
Кут Андерсона
HunyuanCustom пропонує відео з одним зображенням та глибокими фейками, аудіо та синхронізацією губ
У цій статті обговорюється нова версія мультимодальної моделі світу Hunyuan Video під назвою «HunyuanCustom». Широта охоплення нової статті в поєднанні з кількома проблемами, наведеними в багатьох відео-прикладах, Сторінка проекту*, обмежує нас більш загальним висвітленням, ніж зазвичай, та обмеженим відтворенням величезної кількості відеоматеріалів, що супроводжують цей реліз (оскільки багато відео потребують значного повторного редагування та обробки для покращення читабельності макета).
Зверніть також увагу, що в статті генеративна система Kling на основі API називається «Keling». Для ясності я буду використовувати термін «Kling» назавжди.
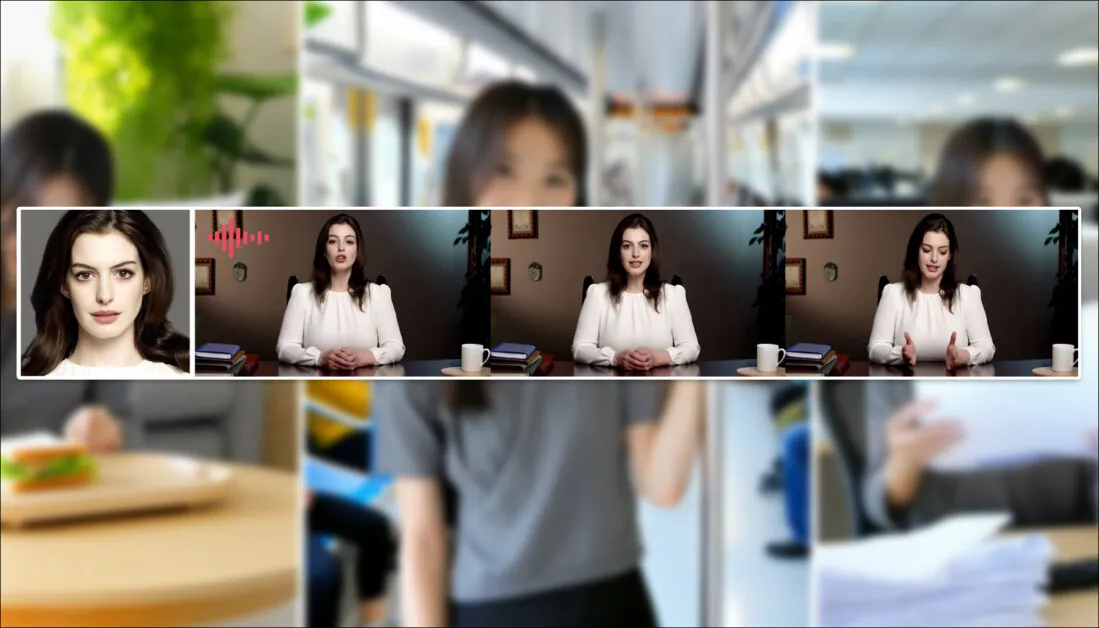
Tencent зараз випускає нову версію своєї Відео модель Hunyuan, Під назвою HunyuanCustom. Новий реліз, очевидно, здатний зробити Моделі Hunyuan LoRA надлишковий, дозволяючи користувачеві створювати відео-кастомізацію в стилі «deepfake» через один зображення:
Натисніть, щоб відтворити. Підказка: «Чоловік слухає музику та готує локшину з равликів на кухні». Новий метод порівнюють як з методами із закритим, так і з відкритим кодом, включаючи Kling, який є суттєвим опонентом у цій галузі. Джерело: https://hunyuancustom.github.io/ (попередження: сайт із інтенсивним використанням процесора/пам'яті!)
У крайньому лівому стовпці відео вище ми бачимо зображення з одного джерела, надане HunyuanCustom, а потім інтерпретацію запиту новою системою у другому стовпці поруч із ним. Решта стовпців показують результати з різних власних систем та систем FOSS: Клінг; Vidu; Піка; Хайлуо; і ВанНа основі SkyReels-A2.
У відео нижче ми бачимо рендери трьох сценаріїв, важливих для цього релізу: відповідно, людина + предмет; емуляція одного символуІ віртуальне приміряння (людина + одяг):
Натисніть, щоб відтворитиТри приклади, відредаговані з матеріалів на допоміжному сайті для Hunyuan Video.
З цих прикладів ми можемо помітити кілька речей, здебільшого пов'язаних із системою, яка спирається на зображення з одного джерела, замість кількох зображень одного й того ж об'єкта.
У першому кліпі чоловік по суті все ще стоїть обличчям до камери. Він опускає голову вниз і вбік, обертаючись не більше ніж на 20-25 градусів, але при більшому нахилі системі довелося б почати вгадувати, як він виглядає в профіль. Це важко, мабуть, неможливо точно оцінити лише за фронтальним зображенням.
У другому прикладі ми бачимо, що маленька дівчинка посміхатися на відрендереному відео так само, як і на єдиному статичному вихідному зображенні. Знову ж таки, маючи це єдине зображення як орієнтир, HunyuanCustom довелося б зробити відносно необґрунтоване припущення про те, як виглядає її «обличчя, що відпочиває». Крім того, її обличчя не відхиляється від положення, спрямованого до камери, більше, ніж у попередньому прикладі («чоловік їсть чіпси»).
В останньому прикладі ми бачимо, що оскільки вихідний матеріал – жінка та одяг, який їй пропонують одягнути – не є повними зображеннями, рендеринг обрізав сценарій, щоб він вписувався – що насправді є досить непоганим рішенням проблеми з даними!
Річ у тім, що хоча нова система може обробляти кілька зображень (таких як людина + чіпсиабо людина + одяг), це, очевидно, не дозволяє кількох ракурсів чи альтернативних точок зору одного символу, щоб можна було врахувати різноманітні вирази або незвичайні кути. Тому системі може бути важко замінити зростаючу екосистему моделей LoRA, які виросли навколо HunyuanVideo з моменту його випуску минулого грудня, оскільки це може допомогти HunyuanVideo створювати узгоджені персонажі з будь-якого ракурсу та з будь-яким виразом обличчя, представленим у навчальному наборі даних (типово 20-60 зображень).
Підключено для звуку
Для аудіо HunyuanCustom використовує LatentSync система (відомо, що її важко налаштувати аматорам та отримати хороші результати) для отримання рухів губ, що узгоджуються з аудіо та текстом, що надаються користувачем:
Містить аудіо. Натисніть, щоб відтворити. Різні приклади синхронізації губ з додаткового сайту HunyuanCustom, відредаговані разом.
На момент написання статті англійськими прикладами не було, але вони здаються досить непоганими, тим більше, якщо метод їх створення легко встановлюється та доступний.
Редагування існуючого відео
Нова система пропонує, здається, дуже вражаючі результати для редагування відео-відео (V2V або Vid2Vid), де сегмент існуючого (реального) відео маскується та інтелектуально замінюється об'єктом, заданим на одному опорному зображенні. Нижче наведено приклад із сайту додаткових матеріалів:
Натисніть, щоб відтворити. Цільовим є лише центральний об'єкт, але те, що залишається навколо нього, також змінюється під час проходу vid2vid HunyuanCustom.
Як ми бачимо, і як це стандартно у сценарії vid2vid, все відео певною мірою змінюється процесом, хоча найбільше змінюється в цільовій області, тобто в плюшевій іграшці. Ймовірно, можна розробити конвеєри для створення таких перетворень під сміттєвий матовий підхід, який залишає більшу частину відеоконтенту ідентичним оригіналу. Саме це Adobe Firefly робить «під капотом», і робить це досить добре, але це маловивчений процес у сфері генеративного FOSS.
Тим не менш, більшість наведених альтернативних прикладів краще справляються з цими інтеграціями, як ми можемо бачити у зібраній компіляції нижче:
Натисніть, щоб відтворити. Різноманітні приклади вставного контенту за допомогою vid2vid у HunyuanCustom, що демонструють помітну повагу до нецільового матеріалу.
Новий початок?
Ця ініціатива є розвитком Відеопроект Hunyuan, а не різкий відхід від цього потоку розробки. Покращення проекту представлені як окремі архітектурні вставки, а не як масштабні структурні зміни, спрямовані на те, щоб модель могла зберігати точність ідентичності в різних фреймах, не покладаючись на специфічний для предмета тонка настройка, як у випадку з LoRA або підходами текстової інверсії.
Отже, щоб було зрозуміло, HunyuanCustom не навчається з нуля, а є скоріше доопрацьованою базовою моделлю HunyuanVideo за грудень 2024 року.
Ті, хто розробляв HunyuanVideo LoRA, можуть задатися питанням, чи зможуть вони й надалі працювати з цією новою версією, чи їм доведеться винаходити велосипед LoRA. ще раз якщо вони хочуть мати більше можливостей налаштування, ніж вбудовано в цей новий випуск.
Загалом, сильно налаштований випуск гіпермасштабної моделі змінює ваги моделей достатньо, щоб LoRA, виготовлені для попередньої моделі, не працюватимуть належним чином або взагалі не працюватимуть з нещодавно вдосконаленою моделлю.
Однак іноді популярність точного налаштування може поставити під сумнів його походження: один із прикладів того, як точное налаштування стає ефективним вилка, з власною виділеною екосистемою та послідовниками, є Поні Дифузія налаштування Стабільна дифузія XL (SDXL). Наразі гру «Поні» завантажено понад 592,000 XNUMX разів. постійно змінюється Домен CivitAI з широким спектром LoRA, які використовували Pony (а не SDXL) як базову модель, і які потребують Pony під час виведення.
Звільнення
Команда Сторінка проекту для новий папір (який має назву HunyuanCustom: Мультимодальна архітектура для створення відео на замовлення) містить посилання на Сайт GitHub який, на момент написання статті, щойно став функціональним і, схоже, містить весь код та необхідні ваги для локальної реалізації, разом із запропонованим графіком (де єдиним важливим моментом ще попереду є інтеграція з ComfyUI).
На момент написання статті, проект Присутність обіймального обличчя все ще є 404. Однак існує Версія на основі API де, очевидно, можна продемонструвати систему, якщо ви можете надати код сканування WeChat.
Я рідко бачив таке складне та широке використання такого різноманіття проектів в одній збірці, як це видно в HunyuanCustom – і, ймовірно, деякі ліцензії в будь-якому разі вимагали б повного релізу.
На сторінці GitHub анонсовано дві моделі: версію 720px1280px, яка вимагає 8 ГБ пікової пам'яті GPU, та версію 512px896px, яка вимагає 60 ГБ пікової пам'яті GPU.
У сховищі зазначено «Мінімальний обсяг пам'яті графічного процесора, необхідний для 24px720px1280f, становить 129 ГБ, але дуже повільно… Для кращої якості генерації рекомендуємо використовувати графічний процесор з 80 ГБ пам'яті». – і повторює, що система поки що тестувалася лише на Linux.
Попередня модель Hunyuan Video з моменту офіційного випуску була квантований до розмірів, де його можна запускати на менш ніж 24 ГБ відеопам'яті, і здається розумним припустити, що нова модель також буде адаптована спільнотою до більш зручних для користувача форм, і що вона також буде швидко адаптована для використання в системах Windows.
Через обмеження в часі та величезну кількість інформації, що супроводжує цей реліз, ми можемо розглянути його лише ширше, а не детальніше. Тим не менш, давайте трохи розглянемо HunyuanCustom.
Погляд на папір
Конвеєр даних для HunyuanCustom, очевидно, відповідає вимогам GDPR фреймворк, включає як синтезовані, так і відеодані з відкритим кодом, зокрема OpenHumanVid, з вісьмома основними категоріями, представленими: людей, тварини, рослин, пейзажі, транспортні засоби, об'єкти, архітектура та аніме.

З релізного документа, огляд різноманітних пакетів, що беруть участь у конвеєрі побудови даних HunyuanCustom. Джерело: https://arxiv.org/pdf/2505.04512
Початкова фільтрація починається з PySceneDetect, який сегментує відео на окремі кліпи. TextBPN-Plus-Plus потім використовується для видалення відео, що містять надмірну кількість тексту на екрані, субтитрів, водяних знаків або логотипів.
Щоб вирішити проблеми невідповідностей у роздільній здатності та тривалості, кліпи стандартизовані до п'яти секунд та змінені на 512 або 720 пікселів на короткій стороні. Естетична фільтрація здійснюється за допомогою Коала-36М, з використанням спеціального порогу 0.06, застосованого до спеціального набору даних, курованого дослідниками нової статті.
Процес вилучення суб'єкта поєднує в собі Qwen7B Модель великої мови (LLM), YOLO11X фреймворк для розпізнавання об'єктів та популярний InsightFace архітектура, для ідентифікації та підтвердження людської ідентичності.
Для нелюдських суб'єктів, QwenVL та Заземлений ЗРК 2 використовуються для вилучення відповідних обмежувальних рамок, які відкидаються, якщо вони занадто малі.

Приклади семантичної сегментації за допомогою Grounded SAM 2, що використовується в проекті Hunyuan Control. Джерело: https://github.com/IDEA-Research/Grounded-SAM-2
Використовується багатосуб'єктна екстракція Флоренція2 для анотації обмежувальної рамки та Grounded SAM 2 для сегментації, а потім кластеризація та часова сегментація навчальних кадрів.
Оброблені кліпи додатково покращуються за допомогою анотацій з використанням власної системи структурованого маркування, розробленої командою Hunyuan, яка надає багатошарові метадані, такі як описи та сигнали руху камери.
Збільшення маски стратегії, включаючи перетворення на обмежувальні рамки, застосовувалися під час навчання для зменшення переобладнання та забезпечити адаптацію моделі до різних форм об'єктів.
Аудіодані синхронізувалися за допомогою вищезгаданого LatentSync, а кліпи відкидалися, якщо показники синхронізації падали нижче мінімального порогу.
Структура оцінки якості зображення для сліпих ГіперIQA використовувався для виключення відео з оцінкою нижче 40 (за спеціально розробленою шкалою HyperIQA). Потім дійсні аудіодоріжки оброблялися за допомогою Шепіт для вилучення ознак для подальших завдань.
Автори включають LLaVA модель мовного асистента на етапі анотування, і вони підкреслюють центральне місце, яке цей фреймворк займає в HunyuanCustom. LLaVA використовується для створення підписів до зображень та допомоги у вирівнюванні візуального контенту з текстовими підказками, підтримуючи побудову узгодженого навчального сигналу в різних модальностях:

Фреймворк HunyuanCustom підтримує генерацію відео, узгодженого з ідентифікацією, на основі тексту, зображень, аудіо та відео.
Використовуючи можливості LLaVA щодо узгодження візуальної мови, конвеєр отримує додатковий рівень семантичної узгодженості між візуальними елементами та їх текстовими описами, що особливо цінно в сценаріях з кількома предметами або складними сценами.
Спеціальне відео
Щоб дозволити генерацію відео на основі опорного зображення та підказки, було створено два модулі, зосереджені навколо LLaVA, спочатку адаптувавши структуру вхідних даних HunyuanVideo так, щоб він міг приймати зображення разом із текстом.
Це передбачало форматування запиту таким чином, щоб зображення вбудовувалося безпосередньо або додавалося до нього короткий опис ідентифікації. Щоб запобігти перевантаженню вмісту запиту вбудовуванням зображення, використовувався токен-роздільник.
Оскільки візуальний кодер LLaVA має тенденцію стискати або відкидати дрібнозернисті просторові деталі під час вирівнювання зображень і текстових елементів (особливо під час перетворення одного опорного зображення в загальне семантичне вбудовування), модуль покращення ідентифікації було включено. Оскільки майже всі моделі латентної дифузії відео мають певні труднощі зі збереженням ідентичності без LoRA, навіть у п'ятисекундному кліпі, продуктивність цього модуля в тестуванні спільноти може виявитися значною.
У будь-якому випадку, розмір опорного зображення потім змінюється та кодується за допомогою причинного 3D-VAE з оригінальної моделі HunyuanVideo та її латентний вставляється у відео латентно по часовій осі, із застосованим просторовим зміщенням, щоб запобігти безпосередньому відтворенню зображення на виході, водночас керуючи генерацією.
Модель була навчена з використанням Відповідність потоку, з вибірками шуму, взятими з логіт-нормальний розподіл – і мережу було навчено відновлювати правильне відео з цих зашумлених латентних сигналів. LLaVA та відеогенератор були налаштовані разом, щоб зображення та підказка могли плавніше спрямовувати вихідний сигнал та зберігати узгодженість ідентичності суб'єкта.
Для багатопредметних підказок кожна пара зображення-текст була вбудована окремо та мала чітке часове положення, що дозволяло розрізняти ідентичності та підтримувало створення сцен, що включають множинний взаємодіючі суб'єкти.
Звук і бачення
HunyuanCustom регулює генерацію аудіо/мовлення, використовуючи як аудіо, введене користувачем, так і текстові підказки, дозволяючи персонажам говорити в сценах, що відображають описане середовище.
Для підтримки цього модуль AudioNet з розв'язанням ідентифікації вводить аудіоелементи, не порушуючи сигнали ідентифікації, вбудовані в опорне зображення та підказку. Ці елементи вирівнюються зі стиснутою часовою шкалою відео, розділені на сегменти на рівні кадрів та введені за допомогою просторового... перехресна увага механізм, який ізолює кожен кадр, зберігаючи цілісність об'єкта та уникаючи часових перешкод.
Другий модуль часового введення забезпечує точніший контроль над часом та рухом, працюючи в тандемі з AudioNet, зіставляючи аудіоособливості з певними ділянками латентної послідовності та використовуючи... Багатошаровий персептрон (MLP) для перетворення їх на за токенами зміщення рухів. Це дозволяє жестам і міміці з більшою точністю слідувати ритму та акценту голосового введення.
HunyuanCustom дозволяє безпосередньо редагувати об'єкти у існуючих відео, замінюючи або вставляючи людей чи об'єкти у сцену без необхідності перебудовувати весь кліп з нуля. Це робить його корисним для завдань, які передбачають цілеспрямовану зміну зовнішнього вигляду або руху.
Натисніть, щоб відтворити. Ще один приклад з додаткового сайту.
Щоб полегшити ефективну заміну об'єктів у існуючих відео, нова система уникає ресурсомісткого підходу, який використовується в останніх методах, таких як популярний наразі... VACE, або ті, що об'єднують цілі відеопослідовності разом, надаючи перевагу стисненню опорного відео за допомогою попередньо навченого причинного 3D-VAE – вирівнюючи його з внутрішніми відеолатентами конвеєра генерації, а потім додаючи їх разом. Це робить процес відносно легким, водночас дозволяючи зовнішньому відеоконтенту керувати результатом.
Невелика нейронна мережа обробляє вирівнювання між чистим вхідним відео та шумними латентними сигналами, що використовуються під час генерації. Система тестує два способи введення цієї інформації: об'єднання двох наборів ознак перед їх повторним стисненням; та додавання ознак покадрово. Автори виявили, що другий метод працює краще та дозволяє уникнути втрати якості, зберігаючи при цьому обчислювальне навантаження незмінним.
Дані та тести
У тестах використовувалися такі метрики: модуль узгодженості ідентичності в ArcFace, який витягує вбудовування облич як з опорного зображення, так і з кожного кадру згенерованого відео, а потім обчислює середню косинусну подібність між ними; схожість предметів, надсилаючи сегменти YOLO11x до Діно 2 для порівняння; CLIP-B, вирівнювання тексту та відео, яке вимірює подібність між підказкою та згенерованим відео; знову ж таки CLIP-B, для обчислення подібності між кожним кадром та обома сусідніми кадрами та першим кадром, а також часової узгодженості; та динамічний ступінь, як визначено VBench.
Як зазначалося раніше, базовими конкурентами із закритим кодом були Hailuo; Vidu 2.0; Kling (1.6); та Pika. Конкуруючі FOSS-фреймворки були VACE та SkyReels-A2.

Оцінка продуктивності моделі, що порівнює HunyuanCustom з провідними методами налаштування відео за такими критеріями, як узгодженість ідентифікатора (Face-Sim), подібність об'єктів (DINO-Sim), вирівнювання тексту та відео (CLIP-BT), часова узгодженість (Temp-Consis) та інтенсивність руху (DD). Оптимальні та неоптимальні результати виділені жирним шрифтом та підкреслені відповідно.
З цих результатів автори стверджують:
«Наш [HunyuanCustom] досягає найкращої узгодженості ідентифікації та узгодженості об'єктів. Він також досягає порівнянних результатів у швидкому відстеженні та часовій узгодженості. [Hailuo] має найкращий бал кліпу, оскільки він може добре виконувати текстові інструкції лише з узгодженістю ідентифікації, жертвуючи узгодженістю нелюдських об'єктів (найгірший DINO-Sim). Що стосується ступеня динаміки, [Vidu] та [VACE] показують погані результати, що може бути пов'язано з малим розміром моделі».
Хоча сайт проєкту переповнений порівняльними відео (макет яких, схоже, розроблений для естетики веб-сайту, а не для зручності порівняння), наразі на ньому немає відеоеквівалента статичних результатів, зібраних разом у PDF-файлі, стосовно початкових якісних тестів. Хоча я включаю його сюди, я закликаю читача уважно ознайомитися з відео на сайті проєкту, оскільки вони дають краще уявлення про результати:

Зі статті, порівняння об'єктно-орієнтованого налаштування відео. Хоча глядач повинен (як завжди) звертатися до вихідного PDF-файлу для кращої роздільної здатності, відео на сайті проекту можуть бути більш показовим ресурсом у цьому випадку.
Автори коментують тут:
«Можна побачити, що [Vidu], [Skyreels A2] та наш метод досягають відносно хороших результатів у швидкому вирівнюванні та узгодженості об'єкта, але якість нашого відео краща, ніж у Vidu та Skyreels, завдяки хорошій продуктивності генерації відео нашою базовою моделлю, тобто [Hunyuanvideo-13B].»
«Серед комерційних продуктів, хоча [Kling] має гарну якість відео, перший кадр відео має [проблему] копіювання та вставки, а іноді об’єкт рухається занадто швидко та [розмивається], що призводить до поганого враження від перегляду».
Автори також зазначають, що Pika погано справляється з питанням часової узгодженості, створюючи артефакти субтитрів (ефекти поганої курації даних, коли текстовим елементам у відеокліпах дозволено забруднювати основні концепції).
Вони стверджують, що Hailuo зберігає ідентичність обличчя, але не може забезпечити повну цілісність тіла. Серед методів з відкритим кодом VACE, як стверджують дослідники, не здатний підтримувати цілісність ідентичності, тоді як HunyuanCustom, на їхню думку, створює відео з високим рівнем збереження ідентичності, зберігаючи при цьому якість та різноманітність.
Далі були проведені випробування для багатосуб'єктне налаштування відео, проти тих самих конкурентів. Як і в попередньому прикладі, результати зведеного PDF-файлу не є друкованими еквівалентами відео, доступних на сайті проекту, але є унікальними серед представлених результатів:

Порівняння з використанням багатосуб'єктних відео-налаштувань. Будь ласка, дивіться PDF для отримання детальнішої інформації та роздільної здатності.
У папері зазначено:
«[Pika] може генерувати зазначені об'єкти, але демонструє нестабільність у відеокадрах, зокрема в одному зі сценаріїв чоловік зникає, а жінка не відчиняє двері, як це підказує. [Vidu] та [VACE] частково фіксують людську ідентичність, але втрачають значні деталі нелюдських об'єктів, що вказує на обмеження у представленні нелюдських об'єктів».
«[SkyReels A2] відчуває серйозну нестабільність кадру, з помітними змінами в чіпах та численними артефактами у правильному сценарії».
«Натомість, наш HunyuanCustom ефективно фіксує як людські, так і нелюдські ідентифікаційні дані, створює відео, що відповідають заданим підказкам, та підтримує високу візуальну якість і стабільність».
Подальшим експериментом була «віртуальна людська реклама», у якій фреймворкам було доручено інтегрувати продукт з людиною:

Приклади нейронного «розміщення продукту» з раунду якісного тестування. Будь ласка, дивіться PDF для отримання детальнішої інформації та роздільної здатності.
Для цього раунду автори заявляють:
«[Результати] демонструють, що HunyuanCustom ефективно зберігає ідентичність людини, зберігаючи при цьому деталі цільового продукту, включаючи текст на ньому».
«Крім того, взаємодія між людиною та продуктом виглядає природною, а відео точно відповідає заданому заголовку, що підкреслює значний потенціал HunyuanCustom у створенні рекламних відео».
Однією з областей, де відеорезультати були б дуже корисними, був якісний раунд для аудіо-орієнтованої кастомізації об'єктів, де персонаж озвучує відповідний звук зі сцени та пози, описаних у тексті.

Наведено часткові результати для аудіо-раунду, хоча в цьому випадку відеорезультати могли б бути кращими. Тут відтворено лише верхню половину рисунка у форматі PDF, оскільки він великий і його важко вмістити в цій статті. Будь ласка, зверніться до вихідного PDF-файлу для отримання детальнішої інформації та роздільної здатності.
Автори стверджують:
Попередні методи анімації людини на основі аудіо вводили зображення людини та аудіо, де постава, одяг та середовище людини залишалися узгодженими з заданим зображенням і не могли генерувати відео в інших жестах та середовищі, що може [обмежувати] їхнє застосування.
«…[Наш] HunyuanCustom дозволяє налаштовувати анімацію людини на основі аудіо, де персонаж вимовляє відповідний звук у сцені та позі, описаних текстом, що забезпечує більш гнучку та керовану анімацію людини на основі аудіо».
Подальші тести (докладніше дивіться у PDF-файлі) включали порівняння нової системи з VACE та Kling 1.6 для заміни об'єкта відео:

Тестування заміни об'єкта в режимі відео-відео. Будь ласка, зверніться до вихідного PDF-файлу для отримання детальнішої інформації та роздільної здатності.
З цих останніх тестів, представлених у новій статті, дослідники вважають:
«VACE страждає від артефактів на межі зображення через суворе дотримання масок введення, що призводить до неприродних форм об’єктів та порушення безперервності руху. [Kling], навпаки, демонструє ефект копіювання та вставки, коли об’єкти безпосередньо накладаються на відео, що призводить до поганої інтеграції з фоном».
«Для порівняння, HunyuanCustom ефективно уникає артефактів на межі, досягає безшовної інтеграції з відеофоном та забезпечує надійне збереження ідентичності, демонструючи свою чудову продуктивність у завданнях відеомонтажу».
Висновок
Це захопливий реліз, не в останню чергу тому, що він вирішує проблему, на яку останнім часом все частіше скаржиться вічно незадоволена спільнота любителів – відсутність синхронізації губ, завдяки чому підвищений реалізм, можливий у таких системах, як Hunyuan Video та Wan 2.1, може отримати новий вимір автентичності.
Хоча розташування майже всіх порівняльних відеоприкладів на сайті проекту досить ускладнює порівняння можливостей HunyuanCustom з попередніми конкурентами, слід зазначити, що дуже й дуже мало проектів у сфері відеосинтезу мають сміливість випробувати Kling, комерційний API для поширення відео, який завжди перебуває на вершині рейтингів або поблизу них; Tencent, схоже, досяг успіху в порівнянні з цим чинним конкурентом досить вражаючим чином.
* Проблема полягає в тому, що деякі відео настільки широкі, короткі та мають високу роздільну здатність, що вони не відтворюються у стандартних відеоплеєрах, таких як VLC або Windows Media Player, показуючи чорні екрани.
Вперше опубліковано у четвер, 8 травня 2025 року











