Штучний інтелект
SofGAN: Генератор ГАН-образів обличчя, який пропонує більший контроль
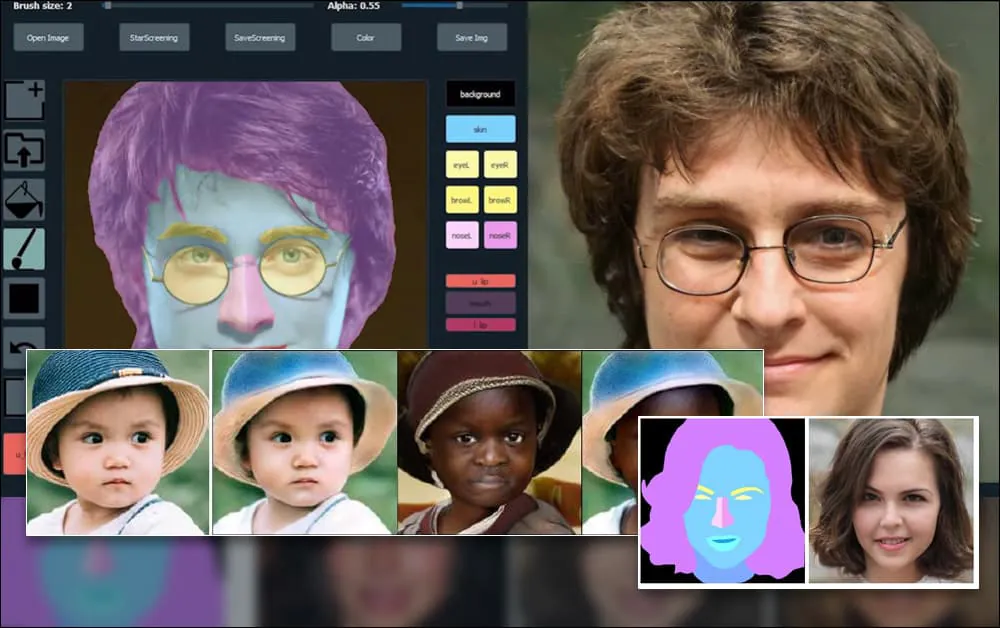
Дослідники в Шанхаї та США розробили систему генерації портретів на основі ГАН, яка дозволяє користувачам створювати нові обличчя з раніше недоступним рівнем контролю над окремими аспектами, такими як волосся, очі, окуляри, текстури та колір.
Для демонстрації універсальності системи її творці надали інтерфейс у стилі Photoshop, у якому користувач може безпосередньо малювати елементи семантичної сегментації, які будуть переінтерпретовані у реалістичні зображення, і які навіть можна отримати, малюючи безпосередньо над існуючими фотографіями.
У наведеному нижче прикладі використовується зображення актора Деніела Редкліффа як шаблон для копіювання (і метою не є створення подібності до нього, а радше загалом фотореалістичного зображення). Коли користувач заповнює різні елементи, включаючи окремі аспекти, такі як окуляри, вони ідентифікуються та інтерпретуються у виведеному зображенні:
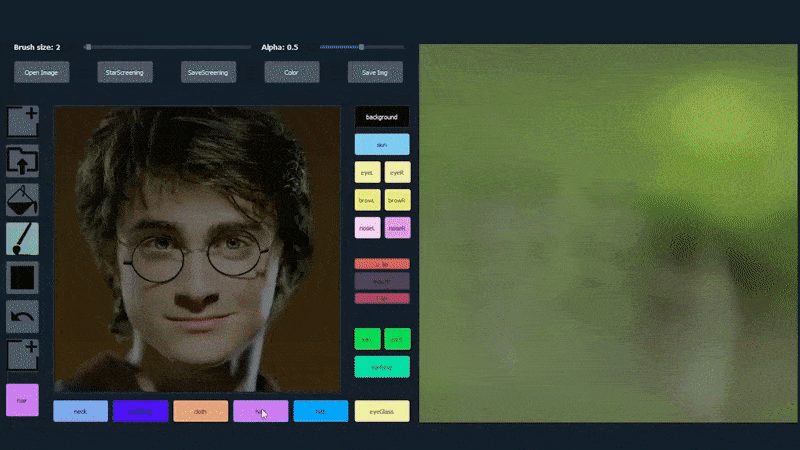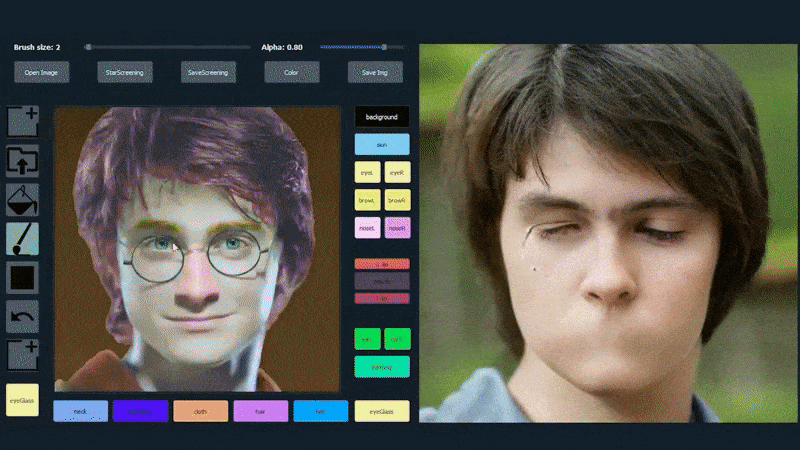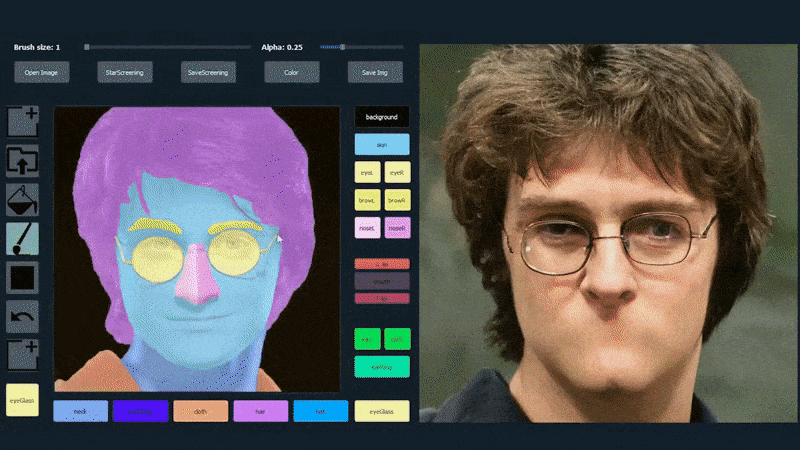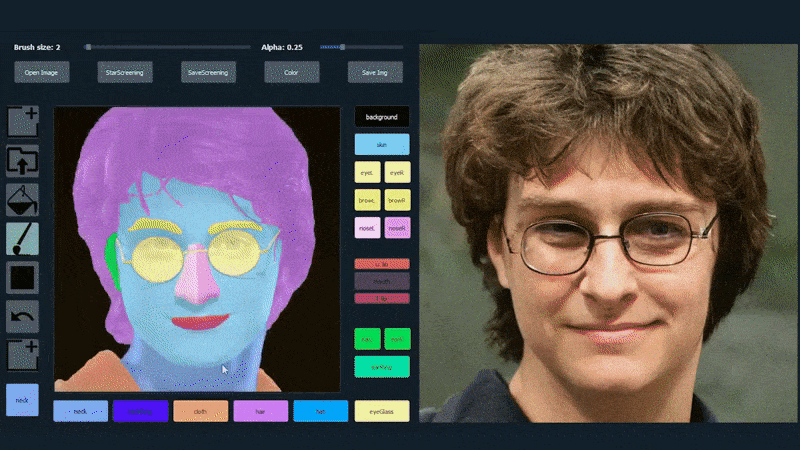
Використання одного зображення як матеріалу для копіювання для портрету, згенерованого SofGAN. Джерело: https://www.youtube.com/watch?v=xig8ZA3DVZ8
Стаття стаття називається SofGAN: Генератор портретних зображень з динамічним стилем і ведена Анпеєм Ченом і Руянгом Ліу, разом з двома іншими дослідниками з ShanghaiTech University та одним з Університету Каліфорнії в Сан-Дієго.
Розрізнення ознак
Основний внесок роботи полягає не так багато у забезпеченні зручного інтерфейсу користувача, а радше у “розрізненні” характеристик вивчених ознак обличчя, таких як поза та текстура, що дозволяє SofGAN також генерувати обличчя, які знаходяться під непрямими кутами до точки зору камери.

Незвично серед генераторів обличчя на основі Генеративних суперницьких мереж, SofGAN може змінювати кут огляду за бажанням, в межах масиву кутів, присутніх у навчальних даних. Джерело: https://arxiv.org/pdf/2007.03780.pdf
Оскільки текстури тепер розрізняються від геометрії, форму обличчя та текстуру також можна маніпулювати як окремими сутностями. По суті, це дозволяє змінювати расу джерельного обличчя, скандальну практику, яка тепер має потенційно корисне застосування для створення расово-балансированих наборів даних машинного навчання.

SofGAN також підтримує штучне старіння та коригування стилю, сумісного з атрибутами, на рівні, не баченому в подібних системах сегментації>образу, таких як GauGAN компанії NVIDIA та система нейронного рендерингу компанії Intel.

SofGAN здатний реалізовувати старіння як ітеративний стиль.
Іншим проривом для методології SofGAN є те, що навчання не вимагає парних сегментації/реальних зображень, а може бути безпосередньо навчено на непарних реальних зображеннях світу.
Дослідники заявляють, що “розрізнювальна” архітектура SofGAN була надихнута традиційними системами рендерингу зображень, які розкладають окремі аспекти зображення. У робочих процесах візуальних ефектів елементи для композиції регулярно розкладаються до найменших компонентів, з фахівцями, присвяченими кожному компоненту.
Семантичне поле зайнятості (SOF)
Для досягнення цього в рамках машинного навчання з синтезу зображень дослідники розробили семантичне поле зайнятості (SOF), розширення традиційного поля зайнятості, яке індивідуалізує компонентні елементи портретів обличчя. SOF був навчений на каліброваних багатогранних семантичних картах сегментації, але без будь-якого нагляду за ground truth.

Багаторазові ітерації з однієї карти сегментації (ліворуч внизу).
Крім того, 2D-карти сегментації отримуються шляхом трасування виводу SOF, а потім текстуруються генератором ГАН. “Синтетичні” карти семантичної сегментації також кодуються у низьковимірному просторі через тришаровий кодувальник, щоб забезпечити безперервність виводу при зміні точки зору.
Схема навчання просторово змішує два випадкові стилі для кожного семантичного регіону:

Архітектура для SofGAN.
Дослідники стверджують, що SofGAN досягає нижчої відстані Фрідета-Інсепшена (FID) ніж поточний альтернативний стан мистецтва (SOTA-підходи), а також вищої метрики схожості зображень, вивчених перцептивно (LPIPS).
Попередні підходи StyleGAN часто ускладнювалися зв’язком ознак, при якому елементи, які складають зображення, були нерозрізнювально пов’язані один з одним, що призводило до появи нежаданих елементів поряд з бажаним елементом (наприклад, сережки могли з’явитися, коли форма вуха була відтворена під впливом зображення, яке містить сережки під час навчання).

Рей-маршинг використовується для розрахунку об’єму карт семантичної сегментації, що дозволяє отримувати багаторазові точки зору.
Набори даних та навчання
Три набори даних були використані при розробці різних реалізацій SofGAN: CelebAMask-HQ, репозиторій з 30 000 високороздільних зображень, взятих з набору даних CelebA-HQ; Flickr-Faces-HQ (FFHQ) компанії NVIDIA, який містить 70 000 зображень, де дослідники позначили зображення за допомогою попередньо натренованого парсера обличчя; та самвиданний набір з 122 портретних сканів з ручними позначеннями семантичних регіонів.
SOF складається з трьох тренованих підмодулів – гіпермережі, рей-маршера (див. зображення вище) та класифікатора. Генератор StyleGAN проекту, під назвою Semantic Instance Wised (SIW), сконфігурований подібно до StyleGAN2 за певними аспектами. Розширення даних здійснюється шляхом випадкового масштабування та обрізання, а навчання відбувається з регуляризацією шляху кожні чотири кроки. Цілком навчальний процес зайняв 22 дні, щоб досягти 800 000 ітерацій на чотирьох GPU RTX 2080 Ti за допомогою CUDA 10.1.
Дослідники спостерігають, що прийнятні узагальнені, високорівневі результати почали з’являтися досить рано у навчанні, на 1500-ій ітерації, через три дні після початку навчання. Решта навчання зайняла передбачувану, повільну підходу до отримання деталей, таких як волосся та ознаки очей.
SofGAN загалом досягає більш реалістичних результатів з однієї карти сегментації, ніж суперницькі методи, такі як SPADE та Pix2PixHD компанії NVIDIA, та SEAN.

Нижче розміщено відео, випущене дослідниками. Додаткові відео, розміщені на сервері, доступні на сторінці проекту.
https://www.youtube.com/watch?v=xig8ZA3DVZ8













{kind=link}
{kind=link}