Искусственный интеллект
Три проблемы, которые ждут Stable Diffusion впереди

Релиз модели Stable Diffusion от stability.ai,latent diffusion для синтеза изображений, который состоялся несколько недель назад, может быть одним из наиболее значимых технологических раскрытий с 1999 года и DeCSS; это, безусловно, является самым большим событием в области изображений, сгенерированных ИИ, с 2017 года, когда код глубоких подделок был скопирован на GitHub и разветвлен в то, что стало DeepFaceLab и FaceSwap, а также программное обеспечение для потоковой передачи глубоких подделок в реальном времени DeepFaceLive.
В один момент фрустрация пользователей из-за ограничений контента в API синтеза изображений DALL-E 2 была снята, поскольку оказалось, что фильтр NSFW в Stable Diffusion можно отключить, изменив одну строку кода. Порно-ориентированные подфорумы Stable Diffusion сразу же появились и были быстро закрыты, в то время как разработчики и пользователи разделились на официальные и NSFW-сообщества на Discord, и Twitter начал заполняться фантастическими созданиями Stable Diffusion.
На данный момент каждый день приносит какие-то удивительные инновации от разработчиков, которые приняли систему, с плагинами и сторонними дополнениями, которые быстро пишутся для Krita, Photoshop, Cinema4D, Blender и многих других платформ приложений.
Тем временем, promptcraft – теперь профессиональное искусство «шептания ИИ», которое может оказаться самой короткой карьерной опцией после «Филофакс-биндер» – уже коммерциализируется, в то время как ранняя монетизация Stable Diffusion происходит на уровне Patreon, с уверенностью в том, что будут более сложные предложения, для тех, кто не хочет ориентироваться в Conda-основанных установках исходного кода или прескриптивных фильтров NSFW веб-реализаций.
Темп развития и свободное чувство исследования пользователей происходит с такой головокружительной скоростью, что трудно увидеть далеко вперед. По сути, мы еще не знаем точно, с чем мы имеем дело, или какие могут быть все ограничения или возможности.
Тем не менее, давайте посмотрим на три из того, что может быть наиболее интересными и сложными препятствиями для быстро сформировавшегося и быстро растущего сообщества Stable Diffusion, чтобы столкнуться и, надеюсь, преодолеть.
1: Оптимизация Tile-Based Pipelines
Представленный с ограниченными ресурсами оборудования и жесткими ограничениями на разрешение обучающих изображений, кажется вероятным, что разработчики найдут обходные пути, чтобы улучшить как качество, так и разрешение выходных данных Stable Diffusion. Многие из этих проектов будут включать в себя эксплуатацию ограничений системы, таких как ее родное разрешение всего 512×512 пикселей.
Как всегда бывает с инициативами компьютерного зрения и синтеза изображений, Stable Diffusion был обучен на квадратных изображениях с соотношением сторон, в данном случае пересampled до 512×512, чтобы исходные изображения могли быть нормализованы и помещены в ограничения GPU, которые обучали модель.
Следовательно, Stable Diffusion «думает» (если он думает вообще) в терминах 512×512, и определенно в квадратных терминах. Многие пользователи, в настоящее время исследующие пределы системы, сообщают, что Stable Diffusion производит наиболее надежные и наименее глюки результаты при этом довольно ограниченном соотношении сторон (см. «адресация крайностей» ниже).
Хотя различные реализации включают увеличение через RealESRGAN (и могут исправить плохо отрендеренные лица через GFPGAN) несколько пользователей в настоящее время разрабатывают методы для разделения изображений на секции 512x512px и склеивания изображений вместе, чтобы сформировать более крупные составные работы.

Это 1024×576 рендер, разрешение, обычно невозможное в одном рендере Stable Diffusion, было создано путем копирования и вставки файла attention.py из форка DoggettX Stable Diffusion (версии, которая реализует tile-based увеличение) в другой форк. Источник: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Хотя некоторые инициативы этого типа используют оригинальный код или другие библиотеки, порт txt2imghd GOBIG (режим в VRAM-жадном ProgRockDiffusion) скоро предоставит эту функциональность основной ветке. В то время как txt2imghd является посвященным портом GOBIG, другие усилия сообщества разработчиков включают различные реализации GOBIG.

Удобно абстрактное изображение в исходном рендере 512x512px (слева и второе слева); увеличено ESGRAN, которое теперь более или менее родное во всех дистрибутивах Stable Diffusion; и дано «специальное внимание» через реализацию GOBIG, производящую детали, которые, по крайней мере, в пределах раздела изображения, кажутся лучше увеличенными. Источник: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Такой абстрактный пример, представленный выше, имеет много «маленьких королевств» деталей, которые подходят для этого эгоцентрического подхода к увеличению, но которые могут потребовать более сложных код-ориентированных решений, чтобы произвести не повторяющиеся, сплоченные увеличения, которые не выглядят как если бы они были собраны из многих частей. Не менее важно, в случае человеческих лиц, где мы необычно настроены на аномалии или «jarring» артефакты. Следовательно, лица могут в конечном итоге потребовать специального решения.
Stable Diffusion в настоящее время не имеет механизма для фокусировки внимания на лице во время рендера таким же образом, как люди отдают приоритет информации о лице. Хотя некоторые разработчики в сообществах Discord рассматривают методы реализации такого «усиленного внимания», в настоящее время гораздо проще вручную (и, в конечном итоге, автоматически) улучшить лицо после того, как первоначальный рендер был завершен.
Человеческое лицо имеет внутреннюю и полную семантическую логику, которая не будет найдена в «плитке» нижнего угла (например, здания), и поэтому в настоящее время возможно очень эффективно «увеличить» и переотрендерить «нечеткое» лицо в выходных данных Stable Diffusion.

Слева, первая попытка Stable Diffusion с подсказкой «Полная цветная фотография Кристины Хендрикс, входящей в многолюдное место, одетой в пальто; Canon50, зрительный контакт, высокий уровень детализации, высокий уровень детализации лица». Справа, улучшенное лицо, получено путем подачи размытого и нечеткого лица из первого рендера обратно в полное внимание Stable Diffusion с помощью Img2Img (см. анимированные изображения ниже).
В отсутствие специального решения Textual Inversion (см. ниже), это будет работать только для изображений знаменитостей, где человек на изображении уже хорошо представлен в подмножествах LAION, которые обучали Stable Diffusion. Следовательно, это будет работать на таких людях, как Том Круз, Брэд Питт, Дженнифер Лоуренс, и ограниченный диапазон настоящих медиа-звезд, которые присутствуют в большом количестве изображений в исходных данных.
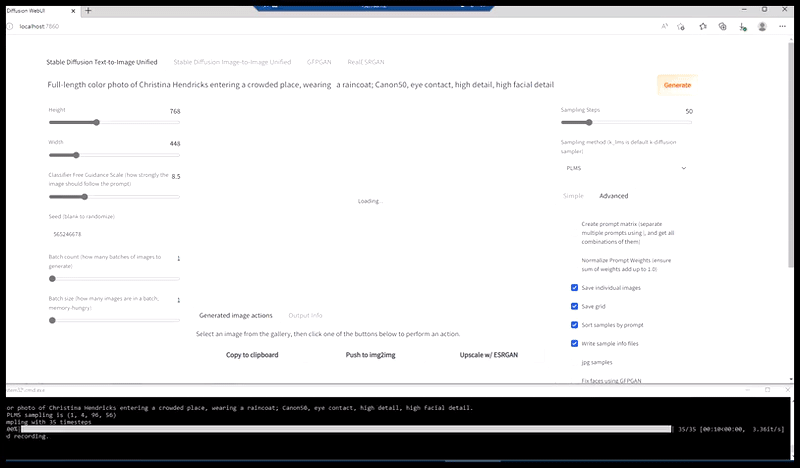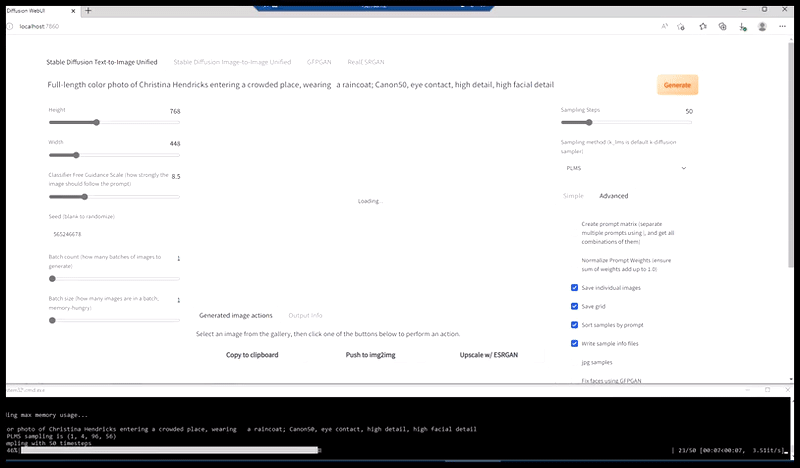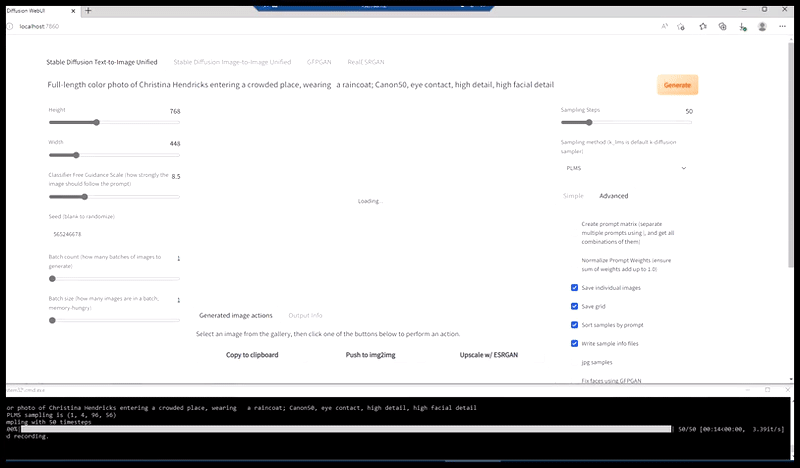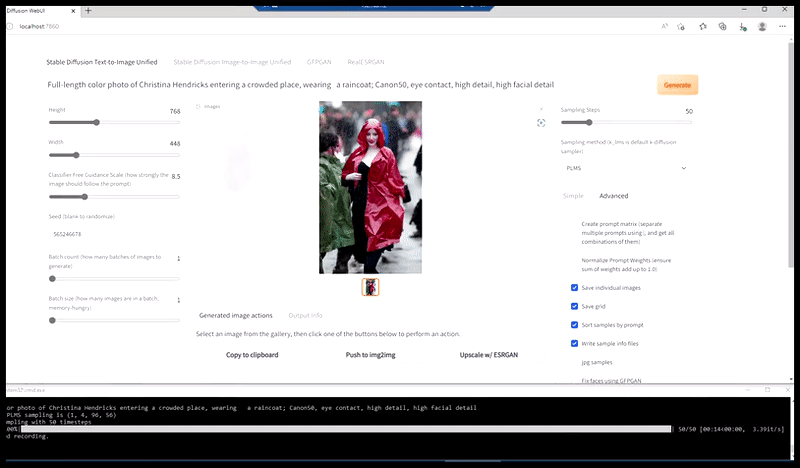
Генерация правдоподобной пресс-фотографии с подсказкой «Полная цветная фотография Кристины Хендрикс, входящей в многолюдное место, одетой в пальто; Canon50, зрительный контакт, высокий уровень детализации, высокий уровень детализации лица».
Для знаменитостей с длинными и устойчивыми карьерами Stable Diffusion обычно генерирует изображение человека в недавнем (т.е. старшем) возрасте, и будет необходимо добавить подсказки, такие как «молодой» или «в году [ГОД]», чтобы произвести более молодые изображения.

С актерской карьерой, охватывающей почти 40 лет, Дженнифер Коннелли является одной из немногих знаменитостей в LAION, которые позволяют Stable Diffusion представить диапазон возрастов. Источник: prepack Stable Diffusion, локальный, v1.4 контрольная точка; возрастные подсказки.
Это в основном из-за распространения цифровой (а не дорогой, эмульсионной) пресс-фотографии с середины 2000-х годов и последующего роста объема изображений из-за увеличения скоростей широкополосного доступа.
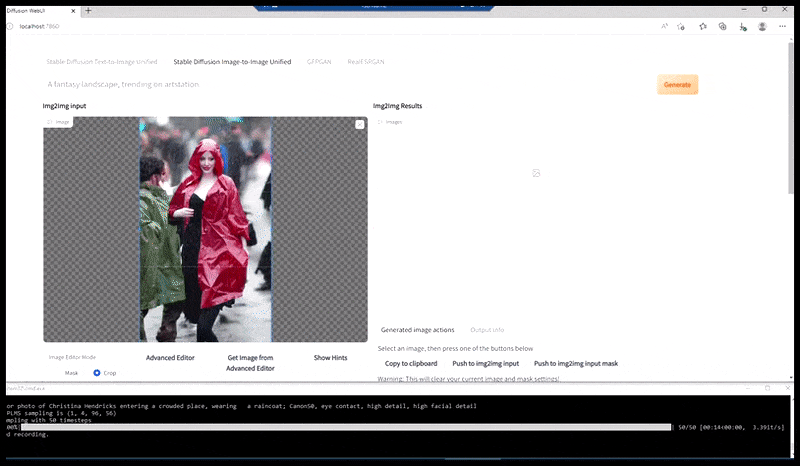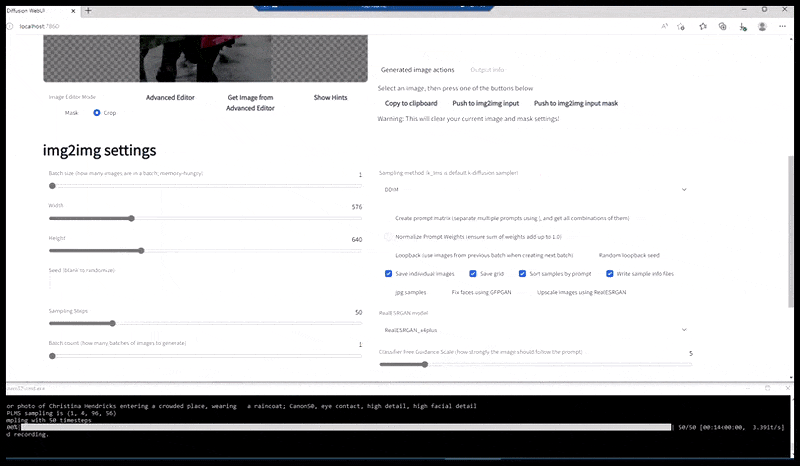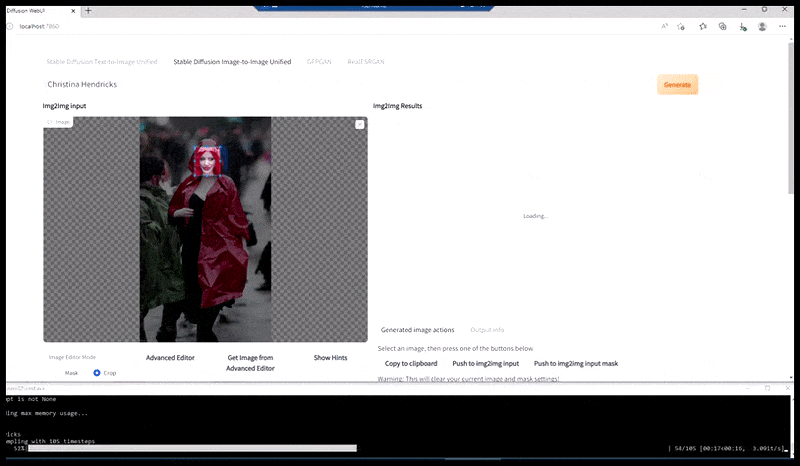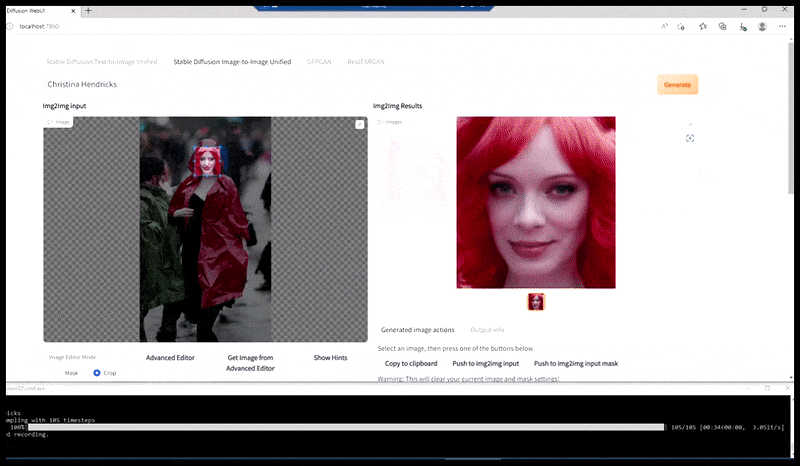
Рендеренное изображение передается в Img2Img в Stable Diffusion, где выбирается «фокус-область», и создается новый рендер максимального размера только для этой области, позволяя Stable Diffusion сосредоточить все доступные ресурсы на воссоздании лица.
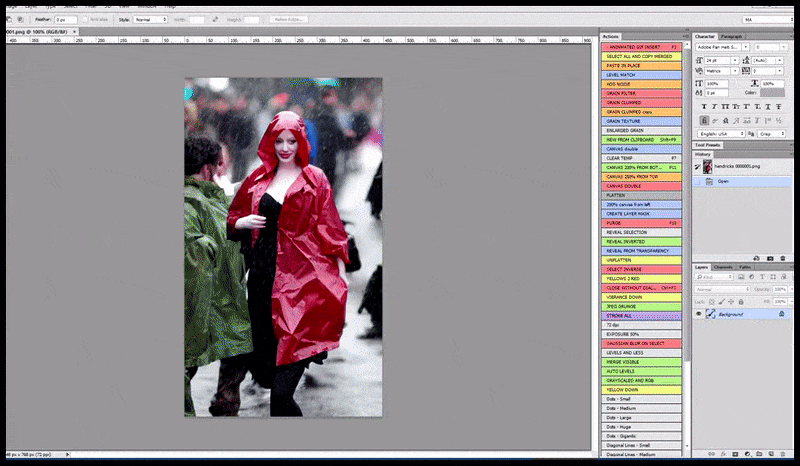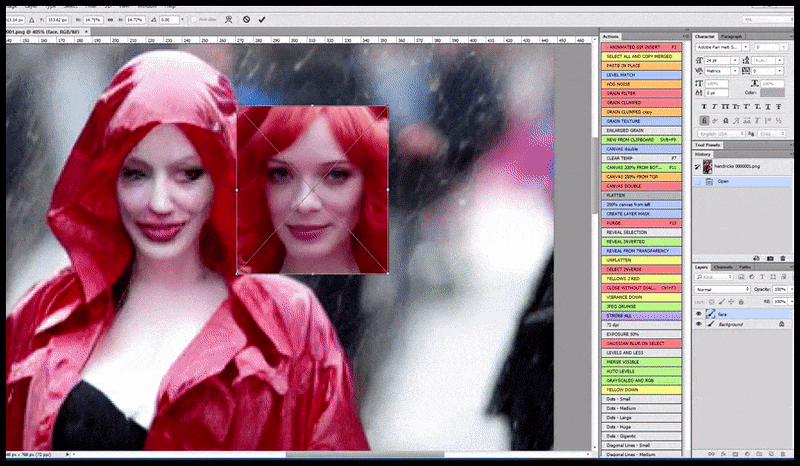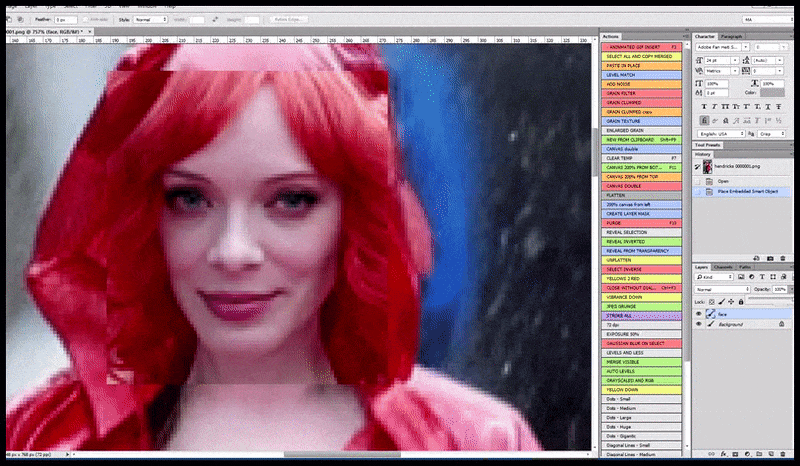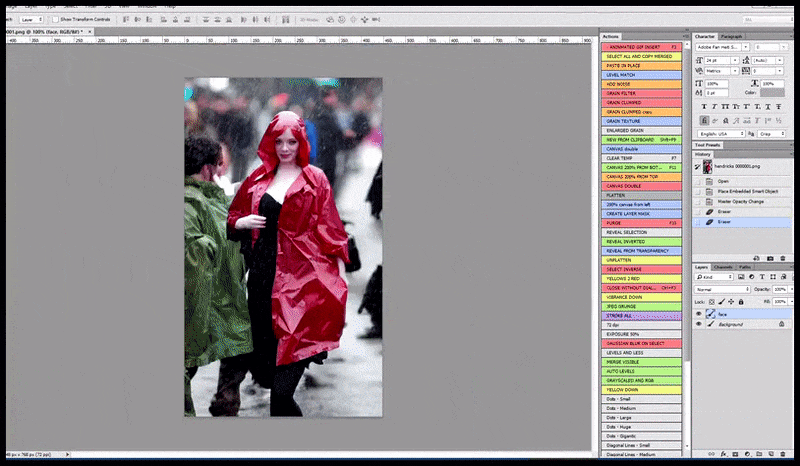
Композит «лица с высоким вниманием» обратно в исходный рендер. Кроме лиц, этот процесс будет работать только с объектами, которые имеют потенциально известный, сплоченный и целостный вид, такой как часть исходной фотографии, которая имеет отдельный объект, такой как часы или машина. Увеличение секции – например, стены – приведет к очень странно выглядящей собранной стене, потому что рендеры плиток не имели более широкого контекста для этой «пазла» при рендеринге.
Некоторые знаменитости в базе данных приходят «замороженными» во времени, либо потому, что они умерли рано (например, Мэрилин Монро), либо поднялись только на короткий период времени, производя большое количество изображений в ограниченный период времени. Опрос Stable Diffusion, можно сказать, предоставляет своего рода «текущий» индекс популярности для современных и старых звезд. Для некоторых старых и современных знаменитостей нет достаточно изображений в исходных данных, чтобы получить очень хорошее сходство, в то время как устойчивая популярность определенных долгоживущих или иначе угасающих звезд обеспечивает, что их разумное сходство может быть получено из системы.

Рендеры Stable Diffusion быстро показывают, какие знаменитые лица хорошо представлены в обучающих данных. Несмотря на свою огромную популярность как старшего подростка на момент написания, Милли Бобби Браун была моложе и менее известна, когда исходные наборы данных LAION были соскоблены из сети, что делает высококачественное сходство с Stable Diffusion проблематичным на данный момент.
Где данные доступны, решения на основе плиток для Stable Diffusion могли бы пойти дальше, чем сосредоточение внимания на лице: они потенциально могли бы позволить создать еще более точные и детальные лица, разбивая черты лица на отдельные части и направляя всю силу локальных ресурсов GPU на отдельные части, прежде чем собрать их вместе – процесс, который в настоящее время является ручным.

Это не ограничивается лицами, но ограничено частями объектов, которые, по крайней мере, так же предсказуемо расположены в более широком контексте объекта и соответствуют высокоуровневым вложениям, которые можно было бы разумно ожидать в гипермасштабном наборе данных.
Настоящий предел – это количество доступных справочных данных в наборе данных, потому что, в конечном итоге, глубоко итерированные детали станут полностью «галлюцинированными» (т.е. вымышленными) и менее аутентичными.
Такие высокоуровневые гранулярные увеличения работают в случае Дженнифер Коннелли, потому что она хорошо представлена в различных возрастах в LAION-aesthetics (основном подмножестве LAION 5B, которое использует Stable Diffusion); в многих других случаях точность будет страдать из-за нехватки данных, что потребует либо дообучения (дополнительного обучения, см. «Настройка» ниже), либо Textual Inversion (см. ниже).
Плитки – это мощный и относительно дешевый способ для Stable Diffusion производить высокоразрешающий выход, но алгоритмическое увеличение плиток этого типа, если оно лишено некоторого рода более широкого, высокоуровневого механизма внимания, может не оправдать ожиданий на ряде типов контента.
2: Решение проблем с человеческими конечностями
Stable Diffusion не оправдывает своего названия, когда изображает сложность человеческих конечностей. Руки могут умножаться случайным образом, пальцы сливаются, появляются три ноги без предупреждения, и существующие конечности исчезают без следа. В его защиту, Stable Diffusion разделяет эту проблему со своими стабильными аналогами, и, безусловно, с DALL-E 2.

Неотредактированные результаты DALL-E 2 и Stable Diffusion (1.4) в конце августа 2022 года, оба показывающие проблемы с конечностями. Подсказка: «Женщина обнимает мужчину»
Поклонники Stable Diffusion, надеющиеся, что предстоящая контрольная точка 1.5 (более интенсивно обученная версия модели с улучшенными параметрами) решит проблему с конечностями, вероятно, будут разочарованы. Новая модель, которая будет выпущена через примерно две недели, в настоящее время представлена на коммерческом портале stability.ai DreamStudio, который использует 1.5 по умолчанию, и где пользователи могут сравнить новый выход с рендерами из своих локальных или других систем 1.4:

Источник: локальный 1.4 prepack и https://beta.dreamstudio.ai/

Источник: локальный 1.4 prepack и https://beta.dreamstudio.ai/

Источник: локальный 1.4 prepack и https://beta.dreamstudio.ai/
Как часто бывает, качество данных может быть основной причиной.
Открытые базы данных, которые обеспечивают синтез изображений, такие как Stable Diffusion и DALL-E 2, могут предоставить многие метки для отдельных людей и межличностных действий. Эти метки обучаются симбиотически с их связанными изображениями или сегментами изображений.

Пользователи Stable Diffusion могут исследовать понятия, обученные в модели, запросив подмножество LAION-aesthetics, подмножество более крупного набора данных LAION 5B, который обеспечивает систему. Изображения упорядочены не по их алфавитным меткам, а по их «эстетическому баллу». Источник: https://rom1504.github.io/clip-retrieval/
Хорошая иерархия индивидуальных меток и классов, способствующих изображению человеческой руки, будет чем-то вроде тело>рука>рука>пальцы>[подпальцы + большой палец]>[сегменты пальцев]>ногти.

Гранулярная семантическая сегментация частей руки. Даже эта необычно подробная деконструкция оставляет каждый «палец» как единую сущность, не учитывая три сегмента пальца и два сегмента большого пальца. Источник: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
В реальности исходные изображения вряд ли будут так последовательно аннотированы на протяжении всего набора данных, и алгоритмы аннотации без надзора, вероятно, остановятся на более высоком уровне – например, «рука» – и оставят внутренние пиксели (которые технически содержат информацию о «пальцах») как неаннотированную массу пикселей, из которых будут произвольно получены признаки, и которые могут проявиться в последующих рендерах как резкий элемент.

Как это должно быть (вверху справа, если не вверх-резать), и как это склонно быть (внизу справа), из-за ограниченных ресурсов для аннотации или архитектурной эксплуатации таких меток, если они существуют в наборе данных.
Таким образом, если модель латентного распространения доберется до рендера руки, она, скорее всего, попытается также отрендерить руку в конце этой руки, потому что рука>рука является минимально необходимой иерархией, довольно высокой в том, что архитектура знает о «человеческой анатомии».
После этого «пальцы» могут быть самой маленькой группой, даже если есть 14 дальнейших подчастей пальцев/большого пальца, которые следует учитывать при изображении человеческих рук.
Если эта теория верна, то нет реального решения, из-за отраслевой нехватки бюджета на ручную аннотацию и отсутствия адекватно эффективных алгоритмов, которые могли бы автоматизировать аннотацию, производя низкие показатели ошибок. По сути, модель может в настоящее время полагаться на человеческую анатомическую последовательность, чтобы скрыть несовершенства набора данных, на котором она была обучена.
Одной из возможных причин, почему она не может полагаться на это, недавно предложено на Discord Stable Diffusion, является то, что модель может запутаться в правильном количестве пальцев, которое должна иметь человеческая рука (реалистичная), потому что база данных LAION, которая обеспечивает ее, содержит мультяшные персонажи, которые могут иметь меньше пальцев (что само по себе экономия труда).

Два потенциальных виновника в «потерянном пальце» синдроме в Stable Diffusion и аналогичных моделях. Ниже, примеры мультяшных рук из набора данных LAION-aesthetics, который обеспечивает Stable Diffusion. Источник: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Если это правда, то единственное очевидное решение – это переобучить модель, исключая нереалистичный контент, основанный на людях, обеспечивая, что подлинные случаи пропуска (т.е. ампутанты) правильно помечены как исключения. С точки зрения только кураторской обработки данных это будет довольно сложной задачей, особенно для общественных усилий с ограниченными ресурсами.
Второй подход будет заключаться в применении фильтров, которые исключают такой контент (т.е. «рука с тремя/пятью пальцами») из проявления во время рендера, аналогично тому, как OpenAI отфильтровал GPT-3 и DALL-E 2, чтобы их выход мог быть регулируемым без необходимости переобучать исходные модели.

Для Stable Diffusion семантическое различие между цифрами и даже конечностями может стать ужасно размытым, напоминая 1980-е «тело-хоррор»-фильмы от людей вроде Дэвида Кроненберга. Источник: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Однако снова это потребует меток, которые могут не существовать во всех затронутых изображениях, оставляя нас с той же логистической и бюджетной проблемой.
Можно утверждать, что есть два оставшихся пути вперед: бросание большего количества данных на проблему и применение сторонних интерпретативных систем, которые могут вмешаться, когда физические ошибки такого типа представляются конечному пользователю (по крайней мере, последнее даст OpenAI метод предоставления возвратов за «тело-хоррор»-рендеры, если компания будет мотивирована сделать это).
3: Настройка
Одной из наиболее интересных возможностей для будущего Stable Diffusion является перспектива пользователей или организаций разработки пересмотренных систем; модификаций, которые позволяют контенту вне предварительно обученного сферы LAION быть интегрированным в систему – идеально без неуправляемых расходов на повторное обучение всей модели или риска, связанного с обучением на большом объеме новых изображений к существующей, зрелой и способной модели.
По аналогии: если два менее одаренных студента присоединяются к продвинутому классу из тридцати студентов, они либо ассимилируются и догоняют, либо терпят неудачу как аутсайдеры; в любом случае средняя производительность класса, вероятно, не будет затронута. Если 15 менее одаренных студентов присоединятся, однако, кривая оценок для всего класса, вероятно, пострадает.
Аналогично, синергетическая и довольно хрупкая сеть отношений, которые строятся во время длительного и дорогого обучения модели, могут быть скомпрометированы, в некоторых случаях эффективно разрушены, избыточными новыми данными, снижая качество выхода модели в целом.
Основная причина для этого заключается в том, что ваш интерес лежит в полном уничтожении понимания модели концепций и вещей и присвоении ее исключительно для производства контента, подобного дополнительному материалу, который вы добавили.
Таким образом, обучение 500 000 кадров Симпсонов в существующую контрольную точку Stable Diffusion, вероятно, в конечном итоге даст вам лучший Симпсонов-симулятор, чем исходная сборка могла бы предложить, предполагая, что достаточно широкие семантические отношения выживут в процессе (т.е. Гомер Симпсон ест хот-дог, который может потребовать материала о хот-догах, который не был в вашем дополнительном материале, но уже существовал в контрольной точке), и предполагая, что вы не хотите внезапно переключиться от Симпсонов-контента на создание фантастических пейзажей Грега Рутковского – потому что ваша пост-обученная модель имела свое внимание сильно отвлечено, и не будет так хорошо выполнять эту задачу, как раньше.
Одним из заметных примеров этого является waifu-diffusion, который успешно обучил 56 000 аниме-изображений в завершенную и обученную контрольную точку Stable Diffusion. Это трудная перспектива для хобби, однако, поскольку модель требует минимума 30 ГБ видеопамяти, далеко за пределами того, что, вероятно, будет доступно на потребительском уровне в будущих выпусках серии 40XX от NVIDIA.

Обучение пользовательского контента в Stable Diffusion через waifu-diffusion: модель заняла две недели пост-обучения, чтобы вывести этот уровень иллюстрации. Шесть изображений слева показывают прогресс модели, по мере прохождения обучения, в создании предметно-сплоченного выхода на основе новых обучающих данных. Источник: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Текущая, и большая надежда на настройку Stable Diffusion – это Textual Inversion, где пользователь обучает небольшое количество CLIP-выровненных изображений.

Сотрудничество между Тель-Авивским университетом и NVIDIA, текстовая инверсия позволяет обучать отдельные и новые сущности, не разрушая способности исходной модели. Источник: https://textual-inversion.github.io/
Основным ограничением текстовой инверсии является то, что рекомендуется очень небольшое количество изображений – всего пять. Это эффективно производит ограниченную сущность, которая может быть более полезна для задач стиля, чем для вставки фотореалистичных объектов.
Тем не менее, эксперименты в настоящее время проводятся в различных сообществах Stable Diffusion, которые используют гораздо большее количество обучающих изображений, и остается быть увиденным, насколько продуктивным этот метод может оказаться. Снова, техника требует большого количества видеопамяти, времени и терпения.
Из-за этих ограничивающих факторов нам, возможно, придется подождать некоторое время, чтобы увидеть некоторые из более сложных экспериментов по текстовой инверсии от энтузиастов Stable Diffusion – и чтобы увидеть, сможет ли этот подход «вставить вас в картину» таким образом, который выглядит лучше, чем вставка в Photoshop, сохраняя при этом удивительную функциональность официальных контрольных точек.
Опубликовано впервые 6 сентября 2022 года.












