Искусственный интеллект
Первая годовщина ChatGPT: Переопределение будущего взаимодействия с ИИ

Вспоминая первый год ChatGPT, становится ясно, что этот инструмент существенно изменил сцену ИИ. Запущенный в конце 2022 года, ChatGPT выделялся своей удобной, разговорной стилем, который сделал взаимодействие с ИИ похожим на разговор с человеком, а не с машиной. Этот новый подход быстро привлёк внимание общественности. В течение пяти дней после выпуска ChatGPT уже привлёк миллион пользователей. К началу 2023 года это число увеличилось до примерно 100 миллионов пользователей в месяц, а к октябрю платформа привлекала около 1,7 миллиарда посетителей по всему миру. Эти цифры говорят о его популярности и полезности.
За прошлый год пользователи нашли все sorts of творческих способов использовать ChatGPT, от простых задач, таких как написание писем и обновление резюме, до создания успешных бизнесов. Но это не только о том, как люди используют его; сама технология выросла и улучшилась. Первоначально ChatGPT был бесплатной службой, предлагающей подробные текстовые ответы. Теперь есть ChatGPT Plus, который включает ChatGPT-4. Эта обновлённая версия обучена на большем количестве данных, даёт меньше неправильных ответов и лучше понимает сложные инструкции.
Одним из самых больших обновлений является то, что ChatGPT теперь может взаимодействовать несколькими способами – он может слушать, говорить и даже обрабатывать изображения. Это означает, что вы можете говорить с ним через его мобильное приложение и показывать ему картинки, чтобы получить ответы. Эти изменения открыли новые возможности для ИИ и изменили то, как люди воспринимают и думают о роли ИИ в нашей жизни.
От его начала как техдемонстрации до его текущего статуса как крупного игрока в мире технологий, путь ChatGPT довольно впечатляющий. Первоначально он рассматривался как способ протестировать и улучшить технологию, получая обратную связь от общественности. Но он быстро стал важной частью ландшафта ИИ. Этот успех показывает, насколько эффективно донастраивать большие языковые модели (LLM) с помощью как надзорного обучения, так и обратной связи от людей. В результате ChatGPT может справиться с широким спектром вопросов и задач.
Гонка за разработкой наиболее способных и универсальных систем ИИ привела к распространению как открытых, так и проприетарных моделей, подобных ChatGPT. Понимание их общих возможностей требует всесторонних тестов по широкому спектру задач. Этот раздел исследует эти тесты, проливая свет на то, как разные модели, включая ChatGPT, сравниваются друг с другом.
Оценка LLM: Тесты
- MT-Bench: Этот тест проверяет многоповоротный разговор и способность следовать инструкциям в восьми областях: написании, ролевой игре, извлечении информации, рассуждении, математике, программировании, знаниях STEM и гуманитарных/социальных науках. Более сильные LLM, такие как GPT-4, используются в качестве оценщиков.
- AlpacaEval: На основе набора оценки AlpacaFarm, этот LLM-основанный автоматический оценщик тестирования модели сравнивает их с ответами от продвинутых LLM, таких как GPT-4 и Claude, рассчитывая коэффициент победы моделей-кандидатов.
- Открытая таблица лидеров LLM: Используя Language Model Evaluation Harness, эта таблица лидеров оценивает LLM на семи ключевых тестах, включая задачи рассуждения и тесты общих знаний, в обоих нулевом и немногих выстрелах.
- BIG-bench: Этот совместный тест охватывает более 200 новых языковых задач, охватывающих широкий спектр тем и языков. Он направлен на то, чтобы проверить LLM и предсказать их будущие возможности.
- ChatEval: Многоагентная рамка дебатов, которая позволяет командам автономно обсуждать и оценивать качество ответов от разных моделей на открытые вопросы и традиционные задачи генерации естественного языка.
Сравнительная производительность
В плане общих тестов открытые LLM показали замечательный прогресс. Llama-2-70B, например, достигла впечатляющих результатов, особенно после донастройки с инструкционными данными. Её вариант, Llama-2-chat-70B, преуспел в AlpacaEval с коэффициентом победы 92,66%, превзойдя GPT-3.5-turbo. Однако GPT-4 остаётся лидером с коэффициентом победы 95,28%.
Zephyr-7B, более pequeña модель, продемонстрировала способности, сравнимые с более крупными 70B LLM, особенно в AlpacaEval и MT-Bench. Тем временем WizardLM-70B, донастроенная с разнообразным набором инструкционных данных, набрала наивысший балл среди открытых LLM на MT-Bench. Однако она всё ещё отстает от GPT-3.5-turbo и GPT-4.
Интересным входом является GodziLLa2-70B, который достиг конкурентоспособного балла на Открытой таблице лидеров LLM, демонстрируя потенциал экспериментальных моделей, объединяющих разнообразные наборы данных. Аналогично, Yi-34B, разработанная с нуля, выделилась с баллами, сравнимыми с GPT-3.5-turbo, и только немного отстающими от GPT-4.
UltraLlama, с её донастройкой на разнообразных и высококачественных данных, сравнялась с GPT-3.5-turbo в предложенных тестах и даже превзошла её в областях мировых и профессиональных знаний.
Масштабирование: Рост гигантских LLM
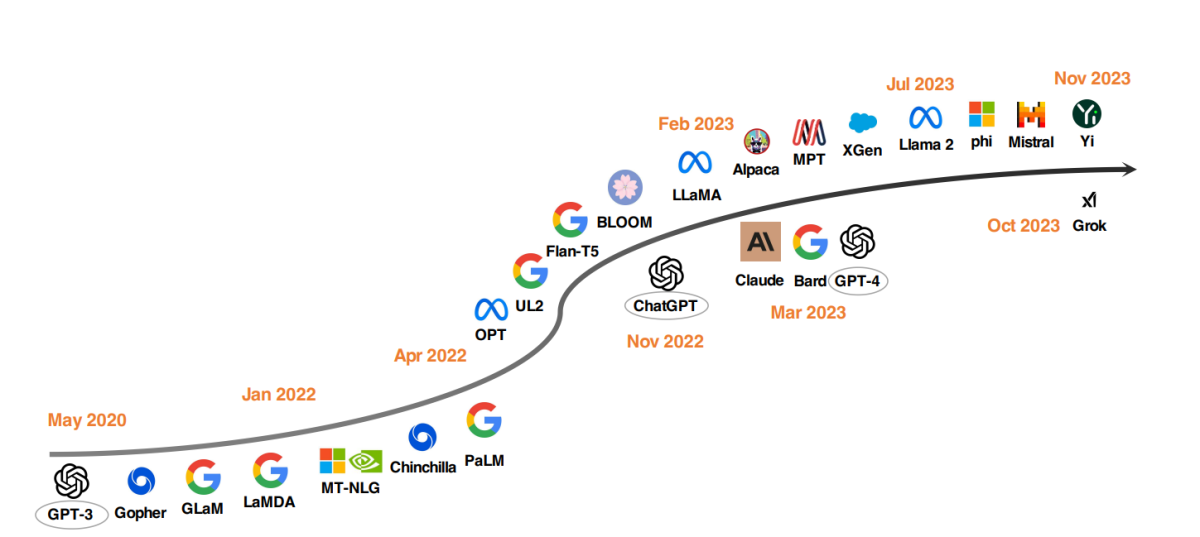
Топ-модели LLM с 2020 года
Заметной тенденцией в разработке LLM является масштабирование параметров модели. Модели, такие как Gopher, GLaM, LaMDA, MT-NLG и PaLM, расширили границы, в результате чего появились модели с до 540 миллиардов параметров. Эти модели показали исключительные способности, но их закрытый характер ограничил их более широкое применение. Это ограничение вызвало интерес к разработке открытых LLM, тенденция, которая набирает обороты.
Параллельно с масштабированием размеров моделей исследователи исследовали альтернативные стратегии. Вместо того, чтобы просто делать модели больше, они сосредоточились на улучшении предварительной подготовки меньших моделей. Примерами являются Chinchilla и UL2, которые показали, что больше не всегда лучше; более умные стратегии могут дать эффективные результаты. Кроме того, было значительное внимание к донастройке языковых моделей, с проектами, такими как FLAN, T0 и Flan-T5, которые внесли значительный вклад в эту область.
Катализатор ChatGPT
Введение OpenAI ChatGPT ознаменовало поворотный момент в исследованиях NLP. Чтобы конкурировать с OpenAI, компании, такие как Google и Anthropic, запустили свои собственные модели, Bard и Claude, соответственно. Хотя эти модели показывают сравнимую производительность с ChatGPT во многих задачах, они всё ещё отстают от последней модели OpenAI, GPT-4. Успех этих моделей в основном обусловлен техникой обучения с подкреплением от обратной связи человека (RLHF), которая получает всё больше исследовательского внимания для дальнейшего улучшения.
Слухи и спекуляции вокруг Q* (Q-Star) OpenAI
Недавние сообщения предполагают, что исследователи в OpenAI, возможно, достигли значительного прорыва в ИИ с разработкой новой модели под названием Q* (произносится как Q-звезда). Согласно сообщениям, Q* имеет возможность выполнять математические задачи начального уровня школы, что вызвало дискуссии среди экспертов о её потенциале как вехи на пути к искусственному общему интеллекту (AGI). Хотя OpenAI не прокомментировала эти сообщения, предполагаемые способности Q* вызвали значительный интерес и спекуляции в социальных сетях и среди энтузиастов ИИ.
Разработка Q* примечательна потому, что существующие языковые модели, такие как ChatGPT и GPT-4, хотя и способны выполнять некоторые математические задачи, не особенно адаптированы для этого. Вызов заключается в необходимости для моделей ИИ не только распознавать закономерности, как они делают сейчас с помощью глубокого обучения и трансформеров, но и рассуждать и понимать абстрактные понятия. Математика, будучи эталоном для рассуждений, требует от ИИ планировать и выполнять несколько шагов, демонстрируя глубокое понимание абстрактных понятий. Эта способность будет означать значительный скачок в возможностях ИИ, потенциально выходящий за рамки математики и распространяющийся на другие сложные задачи.
Однако эксперты предостерегают от чрезмерного энтузиазма по поводу этого развития. Хотя система ИИ, которая надёжно решает математические задачи, будет впечатляющим достижением, она не обязательно сигнализирует о начале сверхинтеллектуального ИИ или AGI. Текущие исследования ИИ, включая усилия OpenAI, были сосредоточены на элементарных проблемах, с различными степенями успеха в более сложных задачах.
Потенциальные применения, таких как прорывы, огромны, варьируются от персонализированного обучения до помощи в научных исследованиях и инженерии. Однако важно управлять ожиданиями и признавать ограничения и проблемы безопасности, связанные с такими прорывами. Заботы об ИИ, представляющем существенные риски, фундаментальная проблема OpenAI, остаются актуальными, особенно когда системы ИИ начинают взаимодействовать с реальным миром более тесно.
Движение открытых LLM
Чтобы стимулировать исследования открытых LLM, Meta выпустила серию моделей Llama, что вызвало волну новых разработок на основе Llama. Это включает модели, донастроенные с инструкционными данными, такими как Alpaca, Vicuna, Lima и WizardLM. Исследования также ветвятся в сторону улучшения возможностей агентов, логического рассуждения и моделирования длинного контекста в рамках Llama-основанной структуры.
Кроме того, есть растущая тенденция разработки мощных LLM с нуля, с проектами, такими как MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok и Yi. Эти усилия отражают приверженность демократизации возможностей закрытых LLM, делая продвинутые инструменты ИИ более доступными и эффективными.
Влияние ChatGPT и открытых моделей на здравоохранение
Мы смотрим в будущее, где LLM помогают в клинической записи, заполнении форм для возмещения, и поддержке врачей в диагностике и планировании лечения. Это привлекло внимание как технологических гигантов, так и учреждений здравоохранения.
Обсуждения Microsoft с Epic, ведущим поставщиком программного обеспечения для электронных медицинских записей, сигнализируют об интеграции LLM в здравоохранение. Инициативы уже реализуются в UC San Diego Health и Stanford University Medical Center. Аналогично, партнёрство Google с Mayo Clinic и запуск Amazon Web Services HealthScribe, AI-сервиса клинической документации, отмечают значительные шаги в этом направлении.
Однако эти быстрые развертывания вызывают опасения по поводу передачи контроля над медициной корпоративным интересам. Проприетарный характер этих LLM делает их трудными для оценки. Их возможная модификация или прекращение из-за прибыли может поставить под угрозу уход за пациентами, конфиденциальность и безопасность.
Срочная необходимость заключается в открытом и инклюзивном подходе к разработке LLM для здравоохранения. Учреждения здравоохранения, исследователи, клиницисты и пациенты должны сотрудничать глобально, чтобы создать открытые LLM для здравоохранения. Этот подход, аналогичный Trillion Parameter Consortium, позволит объединить вычислительные, финансовые ресурсы и экспертизу.












