Artificiell intelligens
Direkt Preferensoptimering: En Komplett Guide

Att anpassa stora språkmodeller (LLM) till mänskliga värderingar och preferenser är utmanande. Traditionella metoder, såsom Reinforcement Learning from Human Feedback (RLHF), har banat väg genom att integrera mänskliga indata för att förädla modellutdata. Men RLHF kan vara komplext och resurskrävande, vilket kräver betydande beräkningskraft och datahantering. Direkt Preferensoptimering (DPO) framträder som en ny och mer strömlinjeformad approach, som erbjuder en effektiv alternativ till dessa traditionella metoder. Genom att förenkla optimeringsprocessen minskar DPO inte bara den beräkningsmässiga bördan, utan förbättrar också modellens förmåga att anpassa sig snabbt till mänskliga preferenser
I den här guiden kommer vi att dyka djupt in i DPO, utforska dess grunder, implementering och praktiska tillämpningar.
Behovet av Preferensanpassning
För att förstå DPO är det avgörande att förstå varför anpassning av LLM till mänskliga preferenser är så viktigt. Trots deras imponerande förmågor kan LLM som tränats på stora datamängder ibland producera utdata som är inkonsekventa, fördomsfulla eller inte anpassade till mänskliga värderingar. Denna icke-anpassning kan manifestera sig på olika sätt:
- Generera osäkra eller skadliga innehåll
- Tillhandahålla ofullständig eller vilseledande information
- Visa fördomar som finns i träningsdata
För att hantera dessa problem har forskare utvecklat tekniker för att finjustera LLM med mänsklig feedback. Den mest framträdande av dessa tillvägagångssätt har varit RLHF.
Förstå RLHF: Föregångaren till DPO
Reinforcement Learning from Human Feedback (RLHF) har varit den vanligaste metoden för att anpassa LLM till mänskliga preferenser. Låt oss bryta ned RLHF-processen för att förstå dess komplexitet:
a) Övervakad finjustering (SFT): Processen börjar med att finjustera en förtränad LLM på en datamängd med högkvalitativa svar. Detta steg hjälper modellen att generera mer relevanta och sammanhängande utdata för måluppgiften.
b) Belöningsmodellering: En separat belöningsmodell tränas för att förutsäga mänskliga preferenser. Detta innefattar:
- Generera svarspar för givna uppmaningar
- Låta människor bedöma vilket svar de föredrar
- Träna en modell för att förutsäga dessa preferenser
c) Reinforcement Learning: Den finjusterade LLM optimeras sedan ytterligare med hjälp av reinforcement learning. Belöningsmodellen tillhandahåller feedback, vilket vägleder LLM att generera svar som anpassar sig till mänskliga preferenser.
Här är en förenklad Python-pseudokod för att illustrera RLHF-processen:
Även om det är effektivt har RLHF flera nackdelar:
- Det kräver tränning och underhåll av flera modeller (SFT, belöningsmodell och RL-optimerad modell)
- RL-processen kan vara instabil och känslig för hyperparametrar
- Det är beräkningsmässigt dyrt, vilket kräver många framåt- och bakåtpasseringar genom modellerna
Dessa begränsningar har motiverat sökandet efter enklare och mer effektiva alternativ, vilket har lett till utvecklingen av DPO.
Direkt Preferensoptimering: Kärnkoncept

Direkt Preferensoptimering https://arxiv.org/abs/2305.18290
Den här bilden kontrasterar två olika tillvägagångssätt för att anpassa LLM-utdata till mänskliga preferenser: Reinforcement Learning from Human Feedback (RLHF) och Direkt Preferensoptimering (DPO). RLHF förlitar sig på en belöningsmodell för att vägleda språkmodellens policy genom iterativa feedbackloopar, medan DPO optimerar modellutdata direkt för att matcha mänskligt föredragna svar med hjälp av preferensdata. Denna jämförelse belyser styrkorna och potentiella tillämpningar av varje metod, vilket ger insikt i hur framtida LLM kan tränas för att bättre anpassa sig till mänskliga förväntningar.
Nyckelidéer bakom DPO:
a) Implicit Belöningsmodellering: DPO eliminerar behovet av en separat belöningsmodell genom att behandla språkmodellen som en implicit belöningsfunktion.
b) Policybaserad Formulering: Istället för att optimera en belöningsfunktion optimerar DPO direkt policyn (språkmodellen) för att maximera sannolikheten för föredragna svar.
c) Sluten Formulering: DPO utnyttjar en matematisk insikt som möjliggör en sluten lösning för den optimala policyn, vilket undviker behovet av iterativa RL-uppdateringar.
Implementering av DPO: En Praktisk Kodbegäran
Bilden nedan visar en kodsnutt som implementerar DPO-förlustfunktionen med hjälp av PyTorch. Denna funktion spelar en avgörande roll för att finslipa hur språkmodeller prioriterar utdata baserat på mänskliga preferenser. Här är en genomgång av de viktigaste komponenterna:
- Funktionsignatur:
dpo_loss-funktionen tar in flera parametrar, inklusive policylogprobabiliteter (pi_logps), referensmodelllogprobabiliteter (ref_logps) och index som representerar föredragna och icke-föredragna slutföranden (yw_idxs,yl_idxs). Dessutom kontrollerarbeta-parametern styrkan på KL-straffet. - Logprobabilitetsutvinning: Koden utvinner logprobabiliteterna för föredragna och icke-föredragna slutföranden från både policy- och referensmodellerna.
- Logförhållandsberäkning: Skillnaden mellan logprobabiliteter för föredragna och icke-föredragna slutföranden beräknas för både policy- och referensmodellerna. Detta förhållande är avgörande för att bestämma riktning och storlek på optimeringen.
- Förlust- och belöningsberäkning: Förlusten beräknas med hjälp av
logsigmoid-funktionen, medan belöningar bestäms genom att skalera skillnaden mellan policy- och referenslogprobabiliteter medbeta.

DPO-förlustfunktion med PyTorch
Låt oss dyka in i matematiken bakom DPO för att förstå hur det uppnår dessa mål.
Matematiken bakom DPO
DPO är en smart omformulering av preferensinlärningsproblemet. Här är en steg-för-steg-genomgång:
a) Utgångspunkt: KL-begränsad Belöningsmaximering
Det ursprungliga RLHF-målet kan uttryckas som:
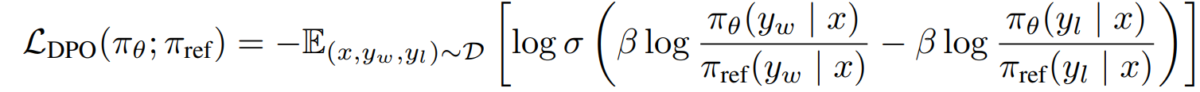
- πθ är policyn (språkmodellen) som vi optimerar
- r(x,y) är belöningsfunktionen
- πref är en referenspolicy (vanligtvis den initiala SFT-modellen)
- β kontrollerar styrkan på KL-avvikelsebegränsningen
b) Optimal Policiform: Det kan visas att den optimala policyn för detta mål har formen:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Där Z(x) är en normaliseringskonstant.
c) Belönings-Policy-Dualitet: DPO:s nyckelinsikt är att uttrycka belöningsfunktionen i termer av den optimala policyn:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Preferensmodell Antagande att preferenser följer Bradley-Terry-modellen, kan vi uttrycka sannolikheten för att föredra y1 framför y2 som:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Där σ är den logistiska funktionen.
e) DPO-Mål Genom att ersätta vår belönings-policy-dualitet i preferensmodellen, kommer vi fram till DPO-målet:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Detta mål kan optimeras med hjälp av standard gradientnedstigningstekniker, utan behov av RL-algoritmer.
Implementering av DPO
Nu när vi förstår teorin bakom DPO, låt oss se hur man implementerar det i praktiken. Vi kommer att använda Python och PyTorch för det här exemplet:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Varje par av (yw_idxs[i], yl_idxs[i]) representerar indexen för ett enda preferenspar.
"""
# Utvinna logprobabiliteter för föredragna och icke-föredragna slutföranden
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Beräkna logförhållanden
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Beräkna DPO-förlust
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Beräkna logprobabiliteter för modellen och referensmodellen
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Beräkna förlusten
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Användning
model = YourLanguageModel() # Initiera din modell
ref_model = YourLanguageModel() # Ladda förtränad referensmodell
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Förlust: {loss}")
<h3>Utmaningar och Framtida Riktningar</h3>
Medan DPO erbjuder betydande fördelar jämfört med traditionella RLHF-metoder, finns det fortfarande utmaningar och områden för ytterligare forskning:
<h4>a) Skalbarhet till Större Modeller:</h4>
När språkmodeller fortsätter att växa i storlek, kvarstår utmaningen att effektivt tillämpa DPO på modeller med hundratals miljarder parametrar. Forskare undersöker tekniker som:
<ul>
<li><strong>Effektiva finjusteringsmetoder (t.ex. LoRA, prefixjustering)</strong></li>
<li><strong>Distribuerad träningsoptimering</strong></li>
<li><strong>Gradientkontroll och blandad precisionsträning</strong></li>
</ul>
Exempel på att använda LoRA med DPO:
[code language="PYTHON"]
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Användning
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
<h4>b) Multi-Task och Few-Shot-Anpassning:</h4>
Utveckling av DPO-tekniker som kan anpassa sig effektivt till nya uppgifter eller domäner med begränsad preferensdata är ett aktivt forskningsområde. Tillvägagångssätt som undersöks inkluderar:
<ul>
<li><strong>Meta-lärande-ramverk för snabb anpassning</strong></li>
<li><strong>Promptbaserad finjustering för DPO</strong></li>
<li><strong>Överföringslärande från allmänna preferensmodeller till specifika domäner</strong></li>
</ul>
<h4>c) Hantering av Tvetydiga eller Motstridiga Preferenser:</h4>
Verkliga preferensdata innehåller ofta tvetydigheter eller motstridigheter. Förbättring av DPO:s robusthet mot sådan data är avgörande. Potentiella lösningar inkluderar:
<ul>
<li><strong>Probabilistisk preferensmodellering</strong></li>
<li><strong> Aktivt lärande för att lösa tvetydigheter</strong></li>
<li><strong>Multi-agent-preferensaggregering</strong></li>
</ul>
Exempel på probabilistisk preferensmodellering:
<div class="dark bg-gray-950 rounded-md border-[0.5px] border-token-border-medium">
[code language="PYTHON"]
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Beräkna logförhållanden
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Användning
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% förtroende för preferens
d) Kombinera DPO med Andra Anpassningstekniker:
Integrering av DPO med andra anpassningsmetoder kan leda till mer robusta och kapabla system:
- Konstitutionella AI-principer för explicit begränsningstillfredsställelse
- Debatt och rekursiv belöningsmodellering för komplex preferensutvinning
- Invers belöningslärande för att härleda underliggande belöningsfunktioner
Exempel på att kombinera DPO med konstitutionell AI:
class ConstitutionalDPOTrainer(DPOTrainer): def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None): super().__init__(model, ref_model, beta, lr) self.constraints = constraints or [] def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs): base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs) constraint_loss = 0 for constraint in self.constraints: constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs) return base_loss + constraint_loss # Användning def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs): # Implementera säkerhetskontrolllogik unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps) return torch.relu(unsafe_score - 0.5) # Straffa om osäkerhetspoäng > 0.5 constraints = [safety_constraint] trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Praktiska Överväganden och Bästa Praxis
När du implementerar DPO för verkliga tillämpningar, överväg följande tips:
a) Datakvalitet: Kvaliteten på din preferensdata är avgörande. Se till att din datamängd:
- Täcker en bred variation av indata och önskade beteenden
- Har konsekventa och tillförlitliga preferensannoteringar
- Balanserar olika typer av preferenser (t.ex. faktualitet, säkerhet, stil)
b) Hyperparameterjustering: Även om DPO har färre hyperparametrar än RLHF, är justering fortfarande viktig:
- β (beta): Kontrollerar avvägningen mellan preferensuppfyllelse och avvikelse från referensmodellen. Börja med värden runt 0.1-0.5.
- Lärandehastighet: Använd en lägre lärandehastighet än standardfinjustering, vanligtvis i intervallet 1e-6 till 1e-5.
- Batchstorlek: Större batchstorlekar (32-128) fungerar ofta bra för preferensinlärning.
c) Iterativ Raffinering: DPO kan tillämpas iterativt:
- Träna en initial modell med DPO
- Generera nya svar med den tränade modellen
- Samlar in ny preferensdata på dessa svar
- Omträna med den utvidgade datamängden

Direkt Preferensoptimering Prestanda
Denna bild visar prestandan för LLM som GPT-4 i jämförelse med mänskliga bedömningar över olika träningsmetoder, inklusive Direkt Preferensoptimering (DPO), Övervakad Finjustering (SFT) och Proximal Policy Optimization (PPO). Tabellen visar att GPT-4:s utdata är alltmer anpassade till mänskliga preferenser, särskilt i sammanfattningsuppgifter. Nivån på överensstämmelse mellan GPT-4 och mänskliga granskare visar modellens förmåga att generera innehåll som stämmer överens med mänskliga utvärderare, nästan lika nära som mänskligt genererat innehåll.
Fallstudier och Tillämpningar
För att illustrera effektiviteten hos DPO, låt oss se några verkliga tillämpningar och några av dess varianter:
- Iterativ DPO: Utvecklad av Snorkel (2023), denna variant kombinerar urvalssampling med DPO, vilket möjliggör en mer raffinerad urvalsprocess för träningsdata. Genom att iterera över flera omgångar av preferenssampling kan modellen bättre generalisera och undvika överanpassning till bullriga eller fördomsfulla preferenser.
- IPO (Iterativ Preferensoptimering): Introducerad av Azar et al. (2023), IPO lägger till en regleringsterm för att förhindra överanpassning, som är ett vanligt problem i preferensbaserad optimering. Denna utvidgning tillåter modeller att upprätthålla en balans mellan att följa preferenser och bevara generaliseringsförmåga.
- KTO (Kunskapsöverföringsoptimering): En senare variant från Ethayarajh et al. (2023), KTO avskaffar binära preferenser helt. Istället fokuserar den på att överföra kunskap från en referensmodell till policymodellen, vilket optimerar för en smidigare och mer konsekvent anpassning till mänskliga värderingar.
- Multi-Modal DPO för Cross-Domain-Lärande av Xu et al. (2024): En approach där DPO tillämpas över olika modaliteter—text, bild och ljud—demonstrerar dess flexibilitet i anpassning av modeller till mänskliga preferenser över olika datatyper. Denna forskning belyser potentialen hos DPO i skapandet av mer omfattande AI-system kapabla att hantera komplexa, multimodala uppgifter.












