Artificiell intelligens
ChatGPT:s första årsdag: Omformning av framtiden för AI-interaktion

När vi ser tillbaka på ChatGPT:s första år är det tydligt att detta verktyg har förändrat AI-scenen på ett betydande sätt. Lanserat i slutet av 2022 stack ChatGPT ut på grund av sin användarvänliga, konversationsstil som gjorde interaktion med AI mer som att prata med en person än en maskin. Denna nya tillvägagångssätt fångade snabbt allmänhetens öga. Inom bara fem dagar efter dess release hade ChatGPT redan lockat till sig en miljon användare. I början av 2023 hade detta antal svällt till cirka 100 miljoner månatliga användare, och i oktober drog plattformen in runt 1,7 miljarder besök världen över. Dessa siffror talar om för sig själva om dess popularitet och användbarhet.
Under det senaste året har användare hittat alla möjliga kreativa sätt att använda ChatGPT, från enkla uppgifter som att skriva e-post och uppdatera CV till att starta framgångsrika företag. Men det handlar inte bara om hur människor använder det; teknologin själv har växt och förbättrats. Initialt var ChatGPT en gratis tjänst som erbjöd detaljerade textsvar. Nu finns det ChatGPT Plus, som inkluderar ChatGPT-4. Denna uppdaterade version är tränad på mer data, ger färre felaktiga svar och förstår komplexa instruktioner bättre.
En av de största uppdateringarna är att ChatGPT nu kan interagera på flera sätt – den kan lyssna, tala och till och med bearbeta bilder. Detta innebär att du kan prata med den genom dess mobilapp och visa den bilder för att få svar. Dessa förändringar har öppnat upp nya möjligheter för AI och har förändrat hur människor ser och tänker om AI:s roll i våra liv.
Från sin början som en teknisk demo till sin nuvarande status som en stor spelare i tech-världen är ChatGPT:s resa ganska imponerande. Initialt sågs det som ett sätt att testa och förbättra tekniken genom att få feedback från allmänheten. Men det blev snabbt en viktig del av AI-landskapet. Denna framgång visar hur effektivt det är att finjustera stora språkmodeller (LLM) med både övervakad inlärning och feedback från människor. Som ett resultat kan ChatGPT hantera en mängd olika frågor och uppgifter.
Kapplöpningen att utveckla de mest kapabla och mångsidiga AI-systemen har lett till en mängd både öppen källkod och proprietära modeller som ChatGPT. För att förstå deras allmänna förmågor krävs omfattande benchmarking över ett brett spektrum av uppgifter. Detta avsnitt utforskar dessa benchmarking, och kastar ljus över hur olika modeller, inklusive ChatGPT, står sig mot varandra.
Utvardering av LLM: Benchmarking
- MT-Bench: Denna benchmark testar multi-turn konversation och instruktionsföljande förmågor över åtta domäner: skrivning, rollspel, informationsutvinning, resonemang, matematik, kodning, STEM-kunskap och humaniora/samhällsvetenskap. Starkare LLM som GPT-4 används som utvärderare.
- AlpacaEval: Baserat på AlpacaFarm-utvärderingsuppsättningen, denna LLM-baserade automatiska utvärderare benchmarkar modeller mot svar från avancerade LLM som GPT-4 och Claude, och beräknar vinstfrekvensen för kandidatmodeller.
- Öppen LLM-ledare: Med hjälp av Language Model Evaluation Harness, utvärderar denna ledare LLM på sju nyckelbenchmark, inklusive resonemangsutmaningar och allmänna kunskapstester, i både zero-shot och few-shot inställningar.
- BIG-bench: Denna samarbetsbenchmark täcker över 200 nya språkuppgifter, som spänner över en mängd olika ämnen och språk. Den syftar till att undersöka LLM och förutsäga deras framtida förmågor.
- ChatEval: En multi-agent debatt-ram som tillåter team att autonomt diskutera och utvärdera kvaliteten på svar från olika modeller på öppna frågor och traditionella naturliga språkgenereringsuppgifter.
Jämförande prestation
När det gäller allmänna benchmark har öppen källkods-LLM visat en anmärkningsvärd framsteg. Llama-2-70B, till exempel, uppnådde imponerande resultat, särskilt efter att ha finjusterats med instruktionsdata. Dess variant, Llama-2-chat-70B, utmärkte sig i AlpacaEval med en vinstfrekvens på 92,66 %, och överträffade GPT-3.5-turbo. Men GPT-4 förblir ledaren med en vinstfrekvens på 95,28 %.
Zephyr-7B, en mindre modell, visade förmågor jämförbara med större 70B LLM, särskilt i AlpacaEval och MT-Bench. Medan WizardLM-70B, finjusterad med en mångfald av instruktionsdata, fick den högsta poängen bland öppen källkods-LLM på MT-Bench. Men den låg fortfarande efter GPT-3.5-turbo och GPT-4.
En intressant post, GodziLLa2-70B, uppnådde en konkurrenskraftig poäng på den öppna LLM-ledaren, och visade potentialen för experimentella modeller som kombinerar olika dataset. Likaså utmärkte sig Yi-34B, utvecklad från scratch, med poäng jämförbara med GPT-3.5-turbo och bara marginellt efter GPT-4.
UltraLlama, med sin finjustering på mångfaldig och högkvalitativ data, matchade GPT-3.5-turbo i dess föreslagna benchmark och överträffade till och med den i områden som världen och professionell kunskap.
Skalning upp: Uppgången av jätte-LLM
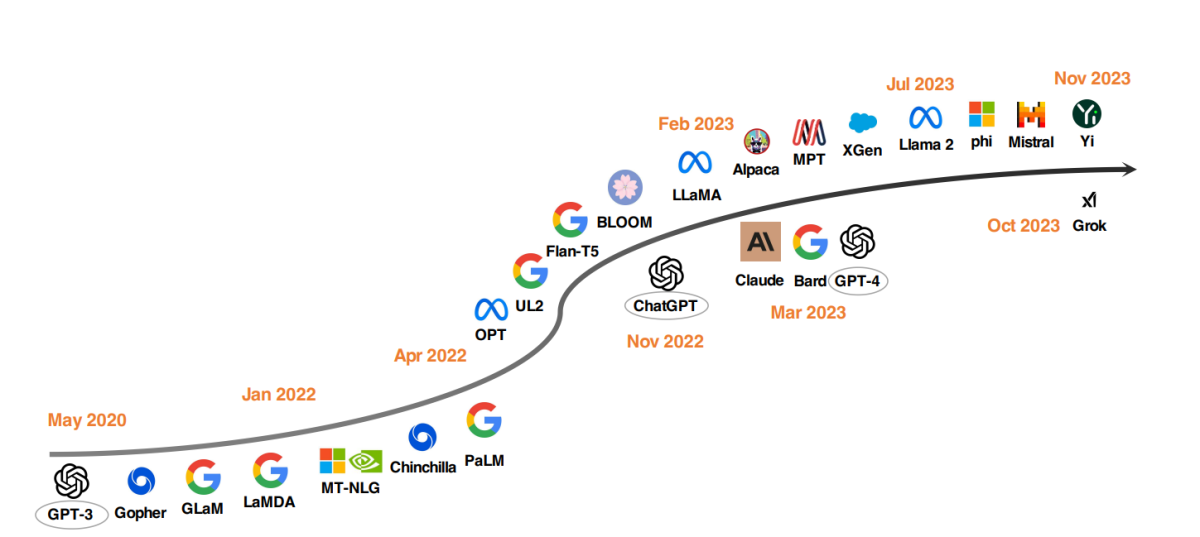
Top LLM-modeller sedan 2020
En anmärkningsvärd trend i LLM-utveckling har varit skalningen av modellparametrar. Modeller som Gopher, GLaM, LaMDA, MT-NLG och PaLM har pressat gränserna, och resulterat i modeller med upp till 540 miljarder parametrar. Dessa modeller har visat exceptionella förmågor, men deras slutna natur har begränsat deras vidare tillämpning. Denna begränsning har väckt intresse för att utveckla öppen källkods-LLM, en trend som växer i styrka.
I samma takt som modellstorleken ökar, har forskare utforskat alternativa strategier. Istället för att bara göra modellerna större, har de fokuserat på att förbättra förträningen av mindre modeller. Exempel inkluderar Chinchilla och UL2, som har visat att mer inte alltid är bättre; smartare strategier kan ge effektiva resultat också. Dessutom har det funnits betydande uppmärksamhet på instruktionsjustering av språkmodeller, med projekt som FLAN, T0 och Flan-T5 som har gjort betydande bidrag till detta område.
ChatGPT-katalysatorn
Introduktionen av OpenAI:s ChatGPT markerade en vändpunkt i NLP-forskning. För att konkurrera med OpenAI lanserade företag som Google och Anthropic sina egna modeller, Bard och Claude, respectively. Medan dessa modeller visar jämförbara prestationer med ChatGPT i många uppgifter, ligger de fortfarande efter den senaste modellen från OpenAI, GPT-4. Framgången för dessa modeller tillskrivs primärt förstärkt inlärning från mänsklig feedback (RLHF), en teknik som får ökad forskningsfokus för ytterligare förbättring.
Ryktet och spekulationer kring OpenAI:s Q* (Q-Stjärna)
Nya rapporter tyder på att forskare på OpenAI kan ha uppnått en betydande framsteg i AI med utvecklingen av en ny modell som kallas Q* (uttalas Q-stjärna). Påstås ha förmågan att utföra grundskole-nivå matematik, en bedrift som har väckt diskussioner bland experter om dess potential som en milstolpe mot artificiell allmän intelligens (AGI). Medan OpenAI inte har kommenterat dessa rapporter, har de påstådda förmågorna hos Q* genererat betydande upphetsning och spekulation på sociala medier och bland AI-entusiaster.
Utvecklingen av Q* är anmärkningsvärd eftersom existerande språkmodeller som ChatGPT och GPT-4, medan de kan hantera vissa matematiska uppgifter, är inte särskilt skickliga på att hantera dem tillförlitligt. Utmaningen ligger i behovet av AI-modeller som inte bara kan känna igen mönster, som de för närvarande gör genom djupinlärning och transformers, utan också resonera och förstå abstrakta begrepp. Matematik, som en benchmark för resonemang, kräver att AI-modellen planerar och utför flera steg, och visar en djup förståelse för abstrakta begrepp. Denna förmåga skulle markera ett betydande språng i AI-förmågor, potentiellt utökas bortom matematik till andra komplexa uppgifter.
Men experter varnar för att inte överdriva denna utveckling. Medan en AI-system som tillförlitligt löser matematikproblem skulle vara en imponerande prestation, signalerar det inte nödvändigtvis ankomsten av superintelligent AI eller AGI. Nuvarande AI-forskning, inklusive ansträngningar från OpenAI, har fokuserat på elementära problem, med varierande grad av framgång i mer komplexa uppgifter.
De potentiella tillämpningarna av framsteg som Q* är omfattande, från personlig undervisning till att assistera i vetenskaplig forskning och ingenjörskonst. Men det är också viktigt att hantera förväntningar och erkänna begränsningarna och säkerhetsproblem som är förknippade med sådana framsteg. Bekymren om AI som utgör existentiella risker, en grundläggande oro för OpenAI, förblir relevanta, särskilt när AI-system börjar interagera mer med den verkliga världen.
Öppen källkods-LLM-rörelsen
För att öka öppen källkods-LLM-forskning släppte Meta Llama-seriens modeller, vilket utlöste en våg av nya utvecklingar baserade på Llama. Detta inkluderar modeller finjusterade med instruktionsdata, som Alpaca, Vicuna, Lima och WizardLM. Forskning grenar sig också ut i att förbättra agentförmågor, logiskt resonemang och långkontextmodellering inom Llama-baserade ramverk.
Dessutom finns det en växande trend att utveckla kraftfulla LLM från scratch, med projekt som MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok och Yi. Dessa ansträngningar speglar ett engagemang för att demokratisera förmågorna hos slutna källkods-LLM, och göra avancerade AI-verktyg mer tillgängliga och effektiva.
Impacten av ChatGPT och öppen källkodsmodeller inom hälso- och sjukvård
Vi ser en framtid där LLM hjälper till med kliniska anteckningar, blankettifyllning för ersättning och stödjer läkare i diagnos och behandlingsplanering. Detta har väckt uppmärksamhet hos både tech-jättar och hälso- och sjukvårdsinstitutioner.
Microsofts diskussioner med Epic, en ledande programvara för elektroniska hälsojournaler, signalerar integrationen av LLM i hälso- och sjukvård. Initiativ är redan på plats vid UC San Diego Health och Stanford University Medical Center. Likaså markerar Googles samarbete med Mayo Clinic och Amazon Web Services lansering av HealthScribe, en AI-baserad klinisk dokumentationstjänst, betydande steg i denna riktning.
Men dessa snabba distributioner väcker bekymmer om att lämna kontrollen över medicinen till kommersiella intressen. Den slutna naturen hos dessa LLM gör dem svåra att utvärdera. Deras möjliga modifiering eller avbrott för vinstskäl kan kompromissa patientvård, integritet och säkerhet.
Den brådskande behovet är en öppen och inkluderande tillvägagångssätt för LLM-utveckling inom hälso- och sjukvård. Hälso- och sjukvårdsinstitutioner, forskare, kliniker och patienter måste samarbeta globalt för att bygga öppen källkods-LLM för hälso- och sjukvård. Detta tillvägagångssätt, liknande Trillion Parameter Consortium, skulle tillåta poolning av beräknings-, finansiella resurser och expertis.












