Искусственный интеллект
Как Стейбл Диффузия Может Развиться в Основной Потребительский Продукт

Иронично, что Стейбл Диффузия, новая рамка синтеза изображений ИИ, которая потрясла мир, не является ни стабильной, ни действительно “диффузной” – по крайней мере, пока нет.
Полный диапазон возможностей системы распределен по разнообразному ассортименту постоянно меняющихся предложений от горстки разработчиков, которые лихорадочно обмениваются последней информацией и теориями в различных обсуждениях на Discord – и绝 большая часть процедур установки пакетов, которые они создают или модифицируют, очень далека от “подключи и играй”.
Вместо этого они, как правило, требуют установки через командную строку или с помощью BAT-файлов через GIT, Conda, Python, Miniconda и другие передовые инструменты разработки – программные пакеты, которые так редки среди обычных потребителей, что их установка часто помечается антивирусными и анти-малварными поставщиками как доказательство компрометации системы.
[подпись id=”attachment_183833″ align=”alignnone” width=”908″]
Темы сообщений в обоих сообществах SFW и NSFW Стейбл Диффузии переполнены советами и трюками, связанными с взломом скриптов Python и стандартных установок, чтобы включить улучшенную функциональность или решить частые ошибки зависимостей и другие проблемы.
Это оставляет среднего потребителя, заинтересованного в создании удивительных изображений из текстовых подсказок, практически на милость растущего числа монетизированных веб-интерфейсов API, большинство из которых предлагает минимальное количество бесплатных генераций изображений перед покупкой токенов.
Кроме того, почти все эти веб-ориентированные предложения отказываются выводить контент NSFW (много из которого может относиться к непорнографическим предметам общего интереса, таким как “война”), который отличает Стейбл Диффузию от цензурированных услуг DALL-E 2 от OpenAI.
‘Фотошоп для Стейбл Диффузии’
Завороженные фантастическими, провокационными или потусторонними изображениями, которые населяют хэштег #stablediffusion в Twitter каждый день, то, что ждет более широкий мир, – это, вероятно, ‘Фотошоп для Стейбл Диффузии’ – кроссплатформенная устанавливаемая приложение, которое объединяет лучшую и наиболее мощную функциональность архитектуры Stability.ai, а также различные изобретательные инновации развивающегося сообщества SD, без каких-либо плавающих окон CLI, неясных и постоянно меняющихся процедур установки и обновления, или отсутствующих функций.
То, что у нас сейчас есть, в большинстве более способных установок, – это веб-страница, обрамленная оторванным окном командной строки, и у которой URL – это localhost-порт:
[подпись id=”attachment_183834″ align=”alignnone” width=”908″]
Без сомнения, более упрощенное приложение идет. Уже есть несколько приложений на основе Patreon, которые можно скачать, такие как GRisk и NMKD (см. изображение ниже) – но ни одно из них пока не объединяет полный диапазон функций, который некоторые из более продвинутых и менее доступных реализаций Стейбл Диффузии могут предложить.
[подпись id=”attachment_183835″ align=”alignnone” width=”997″]
Давайте посмотрим, как может выглядеть более отполированная и интегрированная реализация этого удивительного открытоГО чуда – и какие проблемы она может столкнуться.
Юридические Рассмотрения для Полностью Финансируемого Коммерческого Приложения Стейбл Диффузии
Фактор NSFW
Исходный код Стейбл Диффузии был выпущен под очень либеральными лицензиями, которые не запрещают коммерческие реимплементации и производные работы, которые строятся на основе исходного кода.
Помимо упомянутых выше и растущего числа сборов Стейбл Диффузии на основе Patreon, а также обширного количества плагинов приложений, разрабатываемых для Figma, Krita, Photoshop, GIMP и Blender (среди других), нет практической причины, по которой хорошо финансируемый дом разработки программного обеспечения не мог бы разработать гораздо более сложное и способное приложение Стейбл Диффузии. С рыночной точки зрения, есть все основания полагать, что несколько таких инициатив уже хорошо продвинуты.
Здесь такие усилия сразу же сталкиваются с дилеммой о том, следует ли приложению, как и большинству веб-API для Стейбл Диффузии, разрешить родной фильтр NSFW Стейбл Диффузии (фрагмент кода), быть отключенным.
‘Закопать’ Переключатель NSFW
Хотя открытая лицензия Stability.ai для Стейбл Диффузии включает в себя достаточно интерпретируемый список применений, для которых она может не быть использована (вероятно, включая порнографический контент и дипфейки), единственный способ, которым поставщик мог бы эффективно запретить такое использование, был бы скомпилировать фильтр NSFW в непрозрачный исполняемый файл вместо параметра в файле Python, или же обеспечить сравнение контрольной суммы файла Python или DLL, содержащего директиву NSFW, так что рендеры не могут произойти, если пользователи изменят это настройку.
Это оставило бы приложение “кастрированным” таким же образом, как DALL-E 2 в настоящее время, уменьшая его коммерческую привлекательность. Кроме того, неизбежно, декомпилированные “подделанные” версии этих компонентов (либо исходных элементов среды выполнения Python, либо скомпилированных файлов DLL, как в линии инструментов AI-усиления изображений Topaz) вероятно, появятся в сообществе торрентов/хакинга, чтобы обойти такие ограничения, просто заменив препятствующие элементы и отменив любые требования контрольной суммы.
В конце концов, поставщик может выбрать просто повторить предупреждение Stability.ai о неправильном использовании, которое характеризует первый запуск многих текущих распределений Стейбл Диффузии.
Однако небольшие разработчики с открытым исходным кодом в настоящее время используют случайные免ения в этом смысле, имеют мало, что можно потерять, по сравнению с компанией программного обеспечения, которая инвестировала значительные суммы времени и денег в то, чтобы сделать Стейбл Диффузию полнофункциональной и доступной – что приглашает к более глубокому рассмотрению.
Ответственность за Дипфейки
Как мы недавно отметили, база данных LAION-эстетики, часть 4,2 миллиарда изображений, на которых были обучены текущие модели Стейбл Диффузии, содержит большое количество изображений знаменитостей, позволяя пользователям эффективно создавать дипфейки, включая дипфейки-порнографию с участием знаменитостей.
[подпись id=”attachment_183836″ align=”alignnone” width=”1200″]
Это отдельная и более спорная проблема, чем генерация (обычно) законной “абстрактной” порнографии, которая не изображает “реальных” людей (хотя такие изображения выводятся из нескольких реальных фотографий в обучающем материале).
Поскольку все больше штатов США и стран разрабатывают или ввели законы против дипфейк-порнографии, способность Стейбл Диффузии создавать дипфейки-порнографию с участием знаменитостей может означать, что коммерческое приложение, которое не полностью цензурировано (т.е. которое может создавать порнографический материал), может все равно потребовать некоторой способности фильтровать воспринимаемые лица знаменитостей.
Одним из методов может быть предоставление встроенного “черного списка” терминов, которые не будут приняты в пользовательской подсказке, связанных с именами знаменитостей и вымышленными персонажами, с которыми они могут быть связаны. Предположительно такие настройки потребуют учреждения на нескольких языках, помимо английского, поскольку исходные данные включают другие языки. Другой подход может заключаться в включении систем распознавания знаменитостей, таких как те, которые были разработаны Clarifai.
Возможно, что производителям программного обеспечения придется включать такие методы, возможно, изначально выключенные, чтобы помочь предотвратить полноценное автономное приложение Стейбл Диффузии от генерации лиц знаменитостей, в ожидании новых законов, которые могли бы сделать такую функциональность незаконной.
Однако, как и в предыдущем случае, такая функциональность могла бы быть декомпилирована и обращена заинтересованными сторонами; однако производитель программного обеспечения мог бы, в таком случае, утверждать, что это фактически не санкционированное вандализм – пока такая обратная инженерия не делается чрезмерно легкой.
Функции, которые Можно Включить
Основная функциональность в любом распределении Стейбл Диффузии будет ожидаться от любого хорошо финансируемого коммерческого приложения. Это включает в себя возможность использовать текстовые подсказки для генерации подходящих изображений (текст-изображение); возможность использовать эскизы или другие изображения в качестве ориентиров для новых сгенерированных изображений (изображение-изображение); средства для регулирования “воображаемости” системы; способ обменять время рендеринга на качество; и другие “основы”, такие как необязательное автоматическое архивирование изображений/подсказок и рутинное необязательное масштабирование через RealESRGAN, и как минимум базовое “исправление лица” с помощью GFPGAN или CodeFormer.
Это довольно “ванильная установка”. Давайте посмотрим на некоторые из более продвинутых функций, которые в настоящее время разрабатываются или расширяются, которые могли бы быть включены в полноценное “традиционное” приложение Стейбл Диффузии.
Стохастическое Замораживание
Даже если вы повторно используете семя из предыдущего успешного рендеринга, это ужасно трудно заставить Стейбл Диффузию точно повторить преобразование, если любая часть подсказки или исходного изображения (или обоих) изменяется для последующего рендеринга.
Это проблема, если вы хотите использовать EbSynth, чтобы наложить преобразования Стейбл Диффузии на реальное видео в временно согласованном порядке – хотя техника может быть очень эффективной для простых кадров с головой и плечами:
[подпись id=”attachment_183837″ align=”alignnone” width=”389″] Ограниченное движение может сделать EbSynth эффективным средством для преобразования преобразований Стейбл Диффузии в реалистичное видео. Источник: https://streamable.com/u0pgzd[/подпись]
Ограниченное движение может сделать EbSynth эффективным средством для преобразования преобразований Стейбл Диффузии в реалистичное видео. Источник: https://streamable.com/u0pgzd[/подпись]
EbSynth работает, экстраполируя небольшой выбор “измененных” ключевых кадров в видео, которое было отрендерено в серию файлов изображений (и которое может быть позже собрано обратно в видео).
[подпись id=”attachment_183838″ align=”alignnone” width=”1118″]
В примере ниже, где почти нет движения от реальной блондинки-инструктора по йоге слева, Стейбл Диффузия все равно испытывает трудности с поддержанием постоянного лица, потому что три изображения, преобразуемые в качестве “ключевых кадров”, не являются полностью идентичными, даже если они все имеют одинаковый числовой семя.
[подпись id=”attachment_183839″ align=”alignnone” width=”601″]
Хотя видео SD/EbSynth ниже очень изобретательно, где пальцы пользователя превратились в (соответственно) ходячие брюки и утку, несогласованность брюк типифицирует проблему, с которой Стейбл Диффузия сталкивается при поддержании согласованности между разными ключевыми кадрами, даже когда исходные кадры похожи друг на друга, и семя последовательно.
[подпись id=”attachment_183840″ align=”alignnone” width=”520″] Пальцы человека превращаются в ходячего человека и утку, благодаря Стейбл Диффузии и EbSynth. Источник: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/[/подпись]
Пальцы человека превращаются в ходячего человека и утку, благодаря Стейбл Диффузии и EbSynth. Источник: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/[/подпись]
Пользователь, создавший это видео, комментировал, что преобразование утки, которое, вероятно, является более эффективным из двух, требовало только одного преобразованного ключевого кадра, тогда как для создания ходячих брюк потребовалось отрендерить 50 изображений Стейбл Диффузии, которые демонстрируют большую временную несогласованность. Пользователь также отметил, что потребовалось пять попыток, чтобы достичь согласованности для каждого из 50 ключевых кадров.
Следовательно, было бы большим преимуществом для действительно всестороннего приложения Стейбл Диффузии предоставить функциональность, которая сохраняет характеристики до максимальной степени между ключевыми кадрами.
Одной из возможностей является то, что приложение позволяет пользователю “заморозить” стохастическое кодирование для преобразования на каждом кадре, что в настоящее время можно добиться только путем ручного изменения исходного кода. Как показывает пример ниже, это помогает временной согласованности, хотя оно, конечно, не решает ее полностью:
[подпись id=”attachment_183843″ align=”alignnone” width=”500″] Один пользователь Reddit преобразовал кадры веб-камеры себя в разных знаменитых людях, не только сохраняя семя (что может сделать любая реализация Стейбл Диффузии), но и обеспечивая, чтобы параметр stochastic_encode() был идентичен в каждом преобразовании. Это было достигнуто путем изменения кода, но могло бы легко стать переключателем, доступным для пользователя. Очевидно, однако, что это не решает все временные проблемы. Источник: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/[/подпись]
Один пользователь Reddit преобразовал кадры веб-камеры себя в разных знаменитых людях, не только сохраняя семя (что может сделать любая реализация Стейбл Диффузии), но и обеспечивая, чтобы параметр stochastic_encode() был идентичен в каждом преобразовании. Это было достигнуто путем изменения кода, но могло бы легко стать переключателем, доступным для пользователя. Очевидно, однако, что это не решает все временные проблемы. Источник: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/[/подпись]
Облачное Текстовое Вversion
Лучшее решение для получения временно согласованных персонажей и объектов – это “запечатать” их в Текстовую Инверсию – файл размером 5 КБ, который можно обучить за несколько часов на основе только пяти аннотированных изображений, который затем может быть вызван специальным ‘*’ подсказкой, позволяя, например, постоянному появлению новых персонажей для включения в повествование.
[подпись id=”attachment_183844″ align=”alignnone” width=”1200″]
Текстовые Инверсии – это дополнительные файлы к очень большому и полностью обученному модели, которую использует Стейбл Диффузия, и эффективно “проталкиваются” в процесс вызова/подсказки, так что они могут участвовать в сценах, полученных из модели, и извлечь пользу из огромной базы знаний модели о объектах, стилях, средах и взаимодействиях.
Однако, хотя Текстовая Инверсия не занимает много времени для обучения, она требует большого количества видеопамяти; согласно различным текущим учебным пособиям, где-то между 12, 20 и даже 40 ГБ.
Поскольку большинство случайных пользователей вряд ли имеют такой объем GPU-мощности, облачные услуги уже появляются, которые будут обрабатывать операцию, включая версию Hugging Face. Хотя есть реализации Google Colab, которые могут создать текстовые инверсии для Стейбл Диффузии, необходимые требования к видеопамяти и времени могут сделать их сложными для пользователей бесплатного уровня Colab.
Для потенциального полноценного и хорошо инвестированного приложения Стейбл Диффузии (установленного) было бы очевидной стратегией монетизации передать эту тяжелую задачу на серверы компании в облаке (предполагая, что низкозатратное или бесплатное приложение Стейбл Диффузии пронизано такой не-бесплатной функциональностью, что, вероятно, будет в многих появляющихся приложениях этой технологии в течение следующих 6-9 месяцев).
Кроме того, довольно сложный процесс аннотирования и форматирования представленных изображений и текста мог бы выиграть от автоматизации в интегрированной среде. Потенциальный “зависимый фактор” создания уникальных элементов, которые могут исследовать и взаимодействовать с огромными мирами Стейбл Диффузии, казался бы потенциально компульсивным, как для общих энтузиастов, так и для более молодых пользователей.
Универсальное Весовое Промптинг
Есть много текущих реализаций, которые позволяют пользователю присвоить большее значение разделу длинной текстовой подсказки, но инструментарий варьируется довольно сильно между ними и часто бывает неуклюжим или неинтуитивным.
Очень популярный форк Стейбл Диффузии от AUTOMATIC1111, например, может понизить или повысить значение слова подсказки, заключив его в одинарные или несколько скобок (для снижения значения) или квадратные скобки для дополнительного акцента.
[подпись id=”attachment_183845″ align=”alignnone” width=”989″]
Другие итерации Стейбл Диффузии используют восклицательные знаки для акцента, тогда как наиболее универсальные позволяют пользователям присвоить веса каждому слову в подсказке через GUI.
Система также должна позволять отрицательные веса подсказок – не только для фанатов ужасов, но и потому, что могут быть менее тревожные и более просвещающие тайны в латентном пространстве Стейбл Диффузии, которые наша ограниченная использование языка не может вызвать.
Расширение за Пределы
Вскоре после того, как Стейбл Диффузия была открыта, OpenAI попыталась – в основном безуспешно – вернуть часть своего грома DALL-E 2, объявив “расширение за пределы”, которое позволяет пользователю расширить изображение за его границы с семантической логикой и визуальной согласованностью.
Естественно, что это с тех пор было реализовано в различных формах для Стейбл Диффузии, а также в Krita, и должно быть включено в всестороннее, “Фотошоп-подобное” приложение Стейбл Диффузии.
[подпись id=”attachment_183846″ align=”alignnone” width=”708″]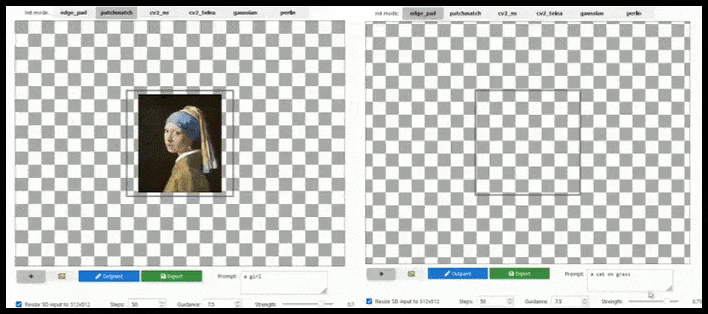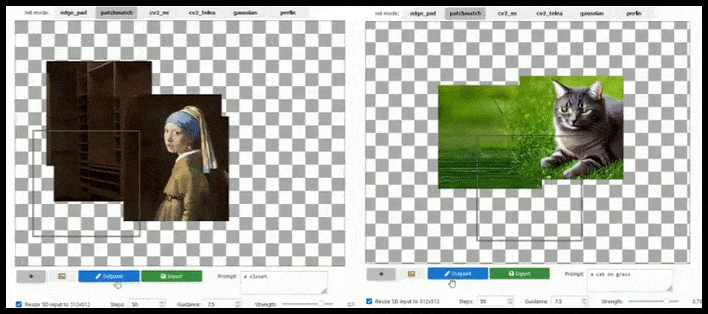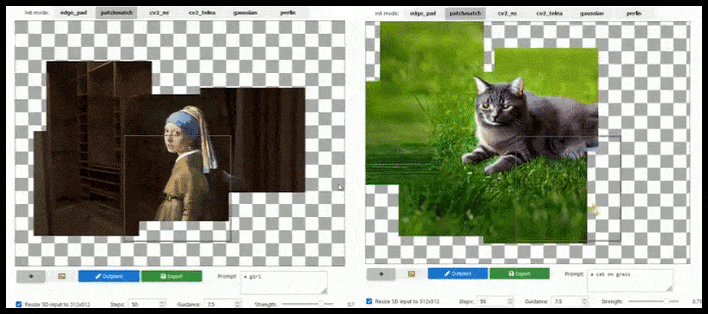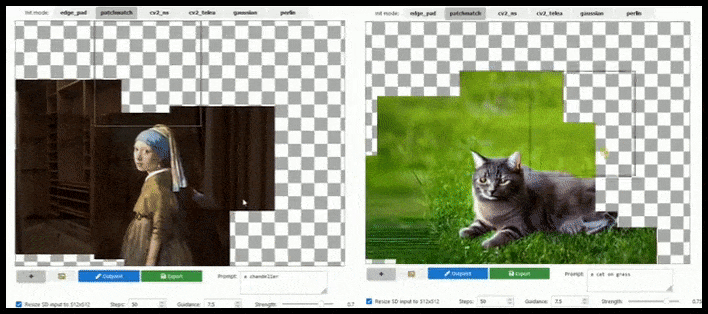 Тайловое дополнение может расширить стандартный рендер 512x512px почти бесконечно, пока подсказки, существующее изображение и семантическая логика позволяют это. Источник: https://github.com/lkwq007/stablediffusion-infinity[/подпись]
Тайловое дополнение может расширить стандартный рендер 512x512px почти бесконечно, пока подсказки, существующее изображение и семантическая логика позволяют это. Источник: https://github.com/lkwq007/stablediffusion-infinity[/подпись]
Поскольку Стейбл Диффузия обучена на изображениях 512x512px (и по разным другим причинам), она часто обрезает головы (или другие важные части тела) человеческих субъектов, даже когда подсказка явно указывала на “акцент на голове” и т. д..
[подпись id=”attachment_183847″ align=”alignnone” width=”1200″]
Любая реализация расширения за пределы такого типа, как показано на анимированном изображении выше (которое основано исключительно на Unix-библиотеках, но должно быть способно быть воспроизведенным на Windows), также должна быть инструментом с одним кликом/подсказкой для этого.
В настоящее время многие пользователи расширяют холст “обезглавленных” изображений вверх, примерно заполняют область головы и используют img2img, чтобы завершить испорченный рендер.
Эффективное Маскирование, Понимающее Контекст
Маскирование может быть ужасно хитрым делом в Стейбл Диффузии, в зависимости от форка или версии в вопросе. Часто, когда возможно нарисовать связное маскирование, указанная область заканчивается тем, что заполнена контентом, который не учитывает весь контекст изображения.
В один раз я замаскировал радужную оболочку глаз лица изображения и предоставил подсказку ‘голубые глаза’ в качестве маскированного inpaint – только чтобы обнаружить, что я, кажется, смотрю через два вырезанные человеческие глаза на отдаленное изображение потустороннего волка. Я думаю, мне повезло, что это не был Фрэнк Синатра.
Семантическая редактирование также возможно путем идентификации шума, который сгенерировал изображение в первую очередь, что позволяет пользователю обращаться к конкретным структурным элементам в рендере без нарушения остальной части изображения:
[подпись id=”attachment_183848″ align=”alignnone” width=”1200″]
Этот метод основан на семплере K-Diffusion.
Семантические Фильтры для Физиологических Ошибок
Как мы упоминали ранее, Стейбл Диффузия может часто добавлять или удалять конечности, в основном из-за проблем с данными и ограничениями в аннотациях, которые сопровождают изображения, на которых она была обучена.
[подпись id=”attachment_183851″ align=”alignnone” width=”1100″]
Было бы полезно, если бы полноценное приложение Стейбл Диффузии содержало некоторую систему анатомического распознавания, которая использовала бы семантическую сегментацию для расчета того, содержит ли входящее изображение серьезные анатомические дефекты (как на изображении выше), и отклоняет его в пользу нового рендеринга, прежде чем представить его пользователю.

Конечно, вы можете захотеть отрендерить богиню Кали или Доктора Октопуса, или даже спасти не затронутую часть изображения с конечностями; поэтому эта функция должна быть опциональным переключателем.
Если пользователи могут терпеть аспект телеметрии, такие промахи даже могут быть переданы анонимно в коллективное усилие федеративного обучения, которое может помочь будущим моделям улучшить их понимание анатомической логики.
Автоматическое Улучшение Лица на основе LAION
Как я отметил в своем предыдущем взгляде на три вещи, которые Стейбл Диффузия могла бы решить в будущем, она не должна оставаться исключительно за любой версией GFPGAN, чтобы попытаться “улучшить” отрендеренные лица в первичных рендерингах.
“Улучшения” GFPGAN ужасно генеричны, часто подрывают идентичность изображенного человека и работают исключительно на лице, которое получило не более времени обработки или внимания, чем любая другая часть изображения.
Следовательно, профессионально-стандартная программа для Стейбл Диффузии должна быть в состоянии распознать лицо (с помощью стандартной и относительно легкой библиотеки, такой как YOLO), применить полный вес доступной мощности GPU к пере-рендерингу его, и либо смешать улучшенное лицо в исходный полно-контекстный рендер, либо сохранить его отдельно для ручной рекомпозиции. В настоящее время это довольно “ручная” операция.
[подпись id=”attachment_183853″ align=”alignnone” width=”798″]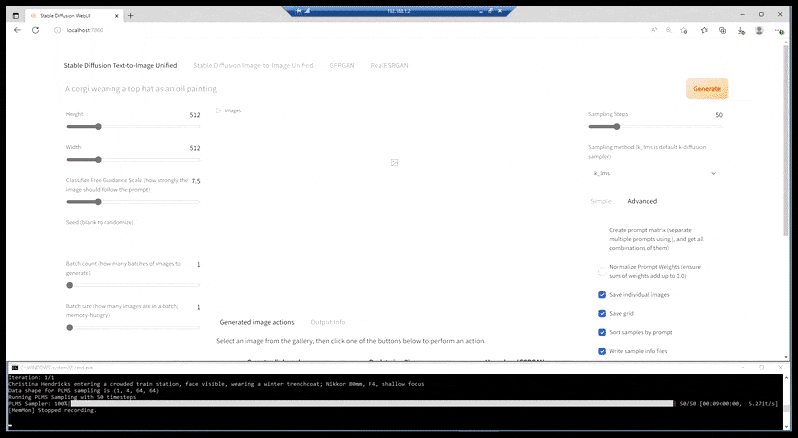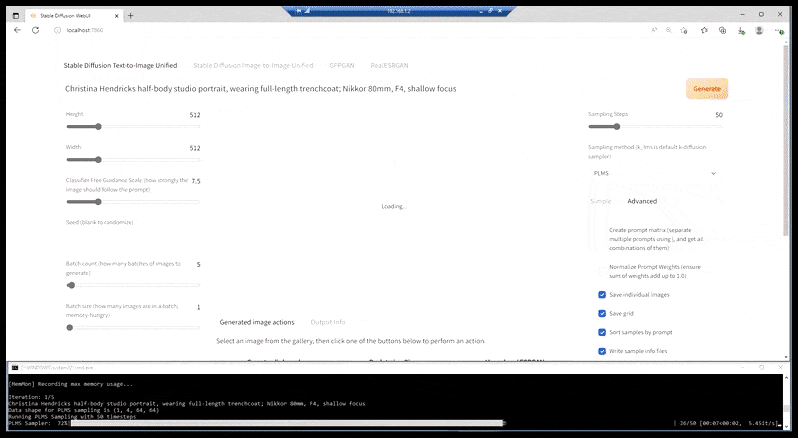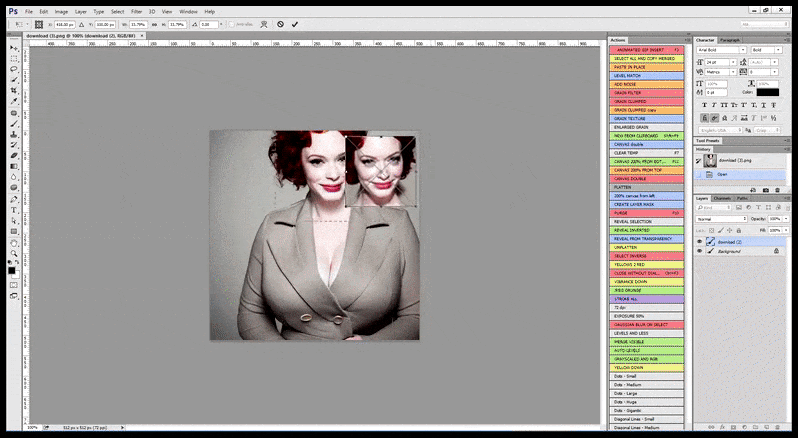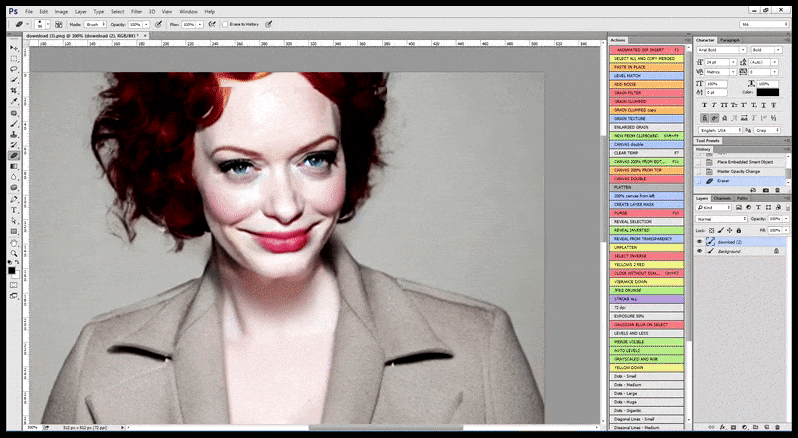 В случаях, когда Стейбл Диффузия была обучена на достаточном количестве изображений знаменитости, возможно сосредоточить всю мощность GPU на последующем рендеринге только лица отрендеренного изображения, которое обычно является заметным улучшением – и, в отличие от GFPGAN, опирается на информацию из данных LAION, а не просто корректирует отрендеренные пиксели.[/подпись]
В случаях, когда Стейбл Диффузия была обучена на достаточном количестве изображений знаменитости, возможно сосредоточить всю мощность GPU на последующем рендеринге только лица отрендеренного изображения, которое обычно является заметным улучшением – и, в отличие от GFPGAN, опирается на информацию из данных LAION, а не просто корректирует отрендеренные пиксели.[/подпись]
Поиск в LAION внутри Приложения
Поскольку пользователи начали осознавать, что поиск базы данных LAION для концепций, людей и тем может помочь в лучшем использовании Стейбл Диффузии, несколько онлайн-обозревателей LAION были созданы, включая haveibeentrained.com.
[подпись id=”attachment_183854″ align=”alignnone” width=”871″]
Хотя такие веб-ориентированные базы данных часто раскрывают некоторые из тегов, которые сопровождают изображения, процесс генерализации, который происходит во время обучения модели, означает, что вряд ли какое-либо конкретное изображение может быть вызвано, используя его тег в качестве подсказки.
Кроме того, удаление ‘стоп-слов’ и практика стемминга и лемматизации в обработке естественного языка означают, что многие из фраз, отображаемых в этих интерфейсах, были разделены или опущены перед обучением в Стейбл Диффузии.
Тем не менее, то, как эстетические группировки связаны в этих интерфейсах, может научить конечного пользователя многое о логике (или, возможно, “личности”) Стейбл Диффузии и может помочь в лучшем производстве изображений.
Заключение
Есть много других функций, которые я бы хотел видеть в полноценной родной настольной реализации Стейбл Диффузии, таких как родная анализ изображений на основе CLIP, который обращает стандартный процесс Стейбл Диффузии и позволяет пользователю вызвать фразы и слова, которые система естественно ассоциирует с исходным изображением или рендером.
Кроме того, истинное тайловое масштабирование было бы желанным дополнением, поскольку ESRGAN почти так же груб, как и GFPGAN. К счастью, планы по интеграции реализации txt2imghd GOBIG быстро делают это реальностью во всех распределениях, и кажется очевидным выбором для настольной итерации.
Некоторые другие популярные запросы из сообществ Discord интересуют меня меньше, такие как интегрированные словари подсказок и применимые списки художников и стилей, хотя встроенная тетрадь или настраиваемый лексикон фраз казался бы логичным дополнением.
Аналогично, текущие ограничения человеческой анимации в Стейбл Диффузии, хотя и были запущены CogVideo и различными другими проектами, остаются невероятно зарождающимися, и находятся на милости исследований в области временных приоритетов, связанных с аутентичным человеческим движением.
На данный момент видео Стейбл Диффузии строго психоделическое, хотя оно может иметь более светлое ближайшее будущее в дипфейк-кукловодстве, через EbSynth и другие относительно новые текст-в-видео-инициативы (и стоит отметить отсутствие синтезированных или “измененных” людей в последнем промо-видео Runway).
Другая ценная функциональность была бы прозрачным проходом Photoshop, который уже давно установлен в редакторе текстур Cinema4D, среди других аналогичных реализаций. С этим вы можете легко переключаться между приложениями и использовать каждое приложение для выполнения преобразований, которые оно выполняет лучше всего.
Наконец, и, возможно, наиболее важно, полноценное настольное приложение Стейбл Диффузии должно быть в состоянии не только легко переключаться между контрольными точками (т.е. версиями основной модели, которая питает систему), но и обновлять пользовательские Текстовые Инверсии, которые работали с предыдущими официальными выпусками модели, но могут быть сломаны более поздними версиями модели (как указали разработчики в официальном Discord).
Иронично, что организация, которая находится в лучшей позиции для создания такого мощного и интегрированного матрикса инструментов для Стейбл Диффузии, Adobe, так сильно связала себя с Инициативой Аутентичности Контента, что может показаться ретроградным шагом в плане PR – если только они не будут препятствовать способности Стейбл Диффузии генерировать, и позиционируют ее вместо этого как естественную эволюцию своих значительных владений в фотобанке.
Опубликовано впервые 15 сентября 2022 года.












