Бред Пітт, Дженніфер Лоуренс та обмеженим колом справжніх медіа-світил, які присутні у великій кількості зображень у вихідних даних.
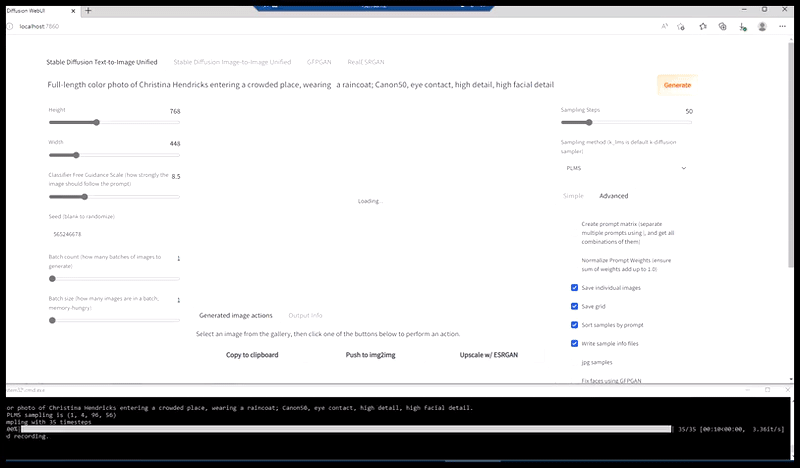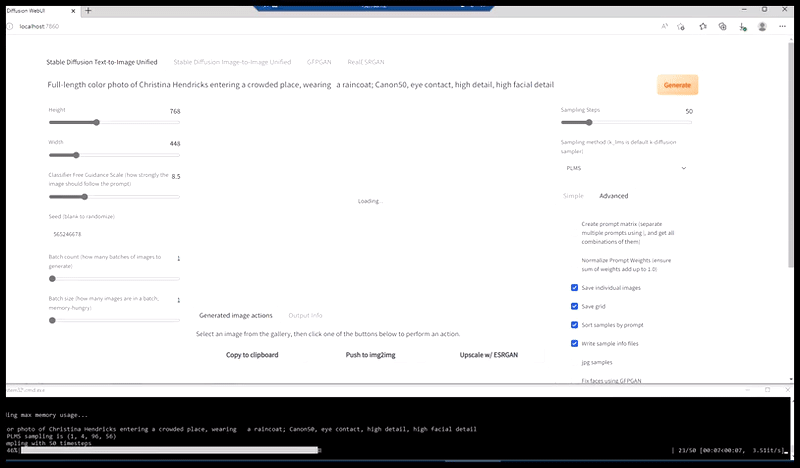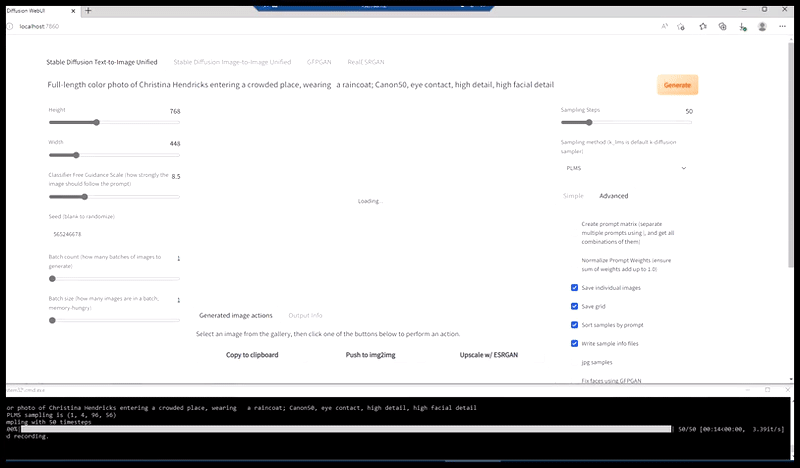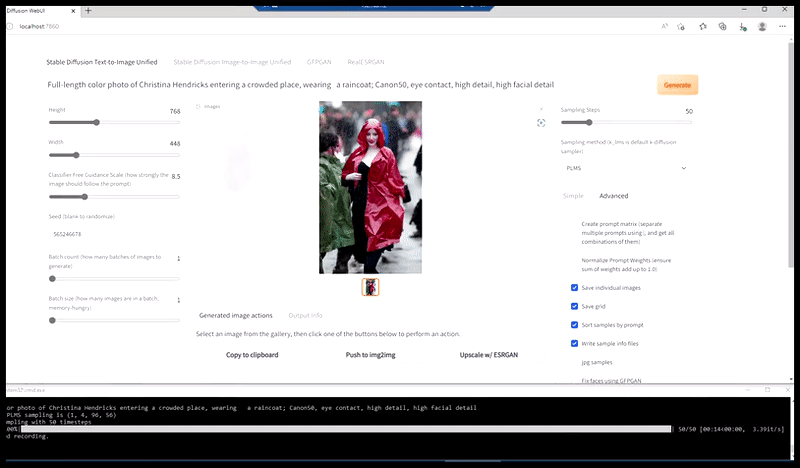
Створення правдоподібного зображення для преси з підказкою «Кольорове фото в повний зріст Крістіни Хендрікс, яка заходить у людне місце в плащі; Canon50, зоровий контакт, висока деталізація, висока деталізація обличчя».
Для знаменитостей із довгою та тривалою кар’єрою Stable Diffusion зазвичай створює образ особи в недавньому (тобто старшому) віці, і необхідно буде додати швидкі додатки, такі як "молодий" or 'у році [YEAR]' щоб створювати зображення молодшого вигляду.

Актриса Дженніфер Коннеллі має видатну, багатофотографовану та послідовну кар’єру, що охоплює майже 40 років, і є однією з небагатьох знаменитостей у LAION, які дозволяють Stable Diffusion представляти різний вік. Джерело: пакет Stable Diffusion, локальний, контрольна точка v1.4; вікові підказки.
Це значною мірою пов’язано з поширенням цифрової (а не дорогої емульсійної) прес-фотографії з середини 2000-х років і пізнішим зростанням обсягу виведення зображень завдяки збільшенню швидкостей широкосмугового зв’язку.
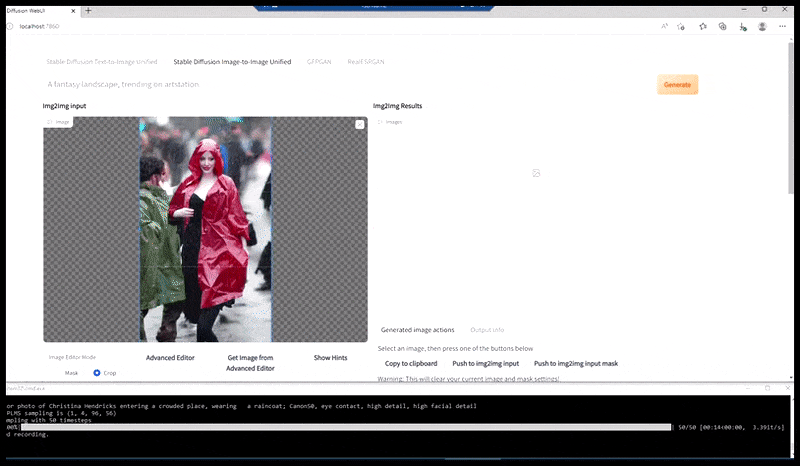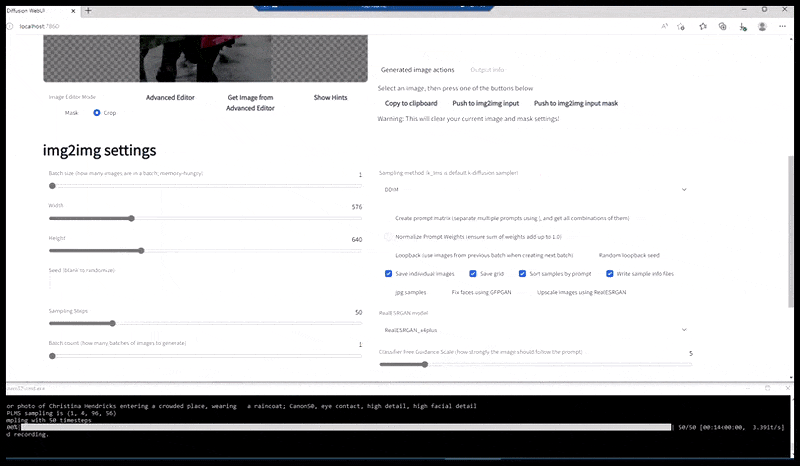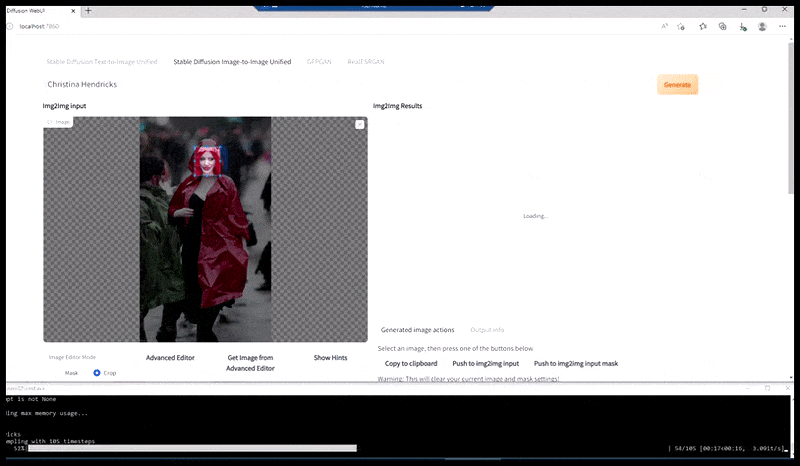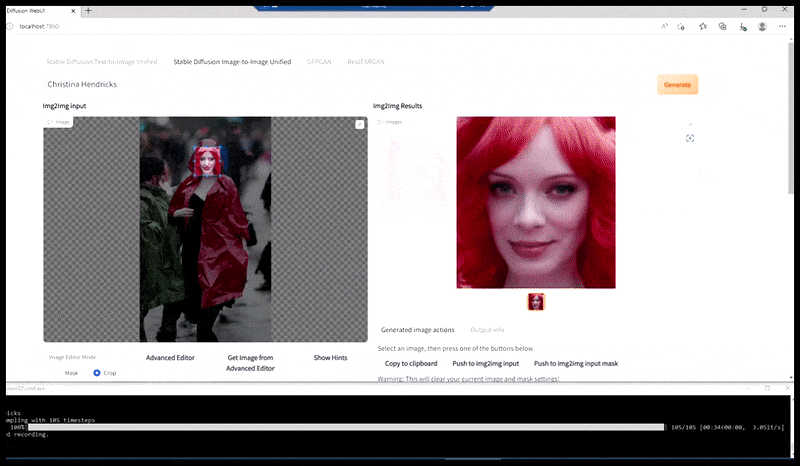
Візуалізоване зображення передається до Img2Img у Stable Diffusion, де вибирається «область фокусування», і нова візуалізація максимального розміру створюється лише для цієї області, що дозволяє Stable Diffusion зосередити всі наявні ресурси на відтворенні обличчя.
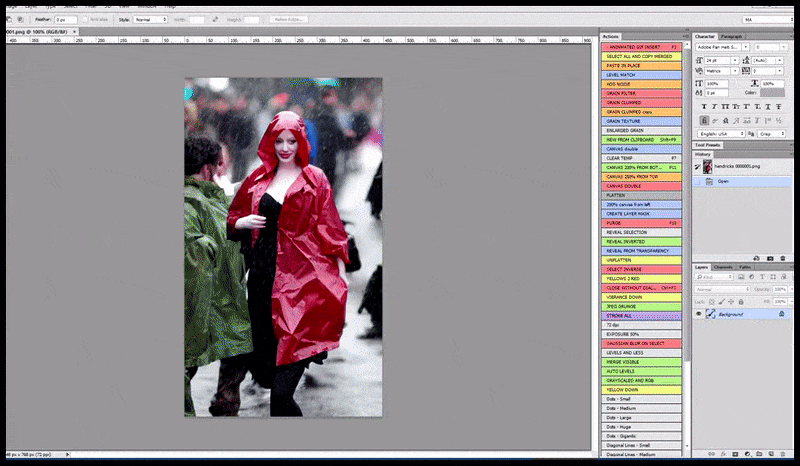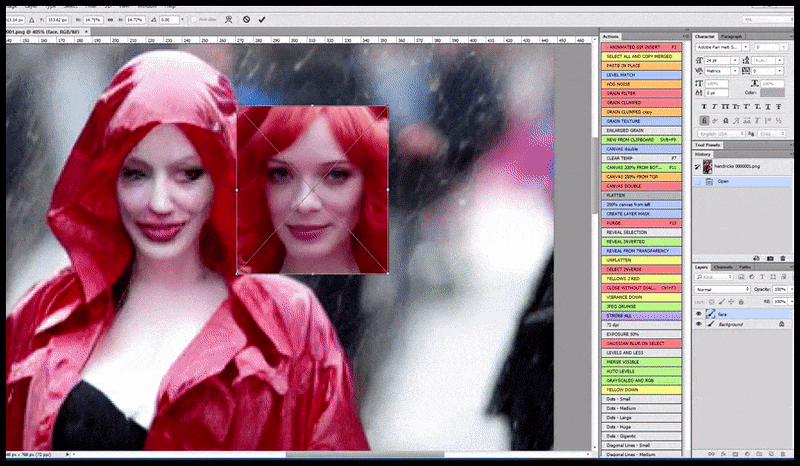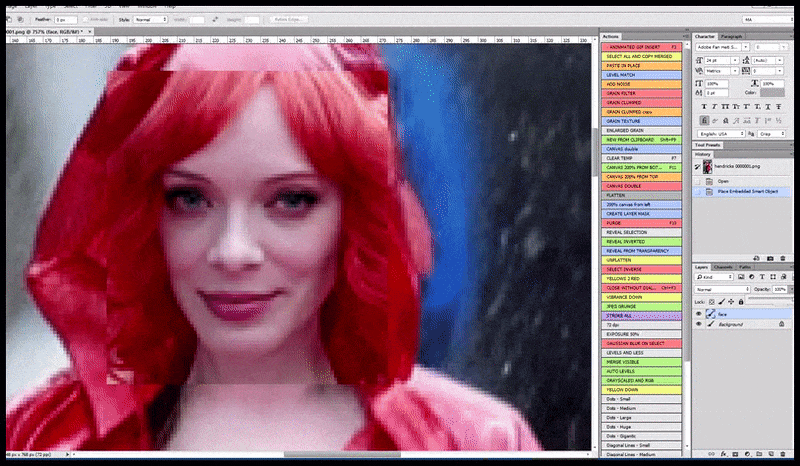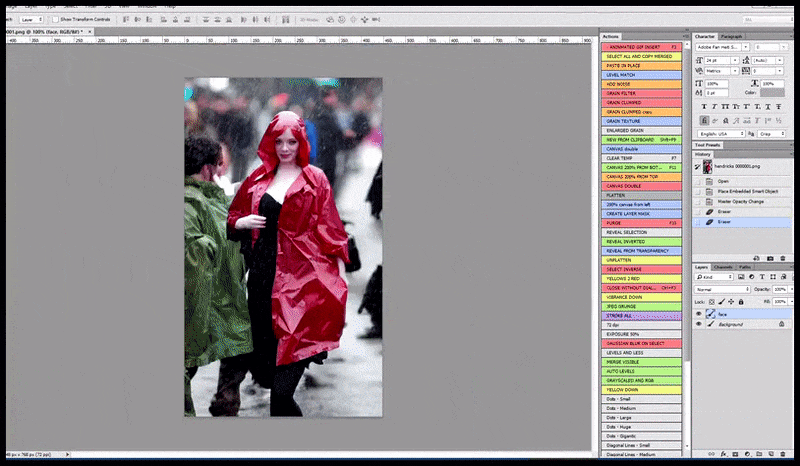
Обличчя «високої уваги» повертається до оригінального візуалізації. Окрім облич, цей процес працюватиме лише з об’єктами, які мають потенційно відомий, цілісний і цілісний вигляд, як-от частина вихідної фотографії, яка містить окремий об’єкт, як-от годинник чи автомобіль. Збільшення розміру частини – наприклад – стіни призведе до дуже дивної на вигляд знову зібраної стіни, оскільки візуалізація плитки не мала ширшого контексту для цього «фрагмента мозаїки» під час рендерингу.
Деякі знаменитості в базі даних стають «замороженими» в часі або через те, що вони рано померли (наприклад, Мерилін Монро), або тому, що лише швидко піднялися до мейнстріму, створивши велику кількість зображень за обмежений період часу. Стабільне розповсюдження при опитуванні, мабуть, забезпечує свого роду «поточний» індекс популярності для сучасних і старших зірок. Для деяких старих і нинішніх знаменитостей у вихідних даних недостатньо зображень, щоб отримати дуже хорошу схожість, тоді як незмінна популярність певних давно померлих або згаслих зірок гарантує, що їхню обґрунтовану схожість можна отримати з системи.

Рендеринг Stable Diffusion швидко виявляє, які відомі обличчя добре представлені в навчальних даних. Незважаючи на її величезну популярність як старшого підлітка на момент написання статті, Міллі Боббі Браун була молодшою та менш відомою, коли вихідні набори даних LAION були вилучені з Інтернету, що робило високоякісну подібність за допомогою Stable Diffusion на даний момент проблематичним.
Там, де дані доступні, плиткові рішення для збільшення роздільної здатності в Stable Diffusion можуть піти далі, ніж наведення на обличчя: вони потенційно можуть створити ще точніші та деталізовані обличчя, порушуючи риси обличчя та використовуючи всю силу локального графічного процесора. ресурси щодо основних функцій окремо, перед повторним складанням – процес, який наразі, знову ж таки, виконується вручну.

Це не обмежується обличчями, але обмежується частинами об’єктів, які принаймні так само передбачувано розміщені в ширшому контексті головного об’єкта, і які відповідають високорівневим вбудованостям, які можна розумно очікувати знайти в гіпермасштабі. набір даних.
Справжнім обмеженням є кількість доступних довідкових даних у наборі даних, тому що, зрештою, детально повторені деталі стануть повністю «галюцинованими» (тобто фіктивними) і менш автентичними.
Такі зернисті розширення високого рівня працюють у випадку Дженніфер Коннеллі, оскільки вона добре представлена в різних вікових групах у LAION-естетика (первинна підмножина LAION 5B які використовує Stable Diffusion), і загалом у LAION; у багатьох інших випадках точність постраждала б через брак даних, що вимагало або тонкого налаштування (додаткове навчання, див. «Налаштування» нижче), або текстової інверсії (див. нижче).
Плитки — це потужний і відносно дешевий спосіб увімкнути стабільну дифузію для виведення результату високої роздільної здатності, але алгоритмічне мозаїчне масштабування такого типу, якщо йому не вистачає якогось ширшого механізму уваги на вищому рівні, може не досягти сподівань. для стандартів для різних типів вмісту.
2: Вирішення проблем із людськими кінцівками
Стабільна дифузія не відповідає своїй назві, коли зображує складність людських кінцівок. Руки можуть розмножуватися випадковим чином, пальці зливаються, треті ноги з’являються незапрошеними, а існуючі кінцівки зникають без сліду. На свій захист Stable Diffusion ділиться проблемою зі своїми партнерами по стабільній системі, і, звичайно, з DALL-E 2.

Невідредаговані результати DALL-E 2 і Stable Diffusion (1.4) наприкінці серпня 2022 року, обидва показують проблеми з кінцівками. Підказка: «Жінка обіймає чоловіка»
Прихильники Stable Diffusion, які сподіваються, що майбутня контрольна точка 1.5 (версія моделі з більш інтенсивним тренуванням і покращеними параметрами) вирішить цю плутанину, ймовірно, будуть розчаровані. Нова модель, яка буде випущена в близько двох тижнів, зараз проходить прем’єра на комерційному порталі stability.ai DreamStudio, який використовує 1.5 за замовчуванням, і де користувачі можуть порівняти новий вихід із рендерами з локальної чи іншої системи 1.4:

Джерело: Local 1.4 prepack і https://beta.dreamstudio.ai/

Джерело: Local 1.4 prepack і https://beta.dreamstudio.ai/

Джерело: Local 1.4 prepack і https://beta.dreamstudio.ai/
Як це часто буває, якість даних цілком може бути основною причиною.
Бази даних з відкритим кодом, які живлять системи синтезу зображень, такі як Stable Diffusion і DALL-E 2, здатні надати багато міток як для окремих людей, так і для дій між людьми. Ці мітки навчаються симбіозно з пов’язаними зображеннями або сегментами зображень.

Користувачі Stable Diffusion можуть досліджувати концепції, навчені в моделі, запитуючи набір даних LAION-aesthetics, підмножину більшого набору даних LAION 5B, який забезпечує роботу системи. Зображення впорядковано не за алфавітними мітками, а за їхнім «естетичним рахунком». Джерело: https://rom1504.github.io/clip-retrieval/
A хороша ієрархія Індивідуальні мітки та класи, що сприяють зображенню людської руки, будуть приблизно такими тіло>рука>кисть>пальці>[підцифри + великий палець]> [сегменти цифр]>Нігті.

Зерниста семантична сегментація частин руки. Навіть ця надзвичайно детальна деконструкція залишає кожен «пальець» єдиним цілим, не враховуючи три частини пальця та дві частини великого пальця. Джерело: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
Насправді вихідні зображення навряд чи будуть настільки послідовно анотовані в усьому наборі даних, і неконтрольовані алгоритми маркування, ймовірно, зупиняться на вище на рівні, наприклад, «руки», і залишити внутрішні пікселі (які технічно містять інформацію про «пальці») як непомічену масу пікселів, з якої будуть довільно отримані функції, і які можуть проявлятися в наступних візуалізаціях як різкий елемент.

Як це має бути (угорі праворуч, якщо не у верхній частині), і як воно має тенденцію бути (внизу праворуч) через обмежені ресурси для маркування або архітектурне використання таких міток, якщо вони існують у наборі даних.
Таким чином, якщо модель прихованої дифузії дійде до відтворення руки, вона майже напевно спробує принаймні відобразити руку на кінці цієї руки, оскільки рука>рука є мінімально необхідною ієрархією, досить високою в тому, що архітектура знає про «анатомію людини».
Після цього «пальці» можуть бути найменшою групою, хоча існує ще 14 додаткових частин пальця/великого пальця, які слід враховувати при зображенні людських рук.
Якщо ця теорія справедлива, реального виправлення немає через брак бюджету в усьому секторі для ручного анотування та відсутність достатньо ефективних алгоритмів, які могли б автоматизувати маркування, створюючи низький рівень помилок. По суті, модель наразі може покладатися на анатомічну узгодженість людини, щоб приховати недоліки набору даних, на якому вона навчалася.
Одна з можливих причин не можу покладатися на це, нещодавно запропонований на Stable Diffusion Discord, полягає в тому, що модель може заплутатися щодо правильної кількості пальців (реалістичної) людської руки, оскільки отримана від LAION база даних, що її використовує, містить героїв мультфільмів, які можуть мати менше пальців (що саме по собі ярлик, що заощаджує працю).

Два з потенційних винуватців синдрому «відсутнього пальця» в стабільній дифузії та подібних моделях. Нижче наведено приклади мультяшних рук із набору даних LAION-aesthetics, що підтримує Stable Diffusion. Джерело: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Якщо це правда, тоді єдиним очевидним рішенням є перенавчання моделі, виключення нереалістичного людського вмісту, гарантування того, що справжні випадки пропуску (тобто ампутації) відповідним чином позначені як винятки. З огляду лише на контроль даних, це було б досить складним завданням, особливо для спільноти, яка відчуває брак ресурсів.
Другий підхід полягав би у застосуванні фільтрів, які виключають такий вміст (тобто «руку з трьома/п’ятьма пальцями») від прояву під час візуалізації, майже так само, як OpenAI, певною мірою, фільтрують ГПТ-3 а ВІД-Є 2, щоб їх вихід можна було регулювати без необхідності перенавчання вихідних моделей.

Для Stable Diffusion семантичне розмежування між пальцами та навіть кінцівками може стати жахливо розмитим, нагадуючи про «тілесні жахи» фільмів жахів 1980-х років, таких як Девід Кроненберг. Джерело: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Однак, знову ж таки, для цього знадобляться мітки, які можуть не існувати на всіх зачеплених зображеннях, що залишить нас перед тими самими матеріально-технічними та бюджетними труднощами.
Можна стверджувати, що залишилося два шляхи вперед: додавання додаткових даних для вирішення проблеми та застосування сторонніх систем інтерпретації, які можуть втрутитися, коли фізичні помилки типу, описаного тут, представлені кінцевому користувачеві (принаймні, останнє дало б OpenAI спосіб відшкодовувати кошти за візуалізації «тілесних жахів», якщо компанія була на це мотивована).
3: Налаштування
Однією з найцікавіших можливостей для майбутнього Stable Diffusion є перспектива того, що користувачі чи організації розроблять переглянуті системи; модифікації, які дозволяють інтегрувати в систему вміст за межами попередньо навченої сфери LAION – в ідеалі без неконтрольованих витрат на навчання всієї моделі заново або ризику, пов’язаного з навчанням великого обсягу нових зображень на існуючому, зрілому та здатному модель.
За аналогією: якщо двоє менш обдарованих студентів приєднаються до класу з тридцяти студентів просунутого рівня, вони або асимілюються й надолужать втрачене, або зазнають невдачі як викиди; в будь-якому випадку це, ймовірно, не вплине на середню продуктивність класу. Однак якщо 15 менш обдарованих учнів приєднаються, крива оцінок для всього класу, швидше за все, постраждає.
Подібним чином, синергетична та досить делікатна мережа взаємозв’язків, які будуються в результаті тривалого та дорогого навчання моделі, може бути порушена, а в деяких випадках фактично знищена, надмірною кількістю нових даних, що знижує якість результату для моделі в усіх напрямках.
Випадок для цього в першу чергу полягає в тому, що ваш інтерес полягає в тому, щоб повністю перехопити концептуальне розуміння моделі стосунків і речей і привласнити його для ексклюзивного виробництва вмісту, подібного до додаткового матеріалу, який ви додали.
Таким чином, навчання 500,000 тис Сімпсони кадрів у існуючу контрольну точку Stable Diffusion, імовірно, зрештою, ви отримаєте краще Сімпсони симулятор, ніж могла запропонувати оригінальна збірка, припускаючи, що достатньо широкі семантичні зв’язки переживуть процес (тобто Гомер Сімпсон їсть хот-дог, для якого може знадобитися матеріал про хот-доги, якого не було у вашому додатковому матеріалі, але вже існував у контрольній точці), і припускаючи, що ви не хочете раптово переходити з Сімпсони вміст для створення казковий пейзаж Грега Рутковскі – тому що увага вашої моделі, яка пройшла навчання, була значно відвернута, і вона не буде так добре робити це, як раніше.
Одним із яскравих прикладів цього є вайфу-дифузія, який успішно після навчання 56,000 XNUMX зображень аніме у готовий і навчений контрольно-пропускний пункт Stable Diffusion. Однак це важка перспектива для любителя, оскільки для моделі потрібен приголомшливий мінімум 30 ГБ відеопам’яті, що значно перевищує те, що, ймовірно, буде доступно для споживчого рівня в майбутніх випусках NVIDIA серії 40XX.

Навчання спеціального вмісту стабільній дифузії за допомогою waifu-дифузії: моделі знадобилося два тижні після навчання, щоб вивести цей рівень ілюстрації. Шість зображень ліворуч показують хід моделі в міру навчання у створенні суб’єктно-узгодженого результату на основі нових навчальних даних. Джерело: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
На такі «вилки» контрольних точок стабільної дифузії можна було б витратити багато зусиль, але їх зупинили б технічні борги. Розробники з офіційного Discord вже зазначили, що пізніші релізи контрольних точок не обов’язково будуть сумісними із попередніми версіями, навіть із оперативною логікою, яка, можливо, працювала з попередньою версією, оскільки їх головним інтересом є отримання найкращої моделі, а не підтримка застарілі програми та процеси.
Тому компанія або особа, яка вирішила розгалужити контрольно-пропускний пункт у комерційний продукт, фактично не має шляху назад; Їхня версія моделі на даний момент є «хардфорком» і не зможе отримати переваги від пізніших випусків Stability.ai, що є серйозним зобов’язанням.
Поточна та більша надія на налаштування Stable Diffusion є Текстова інверсія, де користувач тренується в невеликій жмені CLIP- вирівняні зображення.

Спільна робота Тель-Авівського університету та NVIDIA, текстова інверсія дозволяє навчати дискретні та нові сутності, не руйнуючи можливості вихідної моделі. Джерело: https://textual-inversion.github.io/
Основним очевидним обмеженням текстової інверсії є те, що рекомендується дуже мала кількість зображень – лише п’ять. Це фактично створює обмежену сутність, яка може бути більш корисною для завдань передачі стилю, а не для вставки фотореалістичних об’єктів.
Тим не менш, зараз проводяться експерименти в різних стабільних дифузійних дискордах, які використовують набагато більшу кількість навчальних зображень, і ще належить побачити, наскільки продуктивним може виявитися метод. Знову ж таки, ця техніка вимагає багато VRAM, часу та терпіння.
Через ці обмежувальні фактори нам, можливо, доведеться почекати деякий час, щоб побачити деякі з більш складних експериментів інверсії тексту від ентузіастів Stable Diffusion – і чи зможе цей підхід «поставити вас у картину» у спосіб, який виглядає краще, ніж Photoshop вирізає та вставляє, зберігаючи вражаючу функціональність офіційних контрольно-пропускних пунктів.
Вперше опубліковано 6 вересня 2022 р.











