Спроможність генерувати 3D цифрові активи з текстових підказок представляє одну з найцікавіших недавніх розробок у сфері штучного інтелекту та комп’ютерної графіки. Оскільки ринок 3D цифрових активів очікується зросте з $28.3 млрд у 2024 році до $51.8 млрд до 2029 року, моделі генерації 3D з тексту готуються революціонізувати створення контенту в галузях, таких як ігри, кіно, електронна комерція та інші. Але як саме працюють ці системи штучного інтелекту? У цій статті ми глибоко зануримося у технічні деталі генерації 3D з тексту.
Виходи генерації 3D
Генерація 3D активів з тексту – значно складніше завдання, ніж генерація 2D зображень. Хоча 2D зображення є суттєво ґратками пікселів, 3D активи вимагають представлення геометрії, текстур, матеріалів та часто анімацій у тривимірному просторі. Ця додана вимірність і складність робить завдання генерації значно складніше.
Деякі ключові виклики генерації 3D з тексту включають:
Представлення 3D геометрії та структури
Генерація послідовних текстур та матеріалів по всій поверхні 3D
Забезпечення фізичної правдоподібності та узгодженості з різних точок зору
Захоплення тонких деталей та глобальної структури одночасно
Генерація активів, які можна легко візуалізувати або друкувати у 3D
Для подолання цих викликів моделі генерації 3D з тексту використовують кілька ключових технологій та технік.
Ключові компоненти систем генерації 3D з тексту
Більшість сучасних систем генерації 3D з тексту мають кілька спільних компонентів:
Кодування тексту: Перетворення вхідної текстової підказки у числове представлення
Представлення 3D: Метод представлення 3D геометрії та вигляду
Генеративна модель: Основна модель штучного інтелекту для генерації 3D активу
Візуалізація: Перетворення представлення 3D у 2D зображення для візуалізації
Давайте розглянемо кожен з цих компонентів детальніше.
Кодування тексту
Перший крок – перетворення вхідної текстової підказки у числове представлення, яке може обробляти модель штучного інтелекту. Це зазвичай робиться за допомогою великих мовних моделей, таких як BERT або GPT.
Представлення 3D
Існує кілька загальних способів представлення 3D геометрії у моделях штучного інтелекту:
Воксельні ґратки: 3D масиви значень, що представляють зайнятість або особливості
Хмари точок: Набори 3D точок
Сітки: Верхівки та грані, що визначають поверхню
Неявні функції: Неперервні функції, що визначають поверхню (напр., функції підписаних відстаней)
Кожен з них має компроміси щодо роздільної здатності, використання пам’яті та легкості генерації. Багато сучасних моделей використовують неявні функції або NeRFs, оскільки вони дозволяють отримувати високоякісні результати з прийнятними обчислювальними вимогами.
Наприклад, ми можемо представити просту сферу як функцію підписаної відстані:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Оцінка SDF у 3D точці
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Відстань до поверхні сфери: {distance}")
Генеративна модель
Ядро системи генерації 3D з тексту – генеративна модель, яка створює 3D актив з вкладення тексту. Більшість сучасних моделей використовують деяку варіацію дифузійної моделі, подібну до тих, що використовуються у генерації 2D зображень.
Дифузійні моделі працюють шляхом поступового додавання шуму до даних, а потім навчання для зворотного процесу. Для генерації 3D це відбувається у просторі обраного представлення 3D.
Упрощений псевдокод для кроку навчання дифузійної моделі може виглядати так:
def diffusion_training_step(model, x_0, text_embedding):
# Виберіть випадковий крок часу
t = torch.randint(0, num_timesteps, (1,))
# Додайте шум до вхідних даних
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# Прогнозуйте шум
predicted_noise = model(x_t, t, text_embedding)
# Обчислити втрату
loss = F.mse_loss(noise, predicted_noise)
return loss
# Петля навчання
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
Під час генерації ми починаємо з чистого шуму та ітеративно очищуємо, умовно на вкладенні тексту.
Візуалізація
Для візуалізації результатів та обчислення втрат під час навчання нам потрібно візуалізувати наше представлення 3D у 2D зображення. Це зазвичай робиться за допомогою диференційовних методів візуалізації, які дозволяють градієнтам повертатися через процес візуалізації.
Для представлень на основі сіток ми можемо використовувати рестеризаційний рендерер:
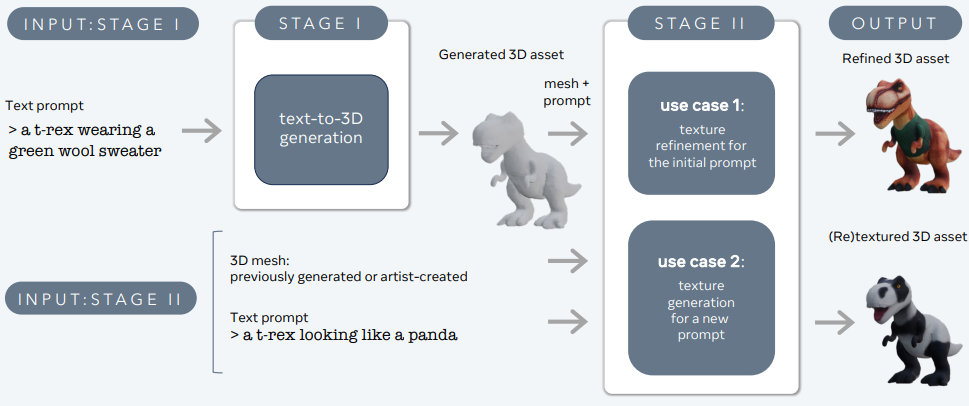
3DGen підтримує фізично засноване візуалізація (PBR), яке є важливим для реалістичного освітлення 3D активів у реальних додатках. Він також дозволяє генеративне перефарбовування раніше згенерованих або створених художником 3D форм за допомогою нових текстових вхідних даних. Потік інтегрує два основних компоненти: Meta 3D AssetGen і Meta 3D TextureGen, які обробляють генерацію 3D активів з тексту та генерацію текстур відповідно.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) відповідає за початкову генерацію 3D активів з текстових підказок. Цей компонент генерує 3D сітку з текстурами та картами матеріалів PBR приблизно за 30 секунд.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) уточнює текстури, згенеровані AssetGen. Він також може генерувати нові текстури для існуючих 3D сіток на основі додаткових текстових описів. Цей етап займає приблизно 20 секунд.
Point-E (OpenAI)
Point-E, розроблений OpenAI, – ще одна помітна модель генерації 3D з тексту. На відміну від DreamFusion, яка генерує представлення NeRF, Point-E генерує 3D хмари точок.
Ключові особливості Point-E:
а) Двостадійний потік: Point-E спочатку генерує синтетичний 2D вигляд за допомогою дифузійної моделі тексту-у-зображення, а потім використовує це зображення для умовної генерації другої дифузійної моделі, яка генерує 3D хмару точок.
б) Ефективність: Point-E розроблений для того, щоб бути обчислювально ефективним, здатним генерувати 3D хмари точок за секунди на одному GPU.
в) Кольорова інформація: Модель може генерувати кольорові хмари точок, зберігаючи як геометричну, так і інформацію про вигляд.
Обмеження:
Нижча якість порівняно з підходами, заснованими на сітках або NeRF
Хмари точок вимагають додаткової обробки для багатьох подальших додатків
Shap-E (OpenAI):
Розроблений на основі Point-E, OpenAI представив Shap-E, який генерує 3D сітки замість хмар точок. Це вирішує деякі обмеження Point-E, зберігаючи при цьому обчислювальну ефективність.
б) Видобуток сітки: Модель використовує диференційовну реалізацію алгоритму маршу кубів для перетворення неявного представлення у полігональну сітку.
в) Генерація текстур: Shap-E також може генерувати текстури для 3D сіток, що призводить до візуально привабливіших результатів.
Переваги:
Швидке генерація (секунди до хвилин)
Пряме вивід сітки, придатне для візуалізації та подальших додатків
Спроможність генерувати і геометрію, і текстуру
GET3D (NVIDIA):
GET3D, розроблений дослідниками NVIDIA, – ще одна потужна модель генерації 3D з тексту, яка фокусується на генерації високоякісних текстурированих 3D сіток.
Ключові особливості GET3D:
а) Явне представлення поверхні: На відміну від DreamFusion або Shap-E, GET3D прямо генерує явні представлення поверхні (сітки) без проміжних неявних представлень.
б) Генерація текстур: Модель включає диференційовну техніку візуалізації для навчання та генерації високоякісних текстур для 3D сіток.
в) Архітектура, заснована на GAN: GET3D використовує підхід генеративно-змагального мережевого навчання (GAN), який дозволяє швидко генерувати результати після навчання моделі.
Переваги:
Високоякісна геометрія та текстури
Швидке висновок
Пряме інтегрування з 3D рендеринговими двигунами
Обмеження:
Вимагає 3D тренувальних даних, які можуть бути рідкісними для деяких категорій об’єктів
Висновок
Генерація 3D з тексту представляє фундаментальну зміну у створенні та взаємодії з 3D контентом. Використовуючи передові техніки глибинного навчання, ці моделі можуть створювати складні, високоякісні 3D активи з простих текстових описів. По мірі розвитку технології ми можемо очікувати побачити все більш складні та потужні системи генерації 3D з тексту, які революціонізуватимуть галузі від ігор та кіно до дизайну продукції та архітектури.
Я провів останні п'ять років, занурючись у захопливий світ машинного навчання та глибокого навчання. Моя пристрасть та експертиза привели мене до внеску у понад 50 різноманітних проектів програмної інженерії, з особливим акцентом на AI/ML. Моя триваюча цікавість також привела мене до обробки природної мови, галузі, яку я бажаю дослідити далі.