Artificiell intelligens
Enfabrica Avslöjar Ethernet-baserad Minnesväv som Kan Omdefiniera AI-slutledning i Stor Skala
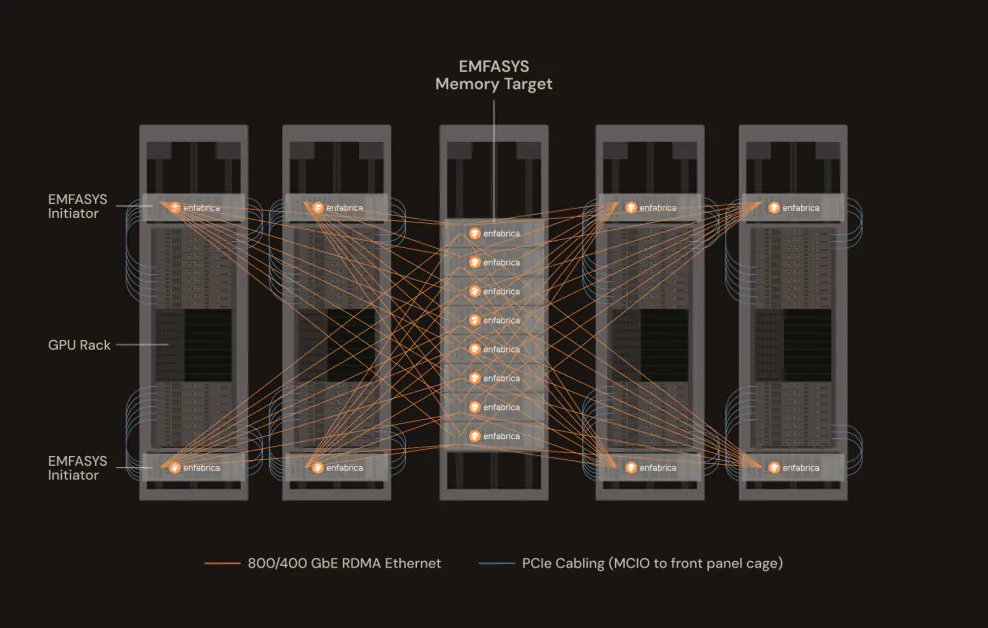
Enfabrica, ett startup-företag i Silicon Valley som backas av Nvidia, har avslöjat en banbrytande produkt som kan förändra hur storskaliga AI-arbetsbelastningar distribueras och skalar. Företagets nya Elastic Memory Fabric System (EMFASYS) är den första kommersiellt tillgängliga Ethernet-baserade minnesväven som är specifikt utformad för att lösa den centrala flaskhalsen för generativ AI-slutledning: minnesåtkomst.
Vid en tidpunkt då AI-modeller blir alltmer komplexa, kontextmedvetna och beständiga – och kräver stora mängder minne per användarsession – levererar EMFASYS en ny approach för att koppla loss minne från beräkning, vilket gör att AI-datacenter kan förbättra prestanda, sänka kostnader och öka utnyttjandet av sina dyraste resurser: GPU:er.
Vad är en Minnesväv – och Varför är Den Viktig?
Traditionellt har minne inom datacenter varit tätt bundet till den server eller nod som det finns i. Varje GPU eller CPU har endast tillgång till det höghastighetsminne som är direkt kopplat till den – vanligtvis HBM för GPU:er eller DRAM för CPU:er. Denna arkitektur fungerar bra när arbetsbelastningar är små och förutsägbara. Men generativ AI har förändrat spelet. LLM:er kräver tillgång till stora kontextfönster, användarhistorik och multiagentminne – allt detta måste bearbetas snabbt och utan fördröjning. Dessa minneskrav överstiger ofta den tillgängliga kapaciteten för lokalt minne, vilket skapar flaskhalsar som strandar GPU-kärnor och ökar infrastrukturkostnaderna.
En minnesväv löser detta genom att omvandla minne till en delad, distribuerad resurs – en sorts nätverksansluten minnepool som är tillgänglig för varje GPU eller CPU i klustret. Tänk på det som att skapa en “minnemoln” inom datacenter-hyllan. Istället för att replikera minne över servrar eller överbelasta dyrt HBM, tillåter en väv att minne kan aggregeras, disaggregeras och åtkommas på begäran via ett höghastighetsnätverk. Detta gör att AI-slutledningsarbetsbelastningar kan skalas mer effektivt utan att vara begränsade av de fysiska minnesbegränsningarna för en enskild nod.
Enfabricas Tillvägagångssätt: Ethernet och CXL, Tillsammans för Första Gången
EMFASYS uppnår denna rack-skala minnesarkitektur genom att kombinera två kraftfulla teknologier: RDMA över Ethernet och Compute Express Link (CXL). Den förra möjliggör ultra-låg-latens, hög-genomströmning dataöverföring över standard-Ethernet-nätverk. Den senare tillåter minne att kopplas loss från CPU:er och GPU:er och poolas till delade resurser, åtkomliga via höghastighets-CXL-länkar.
I kärnan av EMFASYS finns Enfabricas ACF-S-chip, en 3,2 terabit-per-sekund (Tbps) “SuperNIC” som sammanfogar nätverk och minneskontroll till en enda enhet. Denna chip tillåter servrar att gränssnitt med massiva pooler av kommersiellt tillgängligt DDR5 DRAM – upp till 18 terabyte per nod – distribuerat över hela hyllan. Avgörande är att det gör detta med hjälp av standard-Ethernet-portar, vilket gör att operatörer kan utnyttja sin befintliga datacenter-infrastruktur utan att investera i proprietära interconnects.
Vad som gör EMFASYS särskilt övertygande är dess förmåga att dynamiskt avlasta minnesbundna arbetsbelastningar från dyrt GPU-anslutet HBM till betydligt mer prisvärda DRAM, samtidigt som det upprätthåller mikrosekundnivå-åtkomstlatens. Programvarustacken bakom EMFASYS innehåller intelligent cachelagring och lastbalanseringsmekanismer som döljer latens och orkestrerar minnesrörelse på sätt som är transparenta för LLM:erna som körs på systemet.
Konsekvenser för AI-branschen
Detta är mer än bara en smart hårdvarulösning – det representerar en filosofisk förändring i hur AI-infrastruktur byggs och skalar. När generativ AI går från nyhet till nödvändighet, med miljarder användarfrågor som bearbetas dagligen, har kostnaden för att betjäna dessa modeller blivit ohållbar för många företag. GPU:er är ofta underutnyttjade inte på grund av brist på beräkning, utan för att de sitter inaktiva och väntar på minne. EMFASYS löser denna obalans direkt.
Genom att möjliggöra poolad, väv-ansluten minne som är åtkomlig via Ethernet, erbjuder Enfabrica datacenter-operatörer en skalbar alternativ till att kontinuerligt köpa fler GPU:er eller HBM. Istället kan de öka minneskapaciteten modulärt, med hjälp av standard-DRAM och intelligent nätverk, vilket minskar den totala fotavtrycket och förbättrar ekonomin för AI-slutledning.
Konsekvenserna går utöver omedelbara kostnadsbesparingar. Denna typ av disaggregerad arkitektur banar väg för minne-som-en-tjänst-modeller, där kontext, historik och agent-tillstånd kan bestå utöver en enskild session eller server, och öppnar dörren för mer intelligenta och personliga AI-system. Det sätter också scenen för mer resilienta AI-moln, där arbetsbelastningar kan distribueras elastiskt över en hel hylla eller ett helt datacenter utan rigida minnesbegränsningar.
Blickar Framåt
Enfabricas EMFASYS provas för närvarande med utvalda kunder, och även om företaget inte har avslöjat vilka dessa partners är, Reuters rapporterar att stora AI-molnleverantörer redan testar systemet. Detta positionerar Enfabrica inte bara som en komponentleverantör, utan som en nyckelaktör i nästa generation av AI-infrastruktur.
Genom att koppla loss minne från beräkning och göra det tillgängligt över höghastighets-, kommersiella Ethernet-nätverk, lägger Enfabrica grunden för en ny era av AI-arkitektur – en där slutledning kan skalas utan kompromiss, där resurser inte längre är strandsatta, och där ekonomin för att distribuera stora språkmodeller slutligen börjar göra sig gällande.
I en värld som alltmer definieras av kontextrika, multiagent AI-system är minne inte längre en biroll – det är scenen. Och Enfabrica satsar på att den som bygger den bästa scenen kommer att definiera prestandan för AI under många år framöver.












